Linux内核学习笔记之定时器和时间管理
内核中的时间概念
系统定时器以某种频率自行触发(经常被称为击中(hitting)或射中(popping))时钟中断,该频率可以通过编程预定,称作节拍率(tick rate)。
当时钟中断发生时,内核就通过一种特殊的中断处理程序对其进行处理。两次时钟中断的间隔时间称为节拍(tick),它等于节拍率分之一(1/(tick rate))秒。
内核通过控制时钟中断维护实际时间,另外内核也为用户空间提供了一组系统调用以获取实际日期和实际时间。
节拍率:HZ
系统定时器频率(节拍率)是通过静态预处理定义的,也就是 HZ(赫兹),在系统启动时按照 HZ 值对硬件进行设置。体系结构不同,HZ 的值也不同
内核将 HZ 值保存在 HZ 变量中。
理想的 HZ 值
自 Linux 问世以来,i386 体系结构中时钟中断频率就设定为 100HZ,但是在 2.5 开发版内核 中,中断频率被提高到 1000HZ。
好处:
- 更高的时钟中断解析度(resolution)可提高时间驱动事件的解析度。比如可以设置以 1ms 为周期的事件,而 100HZ 就无法做到。
- 提高了时间驱动事件的准确度(accuracy)。在 100HZ 下的定时事件,平均会在事件触发的 5ms 后因为时钟中断而执行(比如事件生成在 0ms,定时 10ms,而时钟中断时间为 7ms、17ms、27ms,则事件实际执行在 17ms 上,误差 7ms),平均误差就会是 5ms(误差范围 0-10ms);而 1000HZ 下平均误差为 0.5ms(误差范围 0-1ms)。
坏处:
- 更多的时钟中断意味着系统必须更频繁得处理时钟中断,降低了系统性能
Linux 开启
CONFIG_NO_HZ配置后可启用动态节拍功能。如果系统知道接下来的 50ms 都是空闲的(TODO:怎么判断的?),则在接下来的 50ms 内不会触发时钟中断。可以降低高 HZ 带来的坏处。
jiffies
全局变量 jiffies 用来记录自系统启动以来产生的节拍(tick)的总数。
jiffies 定义:
1
2
3
// include/linux/jiffies.h
extern u64 __jiffy_data jiffies_64;
extern unsigned long volatile __jiffy_data jiffies;
32 位系统中,在每 HZ 递增一次 jiffies 的情况下,unsigned long 类型的 jiffies 很快会溢出,1000HZ 为 49.7 天。所以使用 jiffies_64 用于保存实际的 HZ。在 64 位体系结构上,jiffies64 和 jiffies 指的是同一个变量
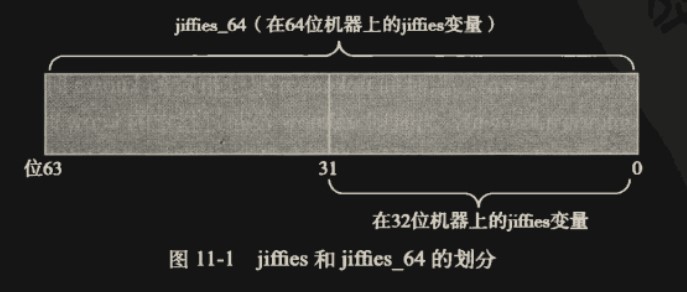
访问 jiffies 的代码仅会读取 jiffies64 的低 32 位。通过 get_jiffies_64()函数(在 32 位机器上无法原子性的访问一个 64 位的变量,需要读两次,所以要加锁来保证原子读取),就可以读取整个 64 位数值。但是这种需求很少,多数代码仍然只要能通过 jiffies 变量读取低 32 位就够了。
秒转为 jiffies:
1
seconds * HZ // 秒乘以节拍率
jiffies 转换为秒:
1
jiffies/HZ // JIFFIES除以节拍率
设置将来时间示例:
1
2
3
4
unsigned long time_stamp = jiffies; /* 现在 */
unsigned long next_tick = jiffies + 1; /* 从现在开始 1 个节拍 */
unsigned long later = jiffies + 5 * HZ; /* 从现在开始 5 秒 */
unsigned long fraction = jiffies + HZ / 10; /* 从现在开始 1/10 秒*/
32 位的回绕
32 位的 jiffies 能记录的大小很有限,到达上限就会回绕为 0
1
2
3
4
5
6
7
8
9
unsigned long timeout = jiffies + HZ/2; // 设置超时
// 执行一些任务...
