Linux内核学习笔记之系统调用
在现代操作系统中,内核提供了用户进程与内核进行交互的一组接口。这些接口让应用程序受限地访问硬件设备。应用程序发出各种请求而内核负责满足这些请求(或者无法满足时返回一个错误)。实际上提供这些接口主要是为了保证系统稳定可靠,避免应用程序恣意妄行。
与内核通信
系统调用在用户空间进程和硬件设备之间添加了一个中间层:
- 它为用户空间提供了统一的硬件的
抽象接口。 - 系统调用保证了系统的
稳定和安全,如权限管理,过滤异常请求。 - 让内核
统一管理硬件资源,从而实现多任务和虚拟化等功能
API、POSIX 和 C 库
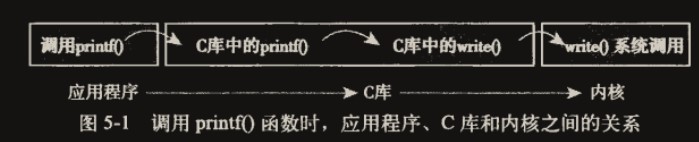
应用编程接口(API)
一个 API 定义了一组应用程序使用的编程接口。应用程序可直接使用 API 提供的功能而无需关心底层的系统调用。
POSIX 标准
POSIX 是由 IEEE 的一组标准组成,其目标是提供一套大体上基于 Unix 的可移植操作系统标准。它基本上是 Portable Operating System Interface(可移植操作系统接口)的缩写,而 X 则表明其对 Unix API 的传承。
Linux 基本上逐步实现了 POSIX 兼容,但并没有参加正式的 POSIX 认证。
微软的 Windows NT 声称部分实现了 POSIX 标准。
C 库
Linux 的系统调用作为 C 库的一部分提供(像大多数 Unix 系统一样)。C 库也实现了大部分的 POSIX API。
Unix 的接口设计有一名格言“提供机制而不是策略“。大部分的编程问题都可以被切割成两个部分“需要提供什么功能”(机制)和“怎样实现这些功能”(策略)。
系统调用
通常通过 C 库中定义的函数调用来进行。系统调用在出现错误的时候 C 库会把错误码写人 errmo 全局变量。通过调用 perror()库函数,可以把该变量翻译成用户可以理解的错误字符串。
1
asmlinkage long sys_getpid(void)
- 限定词:
asmlinkage限定词,这是一个编译指令,通知编译器仅从栈中提取该函数的参数。所有的系统调用都需要这个限定词。 - 返回值类型:函数返回 long。为了保证 32 位和 64 位系统的兼容,系统调用在用户空间和内核空间有不同的
返回值类型,在用户空间为 int,在内核空间为 long。 - 命名规则:get_pid()在内核中被定义成 sys_getpid()。Linux 中所有系统调用都应该遵守该
命名规则
可以用SYSCALL_DEFINE0宏简化书写:
1
2
3
SYSCALL_DEFINE0(getpid) {
return task_tgid_vnr(current); // returns current->tgid
}
这里返回的是 tgid(线程组 id),因为对于一般进程(非线程),其 tgid 和 pid 相同。对于线程,位于同一线程组内的 tgid 相同,也就是组长(进程主线程)的 pid。从线程定义上来讲它的 pid 就是所属进程的 pid,所以该方式是合理的。
展开后就是上面的函数定义。
系统调用号
在 Linux 中,每个系统调用被赋予一个唯一的系统调用号,一旦编译完成,该绑定关系无法变更。绑定关系放在 sys_call_table 系统调用表中。
在编译完用户程序中不保存系统调用函数的地址,而是保存一个系统调用号,内核通过该系统调用号查找对应的系统调用函数的地址。用户空间的程序无法直接执行内核代码。它们不能直接调用内核空间中的函数,因为内核驻留在受保护的地址空间上。下一节有详细介绍。
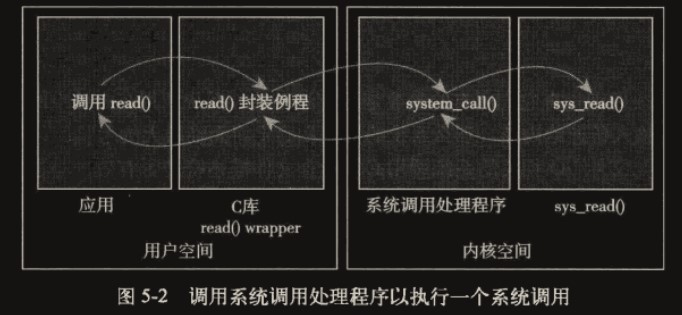
系统调用处理程序
应用程序应该以某种方式通知系统,告诉内核自己需要执行一个系统调用,希望系统切换到内核态,这样内核就可以代表应用程序在内核空间执行系统调用
通知内核的机制是靠软件中断实现的:
- 用户程序触发异常,将系统调用号保存到寄存器
- 进入中断,系统切换到内核态
- 执行中断号
128(int 0x80)的中断处理程序(注意软件中断和硬件中断入口不同),也就是系统调用处理程序system_call(),参数(系统调用号)从寄存器获取
执行系统调用处理程序
根据寄存器内保存的系统调用号查系统调用表获取系统调用函数地址
1
call *sys_call_table(,%rax,8)
在 64 位系统上,一个指针为 8 字节,系统调用表中的对应的指针地址为 rax*8。
参数传递
除了系统调用号,系统调用处理程序还需要额外的参数用于执行系统调用函数。同样使用寄存器来实现,如 x86 使用 ebx、ecx、edx、esi 和 edi 保存前 5 个参数,之后的参数都存在用户空间的一片区域,使用一个寄存器保存那片空间的指针
系统调用的实现
系统调用设计
- 决定用途:参考 Unix 设计哲学
“Do One Thing and Do It Well”,一个系统调用应该只做一件事,避免多用途的系统调用 - 定义的参数、返回值和错误码:接口力求简洁,并向后兼容,高可移植性。“提供机制而不是策略”。
参数验证
系统调用必须检查每个参数,保证它们不但合法有效,而且正确。进程不应当让内核去访问那些它无权访问的资源。
参数里包含指针是比较值得关注的情况,在接收一个用户空间的指针时,内核必须保证:
- 指针指向的内存区域属于
用户空间。进程决不能哄骗内核去读内核空间的数据。 指针指向的内存区域在
本进程的地址空间里。进程决不能哄骗内核去读其他进程的数据。内核提供了两个方法来完成必须的检查和
内核空间与用户空间之间数据的来回拷贝:- copy_to_user():向用户空间写入数据
- copy_from_user():从用户空间读取数据
示例,一个虚构的
