Linux内核学习笔记之内核数据结构
链表
内核提供的标准链表可用于将任何类型的数据结构彼此链接起来。很明确,它不是类型安全的。 加入链表的数据结构必须包含一个类型为 list_head 的成员,其中包含了正向和反向指针。
list.h:
1
2
3
struct list_head {
struct list_head *next, *prev;
};
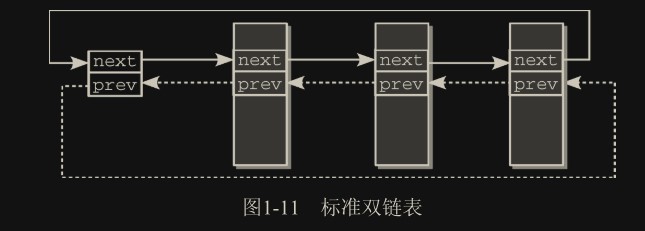
上图是一个首尾相连的环形双向链表。这是 Linux 标准链表。
如果第一个 prev 指向 NULL,最后个 next 指向 NULL,则是一个
线性双向链表。同理,如果 prev 或 next 全为 NULL,则是一个环形性单向链表。
使用方法如下:
1
2
3
4
5
6
7
8
9
10
struct test_struct {
int value;
struct list_head mylist;
}
struct test_struct[10];
struct test_struct *test_struct_head = &test_struct[0];
test_struct_head->mylist.next = &test_struct[2]
test_struct_head->mylist.prev = &test_struct[5]
...
这样就能创建一个包含 value 值的双向链表了,如果想把 value 放到两条不同的链上,往 test_struct 里再放一个 list_head 就行了
使用双向环形链表的好处是可以从任意一个节点开始正向或反向遍历整个链表,并没有首尾的概念。
操作链表
增加一个节点
向指定节点后插入一个新节点
1
list_add(struct list_head *new, struct list_head *head)
插入一个新节点,和 list_add 相反:
1
list_add_tail(struct list_head *new, struct List_head *head)
删除一个节点
1
liet_del(struct list_head *entry)
只需要一个节点指针作为参数。该操作不会释放 entry 及包含 entry 的结构体的内存,仅仅是将节点从链表中分离。
移动节点
1
list_move(struct list_head *list, struct list_head *head)
该函数从一个链表中移除 list 项,然后将其加入到另一链表的 head 节点后面。
1
list_move_tail(struct list_head *list, struct list_head *head)
和 list_move 相反。
判空
1
list_empty(struct list_head *head)
为空返回非 0 值。
合并链表
1
list_splice(struct list_head *list,struct list_head *head)
该函数合并两个链表,它将 list 指向的链表的每个节点插入到指定链表的 head 元素后面(不会修改 list 链表本身)。
1
list_splice_init(struct list_head *list,struct list_head *head)
和 list_splice 相同,只是会在合并完成后初始化 list,相当于删除了原链表
遍历链表
遍历 list_head 对象
1
list_for_each(ptr, head)
1
2
3
4
5
6
7
struct list_head *p;
struct fox *f;
list_for_each(p, &fox_list) {
// 如果需要找到节点对象,需要通过list_entry宏获取节点对象,f 指向节点对象
// list_entry依赖于container_of,下一节有说明
f = list_entry(p, struct fox, list)
}
遍历节点对象
1
list_for_each_entry(ptr, head, member)
其实就是上面的 list_for_each 和 list_entry 进行结合
1
2
3
4
5
struct fox *f;
// 通过list_for_each_entry直接遍历所有节点对象而非list_head对象
list_for_each_entry(f, &fox_list, list){
...