// 判断是否超时
if (timeout > jiffies) {
// 超时了
}
else {
// 还没超时
}
上例中,如果刚好在判断超时前发生了回绕,jiffies 变为 0,则会导致判断失效,超时被误判为未超时。
内核提供了几个宏用于时间判断,防止回绕导致的误判:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
// include/linux/jiffies.h
// typecheck为编译时的类型合法性检查
// 时间a是否在b之后,b一般为已知的jiffies
#define time_after(a, b) \
(typecheck(unsigned long, a) && \
typecheck(unsigned long, b) && \
((long)((b) - (a)) < 0)) // 通过将结果转为long有符号类型就行
// 时间a是否在b之前
#define time_before(a, b) time_after(b, a)
#define time_after_eq(a, b) \
(typecheck(unsigned long, a) && \
typecheck(unsigned long, b) && \
((long)((a) - (b)) >= 0))
#define time_before_eq(a, b) time_after_eq(b, a)
// a是否在[b,c]闭区间范围
#define time_in_range(a, b, c) \
(time_after_eq(a, b) && \
time_before_eq(a, c))
#define time_in_range_open(a, b, c) \
(time_after_eq(a, b) && \
time_before(a, c))
// 强制64位版
#define time_after64(a, b) \
(typecheck(__u64, a) && \
typecheck(__u64, b) && \
((__s64)((b) - (a)) < 0))
#define time_before64(a, b) time_after64(b, a)
#define time_after_eq64(a, b) \
(typecheck(__u64, a) && \
typecheck(__u64, b) && \
((__s64)((a) - (b)) >= 0))
#define time_before_eq64(a, b) time_after_eq64(b, a)
原理:以 time_after 为例,要发生回绕时,无符号的 a 已经接近最大值,它的有符号类型值应该为负(首位为 1 表示负数),假设 b 和 a 接近(首位也为 1,如果为 0,该宏就会失效),那么 b 的有符号类型也为负。此时 a 回绕变为比较小的数,有符号类型值也为正数,b-a 的无符号为正数,但有符号类型为负数。
所以该宏只能判断时间差小于最大无符号值的一半的两个时间的回绕,1000HZ 下大概就是 25 天,但这也够用了。
用户空间和 HZ
系统更新 HZ 时,对应的 jiffies 也会更新,如从 100HZ 切换成 1000HZ,假设此时 jiffies 为 332,则 jiffies 将从 332 变为 3320。
但这样对用户空间程序来说就很困惑了,一般用户程序启动时读取一次 HZ 值,后续就不读取了,也不知道 HZ 被更新了。如果用户程序切换前读取一次 jiffies,切换后读取一次 jiffies,然后用差值除以 HZ 计算经过的时间秒数,则会出错((335-332)/100 变为(3350-332)/100)。
所以内核提供了一个固定的 USER_HZ,它在系统启动后不会更新,用户程序可以使用它作为 HZ,不管内核中的 HZ 和 jiffies 如何更新,用户程序可以通过内核提供的换算函数得到 USER_HZ 下的虚拟 jiffies:
user_jiffies = jiffies / (HZ / USER_HZ)
还是上例,user_jiffies 切换前332/(100/100)=332,切换后3350/(1000/100)=335
硬时钟和定时器
实时时钟
实时时钟(RTC)是用来持久存放系统时间的设备,即便系统关闭后,它也可以靠主板上的微型电池提供的电力保持系统的计时。在 PC 体系结构中,RTC 和 CMOS 集成在一起,而且 RTC 的运行和 BIOS 的保存设置都是通过同一个电池供电的。
当系统启动时,内核通过读取 RTC 来初始化墙上时间(wall time),该时间存放在 xtime 变量中。部分体系架构会周期性的将 xtime 回写 RTC。
系统定时器
一般通过晶振分频实现周期性中断。
x86 架构集成了名为可编程中断时钟 PIT(Programmable Interval Timer)的定时器(无需外部晶振),可以动态调节需要的 HZ,以实现周期性中断。
时钟中断处理程序
时钟中断处理程序需要完成的工作:
- 获得锁,以便对访问 jiffies_64 和墙上时间 xtime 进行保护。
- 需要时应答或重新设置系统时钟。
- 周期性地使用墙上时间更新实时时钟。
- 调用体系结构无关的时钟例:
tick_periodic().