silly_copy 系统调用把 len 字节的数据从’src’拷贝到’dst’,让内核空间作为中转站:1 2 3 4 5 6 7 8 9 10 11 12 13
SYSCALL_DEFINE3(silly_copy, unsigned long *, src, unsigned long *, dst, unsigned long, len) { unsigned long buf; /*将用户地址空间中的src拷贝进buf*/ if (copy_from_user(&buf, src, len)) return -EFAULT; /*将buf拷贝进用户地址空间中的dst*/ if (copy_to_user(dst, &buf, len)) return -EFAULT; /*返回拷贝的数据量*/ return len; }
宏定义中,类型和参数名用逗号分开,由宏重新组合
如果是读,该内存应被标记为可读;如果是写,该内存应被标记为可写;如果是可执行该内存应被标记为可执行。进程决不能绕过内存
访问限制。调用者可以使用 capable()函数来检查是否有权能对指定的资源进行操作,如果它返回非 0 值,调用者就有权进行操作,返回 0 则无权操作。
示例,reboot 系统调用:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51
SYSCALL_DEFINE4(reboot, int, magic1, int, magic2, unsigned int, cmd, void __user *, arg) { struct pid_namespace *pid_ns = task_active_pid_ns(current); char buffer[256]; int ret = 0; /* We only trust the superuser with rebooting the system. */ // 通过ns_capable判断,只信任系统管理员 if (!ns_capable(pid_ns->user_ns, CAP_SYS_BOOT)) return -EPERM; /* For safety, we require "magic" arguments. */ // 为了安全起见,需要通过判断魔术字的方法判定合法性 if (magic1 != LINUX_REBOOT_MAGIC1 || (magic2 != LINUX_REBOOT_MAGIC2 && magic2 != LINUX_REBOOT_MAGIC2A && magic2 != LINUX_REBOOT_MAGIC2B && magic2 != LINUX_REBOOT_MAGIC2C)) return -EINVAL; /* * If pid namespaces are enabled and the current task is in a child * pid_namespace, the command is handled by reboot_pid_ns() which will * call do_exit(). */ ret = reboot_pid_ns(pid_ns, cmd); if (ret) return ret; /* Instead of trying to make the power_off code look like * halt when pm_power_off is not set do it the easy way. */ if ((cmd == LINUX_REBOOT_CMD_POWER_OFF) && !pm_power_off) cmd = LINUX_REBOOT_CMD_HALT; mutex_lock(&reboot_mutex); switch (cmd) { case LINUX_REBOOT_CMD_RESTART: kernel_restart(NULL); break; ... default: ret = -EINVAL; break; } mutex_unlock(&reboot_mutex); return ret; }
系统调用上下文
内核在执行系统调用时,上下文依然属于当前进程,current 指针指向当前任务,也就是触发这个系统调用的进程(进程被软件中断打断,但上下文不会发生切换,这取决于中断入口处的处理)。
此时,虽然处于内核空间,但进程依然可以休眠和被抢占,就像进程处于用户空间一样。切换到新进程后可能也会执行相同的系统调用,所以要保证系统调用是可重入的。
注意:不同于硬件中断,软件中断的中断处理程序自由很多,因为 CPU 并没有关中断,所以可以被抢占,可以主动阻塞睡眠,对执行时间要求也没那么高。
系统调用返回时,控制权依然在系统调用处理程序system_call()手上,它最终会负责切换到用户空间,并让用户进程继续执行下去。
注册系统调用
- 首先,在
系统调用表的最后插入一个表项。每种支持该系统调用的硬件体系都要这么(大部分的系统调用都适用于所有的体系结构(体系无关))。从 0 开始算起,系统调用在该表中的位置就是它的系统调用号。如第 10 个系统调用分配到的系统调用号为 9。 - 对于所支持的各种体系结构,系统调用号都必须定义于对应体系目录下的
<asm/unistd.h>中,如<arch/x86/include/asm/unistd.h>。 - 系统调用必须被编译进内核映象(不能被编译成模块)。这只要把它放进 kernel 下的一个相关文件中就可以了,比如
sys.c,它包含了各种各样的系统调用。
示例,将虚构的 sys_foo() 注册为系统调用:
插入
系统调用表,分配系统调用号对于大多数体系结构来说,该表位于 entry.s 文件中
将
.long sys_foo该项追加到最后即可1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24
