《Operating Systems: Three Easy Pieces》学习笔记(二十六) 常见并发问题
有哪些类型的缺陷
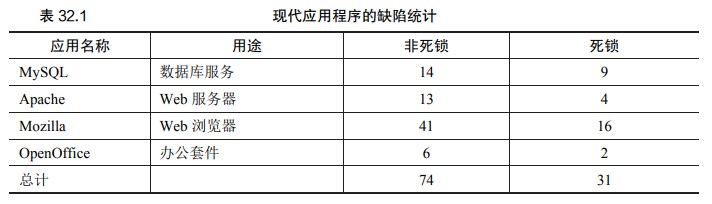
非死锁缺陷
违反原子性缺陷
违反了多次内存访问中预期的可串行性(即代码段本意是原子的,但在执行中并没有强制实现原子性)
1
2
3
4
5
6
7
8
9
10
11
Thread 1::
// 判断和赋值应该是原子性的
if (thd->proc_info)
{
...
fputs(thd->proc_info, ...);
...
}
Thread 2::
thd->proc_info = NULL;
通过加锁解决
违反顺序缺陷
两个内存访问的预期顺序被打破了(即 A 应该在 B 之前执行,但是实际运行中却不是这个顺序)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
Thread 1::
void init()
{
...
mThread = PR_CreateThread(mMain, ...);
...
}
Thread 2::
void mMain(...)
{
...
mState = mThread->State;
...
}
如果 mState = mThread->State 语句先执行,则 mThread 为空。通过加条件变量(或信号量)解决
死锁缺陷
死锁:
1
2
3
4
5
6
7
Thread 1:
lock(L1);
lock(L2);
Thread 2:
lock(L2);
lock(L1);
为什么发生死锁
复杂的依赖
以操作系统为例。
虚拟内存系统依赖文件系统才能从磁盘读到内存页;文件系统依赖虚拟内存系统申请一页内存,以便存放读到的块。封装
软件开发者一直倾向于隐藏实现细节,以模块化的方式让软件开发更容易。然而,模块化和锁不是很契合
以 Java 的 Vector 类和 AddAll()方法为例,我们这样调用这个方法:
1 2
Vector v1, v2; v1.AddAll(v2);
在内部,这个方法需要多线程安全,因此针对被添加向量(v1)和参数(v2)的锁都需要获取。假设这个方法,先给 v1 加锁,然后再给 v2 加锁。如果另外某个线程几乎同时在调用 v2.AddAll(v1),就可能遇到死锁。
产生死锁的条件
互斥:线程对于需要的资源进行互斥的访问(例如一个线程抢到锁)。持有并等待:线程持有了资源(例如已将持有的锁),同时又在等待其他资源(例如,需要获得的锁)。非抢占:线程获得的资源(例如锁),不能被抢占。循环等待:线程之间存在一个环路,环路上每个线程都额外持有一个资源,而这个资源又是下一个线程要申请的
预防死锁
循环等待
最直接的方法就是获取锁时提供一个全序(total ordering)(不同线程申请锁的顺序相同)。假如系统共有两个锁(L1 和 L2),那么我们每次都先申请 L1 然后申请 L2,就可以避免死锁。这样严格的顺序避免了循环等待,也就不会产生死锁。
更复杂的系统中不会只有两个锁,锁的全序可能很难做到。
偏序(partial ordering):安排锁的获取顺序并避免死锁。
提示:通过
锁的地址来强制锁的顺序当一个函数要抢多个锁时,我们需要注意死锁。比如有一个函数:
do_something(mutex_t *m1, mutex_t *m2),如果函数总是先抢 m1,然后 m2,那么当一个线程调用 do_something(L1, L2),而另一个线程调用 do_something(L2, L1)时,就可能会产生死锁。 为了避免这种特殊问题,聪明的程序员根据锁的地址作为获取锁的顺序。按照地址从高到低,或者从低到高的顺序加锁,do_something()函数就可以保证不论传入参数是什么顺序,函数都会用固定的顺序加锁。具体的代码如下:
1
2
3
4
5
6
7
8
if (m1 > m2) { // grab locks in high-to-low address order
pthread_mutex_lock(m1);
pthread_mutex_lock(m2);
} else {
pthread_mutex_lock(m2);
pthread_mutex_lock(m1);
}
// Code assumes that m1 != m2 (it is not the same lock)
在获取多个锁时,通过简单的技巧,就可以确保简单有效的无死锁实现。
持有并等待
将多个抢锁步骤也作为原子操作
1
2
3
4
5
lock(prevention);
lock(L1);
lock(L2);
...