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
// kernel/time/tick-common.c
static void tick_periodic(int cpu)
{
if (tick_do_timer_cpu == cpu)
{
write_seqlock(&jiffies_lock);
/* Keep track of the next tick event */
tick_next_period = ktime_add(tick_next_period, tick_period);
// 更新jiffies_64和墙上时间,计算系统平均负载统计值
do_timer(1);
write_sequnlock(&jiffies_lock);
}
// 更新当前进程消耗的CPU时间,一般认为当前进程占用了整个tick
update_process_times(user_mode(get_irq_regs()));
profile_tick(CPU_PROFILING);
}
do_timer:
1
2
3
4
5
6
7
8
9
// kernel/time/timekeeping.c
// 调用时必须处于上seqlock锁状态
void do_timer(unsigned long ticks)
{
jiffies_64 += ticks;
update_wall_time();
// 计算系统平均负载统计值
calc_global_load(ticks);
}
update_process_times:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
// kernel/timer.c
// 参数user_tick表示tick花费在用户空间还是内核空间
void update_process_times(int user_tick)
{
struct task_struct *p = current;
int cpu = smp_processor_id();
/* Note: this timer irq context must be accounted for as well. */
account_process_tick(p, user_tick);
run_local_timers();
rcu_check_callbacks(cpu, user_tick);
#ifdef CONFIG_IRQ_WORK
if (in_irq())
irq_work_run();
#endif
scheduler_tick();
run_posix_cpu_timers(p);
}
account_process_tick:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
// 更新进程占用的CPU时间
void account_process_tick(struct task_struct *p, int user_tick)
{
cputime_t one_jiffy_scaled = cputime_to_scaled(cputime_one_jiffy);
struct rq *rq = this_rq();
if (vtime_accounting_enabled())
return;
if (sched_clock_irqtime)
{
irqtime_account_process_tick(p, user_tick, rq, 1);
return;
}
if (steal_account_process_tick())
return;
if (user_tick)
account_user_time(p, cputime_one_jiffy, one_jiffy_scaled);
else if ((p != rq->idle) || (irq_count() != HARDIRQ_OFFSET))
account_system_time(p, HARDIRQ_OFFSET, cputime_one_jiffy,
one_jiffy_scaled);
else
account_idle_time(cputime_one_jiffy);
}
执行软件中断处理时,服务程序认为上一个 tick 就是被中断的进程独占的,将该 tick 时间加入该进程的占用 CPU 时间统计中。但是无法判断上个 tick 内是否只有当前被中断的进程运行,有可能出现以下情况:期间发生过调度,其他进程运行过,当前进程只运行了如 0.1 个 tick。所以该统计实际上不是很准确,所以才要提高 HZ 来减少这种误差。
实际时间(墙上时间 wall time)
实际时间 xtime 已成为 timekeeper 变量的一部分。
1
2
// kernel/time/timekeeping.c
static struct timekeeper timekeeper;
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
// include/linux/timekeeper_internal.h
struct timekeeper
{
/* Current clocksource used for timekeeping. */
struct clocksource *clock;
/* NTP adjusted clock multiplier */
u32 mult;
/* The shift value of the current clocksource. */
u32 shift;
/* Number of clock cycles in one NTP interval. */
cycle_t cycle_interval;
/* Last cycle value (also stored in clock->cycle_last) */
cycle_t cycle_last;
/* Number of clock shifted nano seconds in one NTP interval. */
u64 xtime_interval;
/* shifted nano seconds left over when rounding cycle_interval */
s64 xtime_remainder;
/* Raw nano seconds accumulated per NTP interval. */
u32 raw_interval;
/* Current CLOCK_REALTIME time in seconds */
u64 xtime_sec;
/* Clock shifted nano seconds */
u64 xtime_nsec;
/* Difference between accumulated time and NTP time in ntp
* shifted nano seconds. */
s64 ntp_error;
/* Shift conversion between clock shifted nano seconds and
* ntp shifted nano seconds. */
u32 ntp_error_shift;
/*
* wall_to_monotonic is what we need to add to xtime (or xtime corrected
* for sub jiffie times) to get to monotonic time. Monotonic is pegged
* at zero at system boot time, so wall_to_monotonic will be negative,
* however, we will ALWAYS keep the tv_nsec part positive so we can use
* the usual normalization.
