Linux内核学习笔记之块I/O层
设备的分类
设备可以分为两类:
- 块设备:能够随机访问固定大小数据片(chunks)的硬件设备。如硬盘。
- 字符设备:按照字符流有序访问的硬件设备。如键盘、串口。
比如键盘,系统只能以有序的流方式读取键盘输入h-e-l-l-o,如果随机访问e-l-o-h-o,则这些输入的字符就没有意义了。
剖析一个块设备
块设备中最小的可寻址单元是扇区(sector)。扇区大小一般是 2 的整数倍,而最常见的是 512 字节。扇区的大小是设备的物理属性,扇区是所有块设备的基本单元。
虽然物理磁盘寻址是按照扇区级进行的,但是内核执行的所有磁盘操作都是按照块(block) 进行的。由于扇区是设备的最小可寻址单元,所以块不能比扇区还小,只能数倍于扇区大小。具体要求是必须是扇区大小的 2 的整数倍,并且要小于页面大小(估计是为了用页缓存方便)。所以通常块大小是 512 字节、1KB 或 4KB。
bio 结构体
bio 结构体用于管理一片缓冲区,缓冲区用于实现块 I/O 请求操作。缓冲区由多个片段(segment) 构成,片段通过链表连接。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
// include/linux/blk_types.h
struct bio
{
sector_t bi_sector; /* device address in 512 byte sectors */
struct bio *bi_next; /* request queue link */
struct block_device *bi_bdev; // 关联的块设备
unsigned long bi_flags; /* status, command, etc */
unsigned long bi_rw; /* bottom bits READ/WRITE,
* top bits priority
*/
unsigned short bi_vcnt; /* bio链表节点数,how many bio_vec's */
unsigned short bi_idx; /* bio链表当前指针,current index into bvl_vec */
/* Number of segments in this BIO after
* physical address coalescing is performed.
*/
unsigned int bi_phys_segments;
unsigned int bi_size; /* residual I/O count */
/*
* To keep track of the max segment size, we account for the
* sizes of the first and last mergeable segments in this bio.
*/
unsigned int bi_seg_front_size;
unsigned int bi_seg_back_size;
bio_end_io_t *bi_end_io;
void *bi_private;
#ifdef CONFIG_BLK_CGROUP
/*
* Optional ioc and css associated with this bio. Put on bio
* release. Read comment on top of bio_associate_current().
*/
struct io_context *bi_ioc;
struct cgroup_subsys_state *bi_css;
#endif
#if defined(CONFIG_BLK_DEV_INTEGRITY)
struct bio_integrity_payload *bi_integrity; /* data integrity */
#endif
/*
* Everything starting with bi_max_vecs will be preserved by bio_reset()
*/
unsigned int bi_max_vecs; /* max bvl_vecs we can hold */
atomic_t bi_cnt; /* 使用记数,为0时析构本对象。pin count */
struct bio_vec *bi_io_vec; /* bio链表 the actual vec list */
struct bio_set *bi_pool;
/*
* We can inline a number of vecs at the end of the bio, to avoid
* double allocations for a small number of bio_vecs. This member
* MUST obviously be kept at the very end of the bio.
*/
struct bio_vec bi_inline_vecs[0];
};
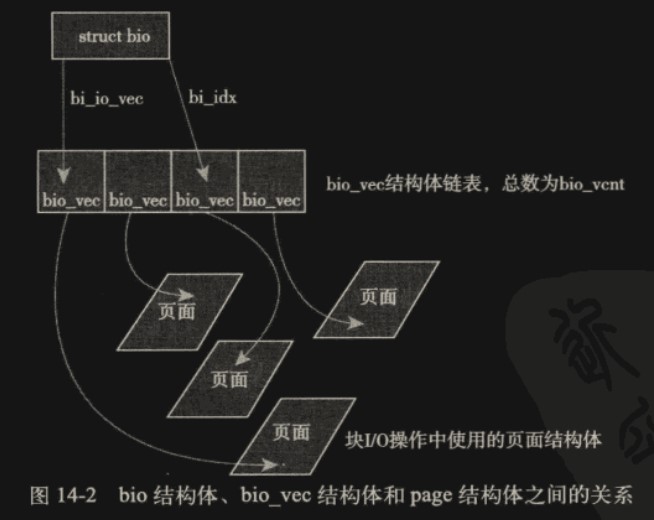
I/O 向量 bi_io_vec
bi_io_vec 成员是一个基于链表的向量(变长数组),指向了整个虚拟的缓冲区。链表内每个节点都是 struct bio_vec 结构,描述了缓冲区片段的信息。链表节点数为 bi_vcnt,当前索引为 bi_idx。
1
2
3
4
5
6
7
8
9
10
// include/linux/blk_types.h
struct bio_vec
{
// 片段所在的物理页(用page而不是地址就能使用高端内存)
struct page *bv_page;
// 片段大小