unlock(prevention);
将 L1 和 L2 抢锁过程使用 prevention 锁合并为一个原子操作。这样可以保证线程持有其中任意一个锁时其他锁也不会被其他线程占用(无需等待其他线程释放)。但这么做可能会影响性能。
非抢占
解决非抢占就是要让线程能占用其他线程没在用的锁,不能占着茅坑不拉屎。主动去占用其他线程已经占用的锁不可能实现,需要让线程能认识到自己占着锁也没用,找机会主动释放一次
1
2
3
4
5
6
top:
lock(L1);
if (trylock(L2) == -1) {
unlock(L1);
goto top;
}
假设线程要同时拥有 L1 和 L2 才能继续,获得 L1 后尝试获取 L2,如果失败就解锁 L1,重新开始。
需要加一定的随机延迟,防止活锁(livelock)(双方都不停放弃锁)。
类似于数据库中的事务和回滚
互斥
Herlihy 提出了设计各种无等待(wait-free)数据结构的思想,通过强大的硬件指令,我们可以构造出不需要锁的数据结构。
*address 的值等于 expected 值时,将其赋值为 new,这是个硬件提供的原子操作–比较并交换(compare-and-swap)指令:
1
2
3
4
5
6
7
8
9
int CompareAndSwap(int *address, int expected, int new)
{
if (*address == expected)
{
*address = new;
return 1; // success
}
return 0; // failure
}
假定我们想原子地给某个值增加特定的数量:
1
2
3
4
5
6
7
8
9
10
11
12
void AtomicIncrement(int *value, int amount)
{
do
{
int old = *value;
} while (CompareAndSwap(value, old, old + amount) == 0);
/** 无同步操作
int old = *value;
*value = old + amount;
*/
}
一个更复杂的例子:链表插入。这是在链表头部插入元素的代码:
1
2
3
4
5
6
7
8
void insert(int value)
{
node_t *n = malloc(sizeof(node_t));
assert(n != NULL);
n->value = value;
n->next = head;
head = n;
}
通过加锁解决同步:
1
2
3
4
5
6
7
8
9
10
void insert(int value)
{
node_t *n = malloc(sizeof(node_t));
assert(n != NULL);
n->value = value;
lock(listlock); // begin critical section
n->next = head;
head = n;
unlock(listlock); // end of critical section
}
用比较并交换指令(compare-and-swap)来实现插入操作:
1
2
3
4
5
6
7
8
9
10
void insert(int value)
{
node_t *n = malloc(sizeof(node_t));
assert(n != NULL);
n->value = value;
do
{
n->next = head;
} while (CompareAndSwap(&head, n->next, n) == 0);
}
这段代码,首先把 next 指针指向当前的链表头(head),然后试着把新结点交换到链表头。但是,如果此时其他的线程成功地修改了 head 的值,这里的交换就会失败,导致这个线程根据新的 head 值重试。
通过调度避免死锁
只要 T1 和 T2 (需要同一个锁的线程)不同时运行,就不会产生死锁。但这样就失去了并发性
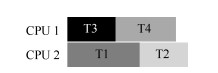
检查和恢复
最后一种常用的策略就是允许死锁偶尔发生,检查到死锁时再采取行动。
提示:不要总是完美(TOM WEST 定律)
Tom West 是经典的计算机行业小说《Soul of a New Machine》的主人公,有一句很棒的工程格言:“不是所有值得做的事情都值得做好”。
如果坏事很少发生,并且造成的影响很小,那么我们不应该去花费大量的精力去预防它。当然,如果你在制造航天飞机,事故会导致航天飞机爆炸,那么你应该忽略这个建议。
很多数据库系统使用了死锁检测和恢复技术。死锁检测器会定期运行,通过构建资源图来检查循环。当循环(死锁)发生时,系统需要重启。如果还需要更复杂的数据结构相关的修复,那么需要人工参与。