*
* wall_to_monotonic is moved after resume from suspend for the
* monotonic time not to jump. We need to add total_sleep_time to
* wall_to_monotonic to get the real boot based time offset.
*
* - wall_to_monotonic is no longer the boot time, getboottime must be
* used instead.
*/
struct timespec wall_to_monotonic;
/* Offset clock monotonic -> clock realtime */
ktime_t offs_real;
/* time spent in suspend */
struct timespec total_sleep_time;
/* Offset clock monotonic -> clock boottime */
ktime_t offs_boot;
/* The raw monotonic time for the CLOCK_MONOTONIC_RAW posix clock. */
struct timespec raw_time;
/* The current UTC to TAI offset in seconds */
s32 tai_offset;
/* Offset clock monotonic -> clock tai */
ktime_t offs_tai;
};
xtime_sec 存放着自 1970 年 1 月 1 日(UTC)以来经过的时间(秒),xtime_nsec 存放尾数(纳秒)
读取实际时间
seq 锁:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
// include/linux/seqlock.h
static inline unsigned __read_seqcount_begin(const seqcount_t *s)
{
unsigned ret;
repeat:
ret = ACCESS_ONCE(s->sequence);
if (unlikely(ret & 1))
{
cpu_relax();
goto repeat;
}
return ret;
}
static inline int __read_seqcount_retry(const seqcount_t *s, unsigned start)
{
return unlikely(s->sequence != start);
}
使用上述两个函数实现的一次读取:
1
2
3
4
5
6
7
8
9
unsigned long seq;
do
{
seq = read_seqcount_begin(&timekeeper_seq);
ts->tv_sec = tk->xtime_sec;
nsecs = timekeeping_get_ns(tk);
} while (read_seqcount_retry(&timekeeper_seq, seq));
该循环不断重复,直到读者确认读取数据时没有写操作介入。如果发现循环期间有时钟中断处理程序更新 xtime,那么 read_seqretry()函数就为 True,继续循环等待。
从用户空间读取
用户空间程序需要使用系统调用 sys_gettimeofday 读取实际时间
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
// kernel/compat.c
asmlinkage long compat_sys_gettimeofday(struct compat_timeval __user *tv,
struct timezone __user *tz)
{
if (tv)
{
struct timeval ktv;
// 这个就是上面提到的通过read_seqcount_retry循环读取时间
do_gettimeofday(&ktv);
if (compat_put_timeval_convert(tv, &ktv))
return -EFAULT;
}
if (tz)
{
// 如果tz不为空,说明用户程序希望获得时区,这里就会将系统时区返回
if (copy_to_user(tz, &sys_tz, sizeof(sys_tz)))
return -EFAULT;
}
return 0;
}
虽然内核也实现了 time()系统调用,但是 gettimeofday()几乎完全取代了它。另外 C 库函数也提供了一些墙上时间相关的库调用,比如 ftime()和 ctime()。
定时器
定时器用于延后任务的执行。指定超时时间和任务,定时器在检测到超时后就会执行该任务。这种任务只能运行一次,然后被销毁,不会周期性执行。
定时器定义
定时器由结构 timerlist 表示,定义在文件<linux/timer.h>中。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
// include/linux/timer.h
struct timer_list
{
/*
* All fields that change during normal runtime grouped to the
* same cacheline
*/
struct list_head entry; // 定时器链表入口