}
找到 list_head 对应的结构体
list_head 位于自定义的结构体内,而链表只是连接 list_head 实例,怎么通过该实例找到对应的自定义结构的地址?(就是上例中 f 的地址)
#define container_of(ptr, type, member) ({ \ const typeof(((type *)0)->member) *__mptr = (ptr); \ (type *)((char *)__mptr - offsetof(type, member));}) #define offsetof(TYPE, MEMBER) ((size_t)&((TYPE *)0)->MEMBER)如上,利用了结构体内数据在内存上的连续性,可以直接计算成员变量的偏移。这里利用了 0 指针,强制转为对应 type 类型,此时就在 0 地址上虚构了一个该结构体,然后用 offsetof 计算对应成员相对于结构体地址的
偏移量。位于不同位置的结构体的成员的偏移都是相同的,知道成员的地址就能用 container_of 反推结构体的实际地址。
反向遍历链表
如果明确知道想要查找的对象靠近链表尾部,使用反向遍历能带来更好的性能
1
list_for_each_entry_reverse(ptr, head, member)
遍历的同时删除
一般遍历链表时是不允许删除的,这会打断取 next 指针的操作。可以自己手动保存 next 指针实现遍历时删除,Linux 也提供了该操作的封装。
1
list_for_each_entry_safe(ptr, next, head, member)
散列表
1
2
3
4
5
6
7
struct hlist_head {
// 不需要保存尾部指针,通常对散列表来说都是从头遍历
struct hlist_node *first;
};
struct hlist_node {
struct hlist_node *next, **pprev;
};
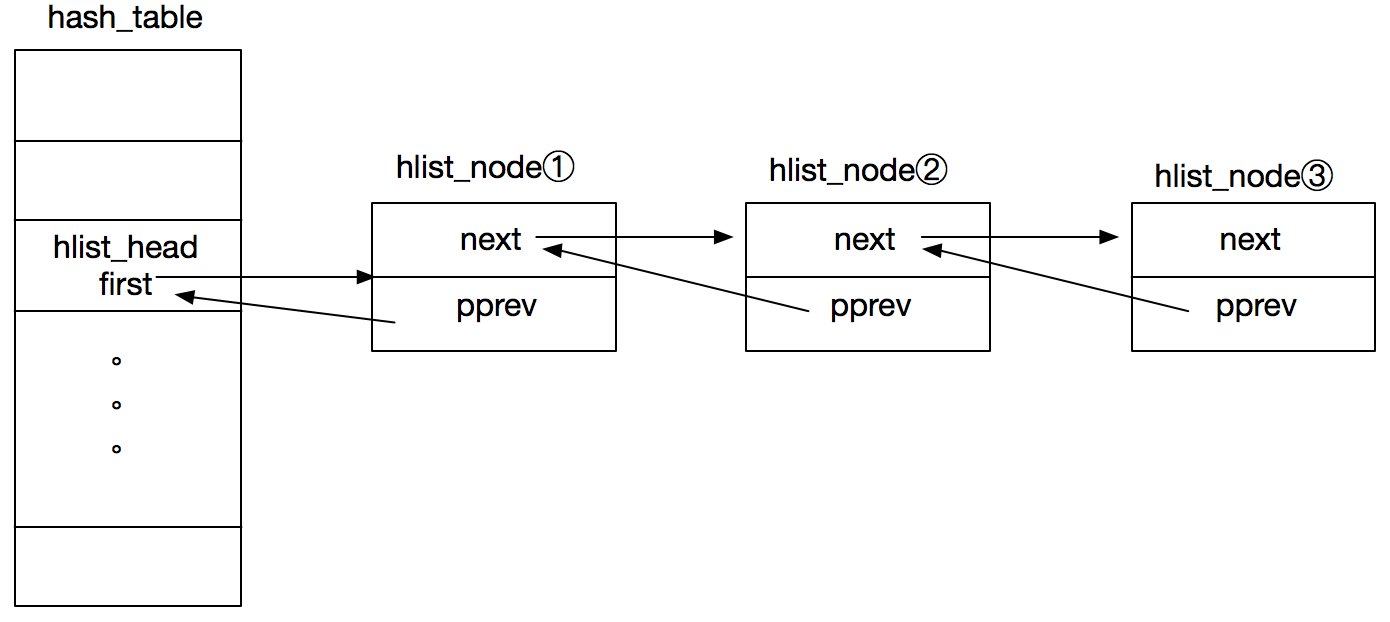
hlist_head 中的 first 元素指向链表头元素,也就是第一个 hlist_node。pprev 表示上一个 hlist_node 的 next 指针的引用(指向指针的指针),第一个 hlist_node 元素比较特殊,它的的 pprev 指向 first 指针(first 指针也是 hlist_node 类型的,可以用 pprev 指向)
为什么使用 hlist_head 结构体而非 hlist_node 指针表示
头节点的引用:答:其实 hlist_head 里的 first 指针就是
头节点的引用,封装一层看上去更直观(指针数组看上去总比结构体数组复杂)。为什么使用 hlist_head 结构体而不是 hlist_node 结构体:
答:如果用 hlist_node 结构体,那里面的 pprev 指针就没什么用了,因为散列表因为每个链表都比较短,直接是从头遍历的,不需要尾部指针。总之就是 hlist_head 比 hlist_node
省一个指针的空间为什么使用 pprev 指针而非 prev 指针:
答:如果需要删除头节点(第一个 hlist_node),使用 pprev 这个
指向指针的指针则可以让头节点能够直接修改 first 指针,否则还必须知晓 first 指针的位置才能对它做修改(也就是说如果用 hlist_node 作为首指针的存储体就不会有这个问题,可以用 prev 直接指向这个结构体,但上面第 2 点提到了为了省一个指针需要用 hlist_head)。
要按上图定义一个哈希表如下,也就是一个双向链表数组:
1
struct hlist_head hash_table[10];
队列
kfifo
Linux 是使用 kfifo 实现先进先出队列
包含一个入口偏移和出口偏移,两者相等时表示队列为空
创建队列
1
int kfifo_alloc(struct kfifo *fifo, unsigned int size, size_t esize, gfp_t gfp_mask);
该函数创建并且初始化一个大小为 size 的 kfifo。内核使用 gfp_mask 标识分配队列
如果想自己分配缓冲,可以调用:
1
void kfifo_init(struct kfifo *fifo, void *buffer, unsigned int size)
该函数创建并初始化一个 kfifo 对象,它将使用由 buffer 指向的 size 字节大小的内存。
对于 kfifo_alloc()和 kfifo_init(),size 必须为 2 的幂
推入队列数据
1
unsigned int kfifo_in(struct kfifo *fifo, const void *from, unsigned int len);
该函数把 from 指针所指的 len 字节数据拷贝到 fifo 所指的队列中,如果成功,则返回推入数据的字节大小。
