《Operating Systems: Three Easy Pieces》学习笔记(二十三) 基于锁的并发数据结构
并发计数器
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
// 简单的计数器,value值递增
typedef struct counter_t
{
int value;
} counter_t;
void init(counter_t *c)
{
c->value = 0;
}
void increment(counter_t *c)
{
c->value++;
}
void decrement(counter_t *c)
{
c->value--;
}
int get(counter_t *c)
{
return c->value;
}
简单但无法扩展的实现
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
typedef struct counter_t
{
int value;
pthread_mutex_t lock;
} counter_t;
void init(counter_t *c)
{
c->value = 0;
Pthread_mutex_init(&c->lock, NULL);
}
void increment(counter_t *c)
{
Pthread_mutex_lock(&c->lock);
c->value++;
Pthread_mutex_unlock(&c->lock);
}
void decrement(counter_t *c)
{
Pthread_mutex_lock(&c->lock);
c->value--;
Pthread_mutex_unlock(&c->lock);
}
int get(counter_t *c)
{
Pthread_mutex_lock(&c->lock);
int rc = c->value;
Pthread_mutex_unlock(&c->lock);
return rc;
}
这样做在多CPU环境下性能很差。因为这种锁导致了多 CPU 情况下也只允许一个线程在运行,其他都在自旋等待,没发挥出多 CPU 的优势。
可扩展的计数(扩展的意思是支持多 CPU)
懒惰计数器(sloppy counter)
懒惰计数器通过多个局部计数器和一个全局计数器来实现一个逻辑计数器,其中每个 CPU 核心有一个局部计数器。具体来说,在 4 个 CPU 的机器上,有 4 个局部计数器和 1 个全局计数器。除了这些计数器,还有锁:每个局部计数器有一个锁,全局计数器有一个。
懒惰计数器的基本思想是这样的。如果一个核心上的线程想增加计数器,那就增加它的局部计数器,访问这个局部计数器是通过对应的局部锁同步的。因为每个 CPU 有自己的局部计数器,不同 CPU 上的线程不会竞争,所以计数器的更新操作可扩展性好。
为了保持全局计数器更新(以防某个线程要读取该值),局部值会定期转移给全局计数器,方法是获取全局锁,让全局计数器加上局部计数器的值,然后将局部计数器置零
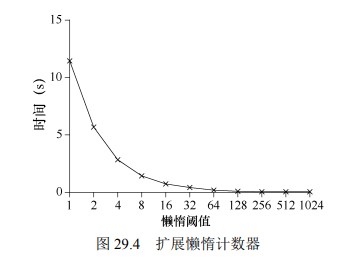
局部转全局的频度,取决于一个阈值,这里称为 S(表示 sloppiness)。S 越小,懒惰计数器则越趋近于非扩展的计数器。S 越大,扩展性越强,但是全局计数器与实际计数的偏差越大。
在这个例子中,阈值 S 设置为 5,4 个 CPU 上分别有一个线程更新局部计数器 L1,…, L4。随着时间增加,全局计数器 G 的值也会记录下来。每一段时间,局部计数器可能会增加。如果局部计数值增加到阈值 S,就把局部值转移到全局计数器,局部计数器清零。
| 时间 | L1 | L2 | L3 | L4 | G |
|---|---|---|---|---|---|
| 0 | 0 | 0 | 0 | 0 | 0 |
| 1 | 0 | 0 | 1 | 1 | 0 |
| 2 | 1 | 0 | 2 | 1 | 0 |
| 3 | 2 | 0 | 3 | 1 | 0 |
| 4 | 3 | 0 | 3 | 2 | 0 |
| 5 | 4 | 1 | 3 | 3 | 0 |
| 6 | 5→0 | 1 | 3 | 4 | 5(来自 L1) |
| 7 | 0 | 2 | 4 | 5→0 | 10(来自 L4) |
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
typedef struct counter_t
{
int global; // global count
pthread_mutex_t glock; // global lock
int local[NUMCPUS]; // local count (per cpu)
pthread_mutex_t llock[NUMCPUS]; // ... and locks
int threshold; // update frequency
} counter_t;
// init: record threshold, init locks, init values
// of all local counts and global count
void init(counter_t *c, int threshold)
{
c->threshold = threshold;
c->global = 0;
pthread_mutex_init(&c->glock, NULL);
int i;
for (i = 0; i < NUMCPUS; i++)
{
c->local[i] = 0;
pthread_mutex_init(&c->llock[i], NULL);
}
}
// update: usually, just grab local lock and update local amount
// once local count has risen by 'threshold', grab global
// lock and transfer local values to it
void update(counter_t *c, int threadID, int amt)
{
pthread_mutex_lock(&c->llock[threadID]);
c->local[threadID] += amt; // assumes amt > 0
if (c->local[threadID] >= c->threshold)
{ // transfer to global
pthread_mutex_lock(&c->glock);
c->global += c->local[threadID];
pthread_mutex_unlock(&c->glock);
c->local[threadID] = 0;
}
pthread_mutex_unlock(&c->llock[threadID]);
}
// get: just return global amount (which may not be perfect)
int get(counter_t *c)
{
pthread_mutex_lock(&c->glock);
int val = c->global;
pthread_mutex_unlock(&c->glock);
return val; // only approximate!