unsigned long expires; // 以jiffies为单位的超时时间(绝对时间)
struct tvec_base *base; // 定时器内部值,用户无需关心
void (*function)(unsigned long); // 定时处理的函数
unsigned long data; // 函数的参数
int slack;
#ifdef CONFIG_TIMER_STATS
int start_pid;
void *start_site;
char start_comm[16];
#endif
#ifdef CONFIG_LOCKDEP
struct lockdep_map lockdep_map;
#endif
};
定时器接口
创建定时器:
1
struct timer_list my_timer;
初始化定时器:
1
2
3
4
init_timer(&my_timer);
my_timer.expires = jiffies + HZ; // 加个HZ,相当于加1秒
my_timer.data = IRQ_PCI_SERR; // unsigned long类型的参数,无需参数可以填0
my_timer.function = my_function; // 处理函数void my_function(unsigned long data);
激活定时器:
1
add_timer(&my_timer);
当节拍数大于等于定时值时,任务开始执行。可能会延误,所以不能执行硬实时任务(后面有提到是因为以软中断的方式执行)。
修改定时器:
1
mod_timer(&my_timer, jiffies + new_delay);/* 新的定时,会激活未激活的定时器 */
删除定时器:
1
del_timer(&my_timer); // 已经激活并执行完成的任务会自动销毁,无需删除
同步删除定时器:
1
del_timer_sync(&my_timer);
在 del_timer 时已经在其他处理器上运行的任务无法停止,只能保证del_timer返回后任务不会开始执行。使用del_timer_sync可以等待正在其他 CPU 上运行的任务全部返回,防止后续再次执行 my_function 导致和其他 CPU 上正在执行的 my_function 产生竞争。
del_timer_sync会阻塞,无法在中断上下文中使用。
定时器竞争条件
定时器与当前执行代码是异步的,因此就有可能存在潜在的竞争条件
比如 del_timer_sync 就是为了同步删除设计的。
实现定时器
时钟中断处理程序会执行update_process_times()函数,该函数随即调用run_local_timers()触发软中断:
1
2
3
4
5
6
7
// kernel/timer.c
void run_local_timers(void)
{
// 高精度定时器hrtimer相关操作
hrtimer_run_queues();
raise_softirq(TIMER_SOFTIRQ); // 触发软中断
}
TIMER_SOFTIRQ对应的软中断处理函数为run_timer_softirq(),在当前处理器上运行所有的(如果有的话)超时定时器:
1
2
3
4
5
6
7
8
9
10
static void run_timer_softirq(struct softirq_action *h)
{
// 获取当前CPU的定时器向量基址
struct tvec_base *base = __this_cpu_read(tvec_bases);
hrtimer_run_pending();
// 对比该定时器的最小到期时间,如果小于当前时间,说明至少有一个定时器过期
if (time_after_eq(jiffies, base->timer_jiffies))
__run_timers(base);
}
延迟执行
我们已经了解了可以通过下半部和定时器延后执行某些任务,下面介绍些其他方法
忙等待
循环等待,判断是否到达指定时间
1
2
3
unsigned long delay = jiffies + 5*HZ;//等待五秒
while (time_before(jiffies, delay))
cond_resched(); // 防止无意义等待,激活重新调度
cond_resched() 函数将调度一个新程序投入运行,但它只有在设置完 need_resched 标志后才能生效。换名话说,该方法有效的条件是系统中存在更重要的任务需要运行。
不要在中断上下文、禁中断、持有锁时使用忙等待。
短延迟
如果需要很短的延迟,比如 1ns,而 ticks 又无法满足这种精度,需要使用执行空循环的方式实现。
内核提供三个短延迟函数:
1
2
3
4
5
// arch/alpha/include/asm/delay.h
// include/linux/delay.h
extern void udelay(unsigned long usecs); // 微秒
extern void mdelay(unsigned long msecs); // 毫秒
extern void ndelay(unsigned long nsecs); // 纳秒
内核知道处理器在一定时间内 CPU 能执行多少次循环(也就是 BogoMIPS),然后推算出指定时间(如 2ns 或 15us)需要多少次循环。
注意,要只在很小的延迟中使用这些函数,不要用于长延迟
BogoMIPS
BogoMIPS 值记录处理器在给定时间内忙循环执行的次数(近似于空闲时的指令执行速度),它的名字取自 bogus(虚假)和 MIPS(处理百万条指令/秒),它的初衷并不是表示性能的强弱。可以从文件
