《Operating Systems: Three Easy Pieces》学习笔记(三十五) 日志结构文件系统
在 20 世纪 90 年代早期,由 John Ousterhout 教授和研究生 Mendel Rosenblum 领导的伯克利小组开发了一种新的文件系统,称为日志结构文件系统(LFS)。他们这样做的动机是基于以下观察:
内存大小不断增长。
随着内存越来越大,可以在内存中
缓存更多数据。随着更多数据的缓存,磁盘流量将越来越多地由写入组成,因为读取将在缓存中进行处理。因此,文件系统性能很大程度上取决于写入性能。随机 I/O 性能与顺序 I/O 性能之间存在巨大的差距,且不断扩大:传输带宽每年增加约 50%~ 100%。
寻道和旋转延迟成本
下降得较慢,可能每年 5%~ 10%。因此,如果能够以顺序方式使用磁盘,则可以获得巨大的性能优势,随着时间的推移而增长。现有文件系统在许多常见工作负载上表现不佳。
例如,
FFS会执行大量写入,以创建大小为一个块的新文件:一个用于新的 inode,一个用于更新 inode 位图,一个用于文件所在的目录数据块,一个用于目录 inode 以更新它,一个用于新数据块,它是新文件的一部分,另一个是数据位图,用于将数据块标记为已分配。因此,尽管 FFS 会将所有这些块放在同一个块组中,但 FFS 会导致许多短寻道和随后的旋转延迟,因此性能远远低于峰值顺序带宽。文件系统不支持 RAID。
例如,RAID-4 和 RAID-5 具有
小写入问题(small-write problem),即对单个块的逻辑写入会导致 4 个物理 I/O 发生。现有的文件系统不会试图避免这种最坏情况的 RAID 写入行为。
理想的文件系统会专注于写入性能,并尝试利用磁盘的顺序带宽。此外,它在常见工作负载上表现良好,这种负载不仅写出数据,还经常更新磁盘上的元数据结构。最后,它可以在 RAID 和单个磁盘上运行良好。
引入的新型文件系统 Rosenblum 和 Ousterhout 称为 LFS,是日志结构文件系统(Log-structured File System)的缩写。写入磁盘时,LFS 首先将所有更新(包括元数据!)缓冲在内存段中。当段已满时,它会在一次长时间的顺序传输中写入磁盘,并传输到磁盘的未使用部分。LFS 永远不会覆写现有数据,而是始终将段写入空闲位置。由于段很大,因此可以有效地使用磁盘,并且文件系统的性能接近其峰值。
按顺序写入磁盘
如何将文件系统状态的所有更新转换为对磁盘的一系列顺序写入?
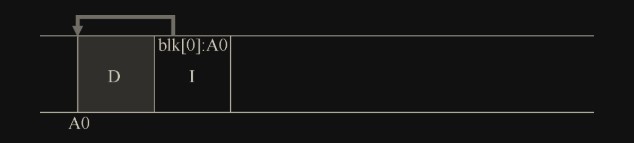
当用户写入数据块时,不仅是数据被写入磁盘;还有其他需要更新的元数据(metadata)。在这个例子中,让我们将文件的 inode(I)也写入磁盘,并将其指向数据块 D。写入磁盘时,数据块和 inode 看起来像这样(注意 inode 看起来和数据块一样大,但通常情况并非如此。在大多数系统中,数据块大小为 4KB,而 inode 小得多,大约 128B)
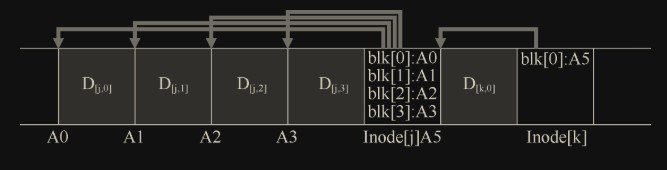
下面是一个例子,其中 LFS 将两组更新缓冲到一个小段中。实际段更大(几 MB)。第一次更新是对文件 j 的 4 次块写入,第二次是添加到文件 k 的一个块。然后,LFS 立即将整个七个块的段提交到磁盘。这些块的磁盘布局如下:
顺序而高效地写入
为了防止过于频繁的写入导致的旋转延迟(即便是在同一磁道进行多次写入也会有旋转到写入点带来的延迟),LFS 使用了一种称为写入缓冲(write buffering)的古老技术。在写入磁盘之前,LFS 会跟踪内存中的更新。收到足够数量的更新时,会立即将它们写入磁盘, 从而确保有效使用磁盘。
LFS 一次写入的大块更新被称为段(segment),也就是对写入进行分组的大块
下面是一个例子,其中 LFS 将两组更新缓冲到一个小段中。实际段更大(几 MB)。第一次更新是对文件 j 的 4 次块写入,第二次是添加到文件 k 的一个块。然后,LFS 立即将整个七个块的段提交到磁盘。这些块的磁盘布局如下:
要缓冲多少
可以根据定位开销计算来判断,通过增大缓存来摊销定位开销,来达到最大效率(最优效率,不可能 100%,一般就 90%)
通过间接解决方案:inode 映射
由于 inode 现在分布在磁盘各个随机位置,需要方法找到 inode 块
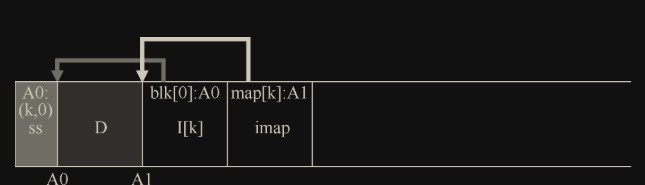
LFS 的设计者通过名为 inode 映射(inode map,imap)的数据结构,在 inode 号和 inode 之间引入了一个间接层(level of indirection)。imap 是一个结构,它将 inode 号作为输入,并生成最新版本的 inode 的磁盘地址。
为了防止 imap 和 inode 块过远导致的寻道延迟,将完整的 imap 也每次都重新写到 inode 旁边。LFS 在磁盘上只有这样一个固定的位置,称为检查点区域(checkpoint region,CR)。检查点区域包含指向最新的 inode 映射片段(imap)的指针(即地址),因此可以通过首先读取 CR 来找到最新的 inode 映射片段。检查点区域仅定期更新(例如每 30s 左右),因此性能不会受到影响。

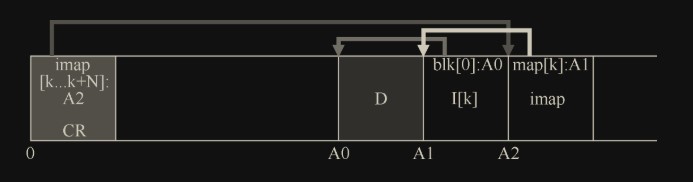
在该图中,imap 数组存储在标记为 imap 的块中,它告诉 LFS,inode k 位于磁盘地址 A1。接下来,这个 inode 告诉 LFS 它的数据块 D 在地址 A0。CR 存储了最新的 imap 的位置。
从磁盘读取文件:回顾
从磁盘读取文件时必须发生的事情:假设从内存中没有任何东西开始。我们必须读取的第一个磁盘数据结构是检查点区域。检查点区域包含指向整个 inode 映射的指针(磁盘地址),因此 LFS 读入整个 inode 映射并将其缓存在内存中。在此之后,当给定文件的 inode 号时,LFS 只是在 imap 中查找 inode 号到 inode 磁盘地址的映射,并读入最新版本的 inode。要从文件中读取块,此时,LFS 完全按照典型的 UNIX 文件系统进行操作,方法是使用直接指针或间接指针或双重间接指针。在通常情况下,从磁盘读取文件时,LFS 应执行与典型文件系统相同数量的 I/O,整个 imap 被缓存,因此 LFS 在读取过程中所做的额外工作是在 imap 中查找 inode 的地址。
目录如何
目录结构与传统的 UNIX 文件系统基本相同,因为目录只是(名称,inode 号)映射的集合。例如,在磁盘上创建文件时,LFS 必须同时写入新的 inode,一些数据,以及引用此文件的目录数据及其 inode。请记住,LFS 将在磁盘上按顺序写入(在缓冲更新一段时间后)。因此,在目录中创建文件 foo,将导致磁盘上的以下新结构:
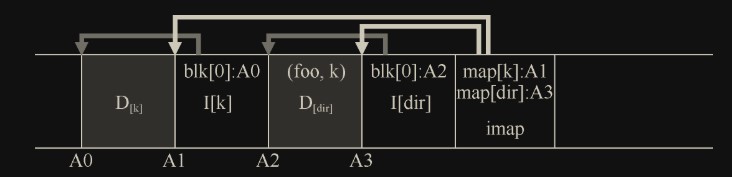
inode 映射的片段包含目录文件 dir 以及新创建的文件 foo 的位置信息。因此,访问文件 foo(具有 inode 号 f)时,你先要查看 inode 映射(通常缓存在内存中),找到目录 dir 的 inode 的位置 A3。然后读取目录的 inode,它给你目录数据的位置 A2。读取此数据块为你提供名称到 inode 号的映射(foo,k)。然后再次查阅 inode 映射,很到 inode 号 k 的位置 A1,最后在地址 A0 处读取所需的数据块。
inode 映射还解决了 LFS 中存在的另一个严重问题,称为递归更新问题(recursive update problem)。每当更新 inode 时,它在磁盘上的位置都会发生变化。如果我们不小心,这也会导致对指向该文件的目录的更新,然后必须更改该目录的父目录,依此类推,一路沿文件系统树向上。
一个新问题:垃圾收集
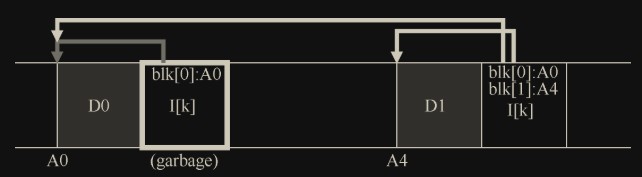
LFS 会在整个磁盘中分散旧版本的文件结构。这些旧版本称为垃圾(garbage)。