unsigned int bv_len;
// 片段所在物理页内偏移(如果一个片段就是一页大小可能就不用偏移)
unsigned int bv_offset;
};
每一个块 I/O 请求都通过一个 bio 结构体表示。每个请求包含一个或多个块(要求块连续,后面会提到不同请求可以合并,变成更大的连续块),这些块存储在bi_io_vec向量中。bi_io_vec向量表示的缓冲区在逻辑上连续,实际上会由 bio_vec 节点指向各个分散的物理页。
I/O 请求队列
块设备将它们挂起的块 I/O 请求保存在请求队列中,该队列由 reques_queue 结构体表示,定义在文件<linux/blkdev.h>中,包含一个双向请求链表以及相关控制信息。链表内每个单独的请求用 request 结构体表示。
块设备驱动程序会从队列头获取请求,然后将其送入对应的块设备上去。
I/O 调度程序
如果把每个 I/O 请求都直接往请求队列里塞,那最终执行的效率会很差,因为更多的 I/O 次数意味着更多次的磁盘寻址,这是最慢的部分(针对机械硬盘而言)。
内核通过 I/O 调度程序整理排序 I/O 请求,已达到更优的性能。
I/O 调度程序的工作
I/O 调度程序的工作是管理块设备的请求队列。
I/O 调度程序通过两种方法减少磁盘寻址时间:合并与排序。
合并:将两个或多个请求结合成一个新请求。比如队列中有两个请求访问的块区间相邻或相交,则可以合并为一个请求,只需一次寻址操作。
举个例子,修改文件时先提交了第一部分,紧接着提交了连续的第二部分,这是两次请求,但完全可以合并成一次请求。
排序:针对机械硬盘的寻道操作(磁头移动),将请求排序,让磁头朝一个方向移动(如从内环向外环移动)。这叫电梯调度算法,电梯不会跳来跳去,总是先向上到顶再向下到底这样循环。当然随着内核更新,现在会有更好的排序策略和算法。
Linux 电梯调度算法
向队列插入一个新的请求时的四种情况:
- 如果队列中已存在一个对相邻磁盘扇区操作的请求,那么新请求将和这个已经存在的请求合并成一个请求。
- 如果队列中存在一个驻留时间过长的请求,那么新请求将被插入到队列尾部,以防止其它旧的请求饥饿。(这条是属于对电梯算法的优化)
- 如果队列中以扇区方向为序存在合适的插入位置,那么新的请求将被插入到该位置,保证队列中的请求是以被访问磁盘物理位置为序进行排列的。
- 如果队列中不存在合适的请求插和位置,请求将被插入到队列尾部。
现代的 flash 固态硬盘已经没有磁道的概念了,电梯算法可能并不适用
最终期限 I/O 调度算法
最终期限(deadline)I/O 调度程序是为了解决 Linus 电梯所带来的问题而提出的。
电梯算法有两个问题:
- 不公平:电梯调度算法是为吞吐量优化的,很容易造成不公平。比如一个请求在最外环,而之后不停有新请求符合合并或排序条件而插队导致电梯移动缓慢,导致其可能饿死;如果新请求正好在和磁头移动相反的方向,则必须等电梯到底回来才能执行到,也可能饿死。
- 未区分读写请求:一般来讲,读操作比写操作更加重要,因为读一般是同步的,应用程序希望立刻获取数据以执行后续步骤并阻塞等待,而写操作一般可以异步执行。读操作还有相互依赖性,比如读一个文件要先读 inode,总读取时间其实是这两个相加。
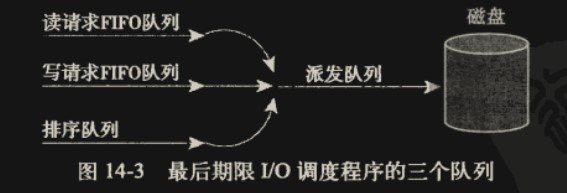
最终期限 I/O 调度算法有 3 个队列:读请求 FIFO 队列,写请求 FIFO 队列,排序队列
新请求来时,按照电梯算法加入排序队列,同时根据读/写类型加入对应的读/写请求 FIFO 队列。正常情况下,每次取请求时从排序队列取第一个请求并执行(推入派发队列);如果取请求时检测到读/写请求 FIFO 队列有超时请求,则优先选超时的请求执行(读请求超时 500ms,写请求超时 5s,因为是 FIFO 队列,只要判断队首的超时即可)。
实现在 block/deadline-iosched.c
预测 I/O 调度算法
最终期限 I/O 调度算法为了公平和读请求的优先性牺牲了一部分的吞吐量。
预测 I/O 调度算法:基于最终期限算法,当执行完读请求后,有意等待一段时间(6ms),此时新来的请求不再加入任何队列,而是直接判断它是否和刚执行完的读请求相邻,如果相邻直接执行该请求。这样做的好处是防止加入排序队列后正好错过执行时机(磁头正好往外环走,而新请求正好在磁头的相邻的内环),如果这样错过的请求变多,超时也会越来越频繁。
预测 I/O 调度算法是等待时间,根据各个应用的特性预测不同的等待时间才能真正提高性能,但正确预测没那么简单。
预测 I/O 调度算法的实现在文件内核源代码树的(现在好像没了),对大多数工作负荷来说都执行良好,对服务器也是理想的。不过,在某些非常见而又有严格工作负荷的服务器(包括数据库挖掘服务器)上,这个调度程序执行的效果不好。block/as-iosched.c中,它是 Linux 内核中缺省的 I/O 调度程序
完全公正的排队 I/O 调度程序
之前提到的算法都是基于电梯算法做的优化,注重通过排序提高吞吐量。完全公正的排队 I/O 调度有本质不同。
完全公正的排队 IO 调度程序(CompleteFairQueuing,CFQ)为每个进程分配一个队列,新请求加入对应进程的队列,队列内使用合并和排序,和之前的一样。
CFQ I/O 调度程序以时间片轮转调度队列,从每个队列中选取一定数量的请求,然后进行下一轮调度。基于时间片,让每个进程在时间上都公平的享有 I/O 带宽。
代码位于 block/cfq-iosched.c
空操作的 I/O 调度程序
空操作(Noop)就是不做合并排序之类操作,直接按照 FIFO 填入送出请求。因为现代的 flash 介质存储可以实现真正的随机访问,不需要考虑磁道和磁头的移动,合并排序没有太大意义。
代码位于 block/noop-iosched.c