/proc/cpuinfo中读到它。延迟循环函数使用loops_per_jiffy(每 tick 多少次 loop) 值来计算(相当准确)某一段精确延迟而需要进行多少次循环。内核在启动时利用calibrate_delay()计算loops_per_jiffy值,该函数在文件init/main.c中。如今的 ARM 已经使用独立计时器用于该操作,loops_per_jiffy 用于反映计时器频率且和 CPU 主频无关,所以并不能用 BogoMIPS 反映 CPU 性能。
schedule_timeout()
更理想的延迟执行方法是使用schedule_timeout()函数,该方法会让需要延迟执行的任务睡眠到指定的延迟时间耗尽后再重新运行。
但该方法也不能保证睡具时间正好等于指定的延迟时间,只能尽量使睡眠时间接近指定的延迟时间。当指定的时间到期后,内核唤醒被延迟的任务并将其重新放回运行队列
使用方法:
1
2
3
4
5
/*将任务设置为可中断睡眠状态*/
set_current_state(TASK_INTERRUPTIBLE);
/*小睡一会儿,s 秒后唤醒*/
schedule_timeout(s*HZ);
必须提前将任务置为TASK_INTERRUPTIBLE或TASK_UNINTERRUPTIBLE状态(状态见state),就是让进程离开就绪队列,进入阻塞态,然后靠内核定时器唤醒它(如果还在就绪队列,即使放弃 CPU 依然会被调度到)
schedule_timeout 实现:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
// kernel/timer.c
signed long __sched schedule_timeout(signed long timeout)
{
// 定义一个定时器
struct timer_list timer;
unsigned long expire;
switch (timeout)
{
// 如果指定了无限期睡眠,则无需使用定时器唤醒操作,需要用户自己定义唤醒操作
case MAX_SCHEDULE_TIMEOUT:
/*
* These two special cases are useful to be comfortable
* in the caller. Nothing more. We could take
* MAX_SCHEDULE_TIMEOUT from one of the negative value
* but I' d like to return a valid offset (>=0) to allow
* the caller to do everything it want with the retval.
*/
schedule(); // 直接调度,不触发后续操作
goto out;
default:
/*
* Another bit of PARANOID. Note that the retval will be
* 0 since no piece of kernel is supposed to do a check
* for a negative retval of schedule_timeout() (since it
* should never happens anyway). You just have the printk()
* that will tell you if something is gone wrong and where.
*/
if (timeout < 0)
{
printk(KERN_ERR "schedule_timeout: wrong timeout "
"value %lx\n",
timeout);
dump_stack();
current->state = TASK_RUNNING;
goto out;
}
}
// 如果指定了MAX_SCHEDULE_TIMEOUT,则下面一部分跳过
// 设置超时
expire = timeout + jiffies;
// 配置定时器,绑定函数,process_timeout就是唤醒指定进程的函数,参数为current表示本进程
setup_timer_on_stack(&timer, process_timeout, (unsigned long)current);
__mod_timer(&timer, expire, false, TIMER_NOT_PINNED);
// 触发调度放弃CPU
schedule();
// 等调度结束回来后继续执行。
// 为了防止进程被其他动作提前唤醒,这里用同步方式删除定时器,确保等待到达指定时间。
// 正常情况下进程被之前配置的定时器唤醒,肯定已经超过定时器时间了。
del_singleshot_timer_sync(&timer);
/* Remove the timer from the object tracker */
destroy_timer_on_stack(&timer);
timeout = expire - jiffies;
out:
return timeout < 0 ? 0 : timeout;
}
内部用到的 process_timeout 函数:
1
2
3
4
5
6
// kernel/timer.c
static void process_timeout(unsigned long __data)
{
wake_up_process((struct task_struct *)__data);
}
process_timeout() 本质上利用了内核的定时器功能。