修改 D0 产生 D0 所在块和 inode 号为 k 所在块两个垃圾:

添加 D1 产生 inode 号为 k 所在块一个垃圾:
可以保留那些旧版本并允许用户恢复旧文件版本(例如,当他们意外覆盖或删除文件时,这样做可能非常方便)。这样的文件系统称为版本控制文件系统(versioning file system),因为它跟踪文件的不同版本。
LFS 只保留文件的最新活版本。因此(在后台),LFS 必须定期查找文件数据, 索引节点和其他结构的旧的死版本,并清理(clean)它们,也就是垃圾收集(garbage collection)。
为了防止垃圾收集产生大量碎片(小而离散的空闲块),需要有碎片整理功能。LFS 清理程序按段(见顺序而高效地写入中对段的定义)工作,从而为后续写入清理出大块空间。基本清理过程的工作原理如下:LFS 清理程序定期读入许多旧的(部分使用的)段,确定哪些块在这些段中存在,然后写出一组或多组新的段,只包含其中活着的块,从而释放旧块用于写入(干净的段)。
确定块的死活
在段的头部设立称为段摘要块(segment summary block),信息包括段中的每一块属于哪个文件的哪一块。如位于 A0 的块 D 属于文件 k 的第 0 块,就有记录 A0:(k,0)。通过查找段摘要块中的记录,再比对该文件内的块目前的实际位置(通过最新 imap 找到 k 的 inode,找对应块序号的块的位置),就能判断当前块是否是死块。段摘要块也是只写一次的,和其他块一起从内存缓冲段中写入。
LFS 使用版本号方式取代摘要。LFS 在文件被截断或删除时,会增加其版本号(version number),并在 imap 中记录新版本号。LFS 可以简单地通过将磁盘版本号与 imap 中的版本号进行比较,跳过上述较长的检查, 从而避免额外的读取。
策略问题:要清理哪些块,何时清理
在最初的 LFS 论文中,作者描述了一种试图分离冷热段的方法。热段是经常覆盖内容的段。因此,对于这样的段,最好的策略是在清理之前等待很长时间,因为越来越多的块被覆盖(在新的段中),从而被释放以供使用,这种段即使清理了,在新段中也会被很快覆盖,所以不需要过于频繁的清理。相比之下,冷段可能有一些死块,但其余的内容相对稳定。因此,作者得出结论,应该尽快清理冷段,延迟清理热段,并开发出一种完全符合要求的试探算法。但是,与大多数政策一样,这只是一种方法,当然并非“最佳”方法。后来的一些方法展示了如何做得更好。
崩溃恢复和日志
利用日志系统,写入段后需要加检查点表示写入完成(把检查点理解为游戏中的存档点),检查点依次写在固定的 log 段中。为了保证检查点的一致性,需要在检查点的头尾加上一致的时间戳。重启时需要读取最新时间戳的完整(头尾都有时间戳且一致)的检查点,从中可以获取最新的段的位置,从而找到最新的 imap。
如果是异常复位,检查点后的数据就会丢失,如果有必要可以尝试读取最后一个检查点对应的段的后一个段(这个段可能也会包含在检查点中,名为将要写入的下一个段),也就是没写完的段,尝试恢复已写入的数据。
小结
LFS 引入了一种更新磁盘的新方法。LFS 总是写入磁盘的未使用部分,然后通过清理回收旧空间,而不是在原来的位置覆盖文件。这种方法在数据库系统中称为影子分页(shadow paging),在文件系统中有时称为写时复制(copy-on-write),可以实现高效写入,因为 LFS 可以将所有更新收集到内存的段中,然后按顺序一起写入。
这种方法的缺点是它会产生垃圾。旧数据的副本分散在整个磁盘中,如果想要为后续使用回收这样的空间,则必须定期清理旧的数据段。
一些现代商业文件系统,包括 NetApp 的 WAFL、Sun 的 ZFS 和 Linux btrfs,采用了类似的写时复制方法来写入磁盘,因此 LFS 的知识遗产继续存在于这些现代文件系统中。特别是,WAFL 通过将清理问题转化为特征来解决问题。通过快照(snapshots)提供旧版本的文件系统,用户可以在意外删除当前文件时,访问到旧文件。