ENTRY(sys_call_table) .long sys_restart_syscall /* 0 - old "setup()" system call*/ .long sys_exit .long sys_fork .long sys_read .long sys_write .long sys_open /* 5 */ .long sys_close .long sys_waitpid .long sys_creat .long sys_link .long sys_unlink /* 10 */ ... .long sys_open_by_handle_at /* 360 */ .long sys_clock_adjtime .long sys_syncfs .long sys_sendmmsg .long sys_setns .long sys_process_vm_readv /* 365 */ .long sys_process_vm_writev .long sys_kcmp .long sys_finit_module // 在系统调用表中插入函数地址,分配系统调用号 .long sys_foo /* 369 */
将系统调用号加入
<asm/unistd.h>中1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27
#define __NR_restart_syscall 0 #define __NR_exit 1 #define __NR_fork 2 #define __NR_read 3 #define __NR_write 4 #define __NR_open 5 #define __NR_close 6 #define __NR_waitpid 7 #define __NR_creat 8 #define __NR_link 9 #define __NR_unlink 10 ... #define __NR_open_by_handle_at 360 #define __NR_clock_adjtime 361 #define __NR_syncfs 362 #define __NR_sendmmsg 363 #define __NR_setns 364 #define __NR_process_vm_readv 365 #define __NR_process_vm_writev 366 #define __NR_kcmp 367 #define __NR_finit_module 368 // 在此处加入,注意需要修改NR_syscalls的值 #define __NR_foo 369 // #define NR_syscalls 369 #define NR_syscalls 370
实现
sys_foo()函数这个例子中我们把它放进
kernel/sys.c中1 2 3 4 5 6
#include <asm/page.h> /*sys_foo - 返回进程的内核栈大小*/ asmlinkage long sys_foo(void) { return THREAD_SIZE; }
从用户空间访问系统调用
通常,系统调用靠 C 库支持。用户程序通过如 glibc 提供的中间函数访问系统调用。
但如果需要调用的系统调用未被 glibc 库支持,就需要直接调用。
Linux 本身提供了一组宏,用于直接对系统调用进行访问。它会设置好寄存器并调用陷和指令。这些宏是_syscalln(),其中n的范围从 0 到 6,代表需要传递给系统调用的参数个数,这是由于该宏必须了解到底有多少参数按照什么次序压人寄存器。
举个例子,open() 系统调用的定义是:
1
long open(const char *filename, int flags, int mode)
直接调用的方式:
1
2
#define NR_open 5
_syscall3(long, open, const char*, flename, int, flags, int, mode)
对于每个宏来说,都有2+2*n个参数。第一个参数对应着系统调用的返回值类型。第二个参数是系统调用的名称。再以后是按照系统调用参数的顺序排列的每个参数的类型和名称。_NR_open在<asm/unistd.h>中定义,是系统调用号。
该宏会被扩展成为内嵌汇编的 C 函数,函数名就是 open,由汇编语言执行前面内容中所讨论的步骤: 将系统调用号和参数压入寄存器并触发软件中断来陷入内核。
之后直接在需要该系统调用的地方调用 open 函数即可。
1
2
3
4
5
6
7
8
9
10
11
#define __NR_foo 283
__syscall0(long, foo)
int main()
{
long stack_size;
// 直接调用foo就像,已经由__syscall0宏定义
stack_size = foo();
printf("The kernel stack size is %ld\n", stack_size);
return 0;
}
谨慎使用自定义系统调用
自定义系统调用优点:
- 系统调用
创建容易且使用方便。 - Linux 系统调用的
高性能显而易见。
缺点:
- 你需要一个系统调用号,而这需要一个内核在处于开发版本的时候由官方分配给你。
- 系统调用被加入稳定内核后就被固化了,为了避免应用程序的崩溃,它的接口不允许做改动。
- 需要将系统调用
分别注册到每个需要支持的体系结构中去。 - 在
脚本中不容易调用系统调用,也不能从文件系统直接访问系统调用。 - 由于你需要系统调用号,因此在
主内核树之外是很难维护和使用系统调用的。 - 如果仅仅进行简单的信息交换,系统调用就
大材小用了