}
并发链表
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
// basic node structure
typedef struct node_t
{
int key;
struct node_t *next;
} node_t;
// basic list structure (one used per list)
typedef struct list_t
{
node_t *head;
pthread_mutex_t lock;
} list_t;
void List_Init(list_t *L)
{
L->head = NULL;
pthread_mutex_init(&L->lock, NULL);
}
int List_Insert(list_t *L, int key)
{
pthread_mutex_lock(&L->lock);
node_t *new = malloc(sizeof(node_t));
if (new == NULL)
{
perror("malloc");
pthread_mutex_unlock(&L->lock);
return -1; // fail
}
new->key = key;
new->next = L->head;
L->head = new;
pthread_mutex_unlock(&L->lock);
return 0; // success
}
int List_Lookup(list_t *L, int key)
{
pthread_mutex_lock(&L->lock);
node_t *curr = L->head;
while (curr)
{
if (curr->key == key)
{
pthread_mutex_unlock(&L->lock);
return 0; // success
}
curr = curr->next;
}
pthread_mutex_unlock(&L->lock);
return -1; // failure
}
从代码中可以看出,代码插入函数入口处获取锁,结束时释放锁。如果 malloc 失败(在极少的时候),会有一点小问题,在这种情况下,代码在插入失败之前,必须释放锁。
我们调整代码,让获取锁和释放锁只环绕插入代码的真正临界区(缩小临界区)。前面的方法有效是因为部分工作实际上不需要锁,假定 malloc()是线程安全的,每个线程都可以调用它,不需要担心竞争条件和其他并发缺陷。只有在更新共享列表时需要持有锁。下面展示了这些修改的细节。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
void List_Init(list_t *L)
{
L->head = NULL;
pthread_mutex_init(&L->lock, NULL);
}
void List_Insert(list_t *L, int key)
{
// synchronization not needed
node_t *new = malloc(sizeof(node_t));
if (new == NULL)
{
perror("malloc");
return;
}
new->key = key;
// just lock critical section
pthread_mutex_lock(&L->lock);
new->next = L->head;
L->head = new;
pthread_mutex_unlock(&L->lock);
}
int List_Lookup(list_t *L, int key)
{
int rv = -1;
pthread_mutex_lock(&L->lock);
node_t *curr = L->head;
while (curr)
{
if (curr->key == key)
{
rv = 0;
break;
}
curr = curr->next;
}
pthread_mutex_unlock(&L->lock);
return rv; // now both success and failure
}
扩展链表
手锁(hand-over-hand locking,也叫作锁耦合,lock coupling)
每个结点都有一个锁,替代之前整个链表一个锁。遍历链表的时候,首先抢占下一个结点的锁,然后释放当前结点的锁。这样多个线程可以独立访问不同的区域,减少冲突。
它增加了链表操作的并发程度。但是实际上,在遍历的时候,每个结点获取锁、释放锁的开销巨大,很难比单锁的方法快。
并发队列
Michael 和 Scott 的并发队列:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
typedef struct __node_t
{
int value;
struct __node_t *next;
} node_t;
typedef struct queue_t
{
node_t *head;
node_t *tail;
pthread_mutex_t headLock;
pthread_mutex_t tailLock;
} queue_t;
void Queue_Init(queue_t *q)
{
// tmp是假结点
node_t *tmp = malloc(sizeof(node_t));
tmp->next = NULL;
q->head = q->tail = tmp;
pthread_mutex_init(&q->headLock, NULL);
pthread_mutex_init(&q->tailLock, NULL);
}
void Queue_Enqueue(queue_t *q, int value)
{
node_t *tmp = malloc(sizeof(node_t));
assert(tmp != NULL);
tmp->value = value;
tmp->next = NULL;
pthread_mutex_lock(&q->tailLock);
q->tail->next = tmp;
q->tail = tmp;
pthread_mutex_unlock(&q->tailLock);
}
int Queue_Dequeue(queue_t *q, int *value)
{
pthread_mutex_lock(&q->headLock);
node_t *tmp = q->head;
node_t *newHead = tmp->next;
// 如果是假结点,则视为空
if (newHead == NULL)
{
pthread_mutex_unlock(&q->headLock);
return -1; // queue was empty
}
*value = newHead->value;
q->head = newHead;
pthread_mutex_unlock(&q->headLock);
free(tmp);
return 0;
}
有两个锁,一个负责队列头,另一个负责队列尾。这两个锁使得入队列操作和出队列操作可以并发执行,因为入队列只访问 tail 锁,而出队列只访问 head 锁。
并发散列表
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
#define BUCKETS (101)
typedef struct hash_t
{
list_t lists[BUCKETS];
} hash_t;
void Hash_Init(hash_t *H)
{
int i;
for (i = 0; i < BUCKETS; i++)
{
List_Init(&H->lists[i]);
}
}
int Hash_Insert(hash_t *H, int key)
{
int bucket = key % BUCKETS;
return List_Insert(&H->lists[bucket], key);
}
int Hash_Lookup(hash_t *H, int key)
{
int bucket = key % BUCKETS;
return List_Lookup(&H->lists[bucket], key);
}
本例的散列表使用我们之前实现的并发链表,性能特别好。每个散列桶(每个桶都是一个链表)都有一个锁,而不是整个散列表只有一个锁,从而支持许多并发操作。
这个简单的并发散列表扩展性(性能)极好,相较于单纯的链表。原因就是缩小了临界区,减少了不同线程间操作的冲突
小结
增加并发不一定能提高性能;有性能问题的时候再做优化。关于最后一点,避免不成熟的优化(premature optimization),对于所有关心性能的开发者都有用。我们让整个应用的某一小部分变快,却没有提高整体性能,其实没有价值