TODO:可能会小于 len,不知道怎么解决只拷贝了一半的问题
摘取队列数据
读取并推出:
1
unsigned int kfifo_out(struct kfifo *fifo, void *to, unsigned int len);
读取但不推出:
1
unsigned int kfifo_out_peek(struct kfifo *fifo, void *to, unsigned int len, unsigned offset);
参数 offset 指向队列中的索引位置,如果该参数为 0,则读队列头,这和 kfifo_out()无异。
获取队列长度
总空间:
1
static inline unsigned int kfifo_size(struct kfifo *fifo)
已使用空间:
1
static inline unsigned int kfifo_len(struct kfifo *fifo);
可用空间:
1
static inline unsigned int kfifo_avail(struct kfifo *fifo);
判空和判满:
1
2
static inline int kfifo_is_empty(struct kfifo *fifo);// return not 0 if empty
static inline int kfifo_is_full(struct kfifo *fifo);
重置和销毁队列
重置:
1
static inline void kfifo_reset(struct kfifo *fifo);
销毁:
1
void kfifo_free(struct kfifo *fifo);
如果是使用 kfifo_init 创建的话,需要程序员手动管理创建时带入的缓冲区
队列使用举例
1
2
3
4
unsigned int i;
// 将 [0,32) 压入队列
for (i = 0;i<32,i++)
kfifo_in(fifo, &i, sizeof(i))
映射
一个映射,也常称为关联数组,其实是一个由唯一键组成的集合,而每个键必然关联一个特定的值。这种键到值的关联关系称为映射。
映射要至少支持三个操作:
- Add(key, value)
- Remove(key)
- value = Lookup(key)
实现方式:
散列表
更好的平均的渐近复杂度(线性复杂性)
自平衡二叉搜索树(AVL)
如 C++ STL 库中的 std:map,特点是按序遍历有更好性能,且最坏条件比散列表表现好(对数复杂性)
Linux 内核提供了简单、有效的映射数据结构。但是它并非一个通用的映射。因为它的目标是:映射一个唯一的标识数(UID)到一个指针。除了提供三个标准的映射操作外,Linux 还在 add 操作基础上实现了 allocate 操作。allocate 操作用于产生 UID(由内核分配,也就是自动生成的键值)。
初始化一个 idr
1
void idqr_init(struct idr *idp)
分配一个新的 UID
第一步:预分配空间
1
int idr_pre_get(struct idr *idp,gfp_t gfp_mask)
该函数将在需要时进行 UID 的分配工作:调整由 idp 指向的 idr 的大小。
注意该函数成功时返回 1,这是个特例
第二步:获取新的 UID
1
int idr_get_new(struct idr *idp, void *ptr, int *id);
将新的 UID 关联到 ptr,id 作为出参保存返回的 UID 值。
1
int idr_get_new_above(struct idr *idp, void *ptr,int starting_id, int *id);
该函数和
idr_get_new功能相同,但可以要求使用大于等于 starting_id 值的 UID。通过类似
idr_get_new_above(&idr_huh, ptr, next_id, &id);next_id = id + 1;的方式可以保证每次获得的 UID 不会重复(TODO:正常情况会重复吗)
查找 UID
1
void *idr_find(struct idr *idp, int id);
失败时返回空指针,所以尽量不要在 idr 中保存空指针,这样会无法分清是调用失败还是成功。
删除 UID
1
void idr_remove(struct idr *idp,int id);
删除全部 UID:
1
void idr_remove_all(struct idr *idp);
TODO:会不会释放内存
撤销 idr
1
void idr_destroy(struct idr *idp);
如果该方法成功,则只释放 idr 中未使用的内存。所以在此之前一般要调用 idr_remove_all 保证 idr 为空。
二叉树
内核使用红黑树,称为 rbtree,声明在文件 <linux/rbtree.h>