Transformer 笔记
RNN 介绍
RNN 实际完成的就是从一个序列到另一个序列。对于自然语言,序列的单位就是一个词,序列中的某个词 t 有一个隐藏状态 $h_t$ ,它是由 t 本身和前一个词的隐藏状态 $h_{t-1}$ 作为参数来生成的,所以该隐藏状态能够包含之前所有词的信息(上下文)。
缺点:
- 训练时较难进行并行化处理,无法充分利用 GPU。
- 当上下文信息很长时,隐藏状态需要占用大量内存空间。
架构
自然语言翻译一般使用 encoder-decoder 模型。
encoder 就是将一个序列 $(x_1,x_2,…,x_n)$ 转为计算机可以识别的 Tensor 序列 $ z = (z_1,z_2,…,z_n)$。比如 $x_t$ 是一个英文单词,$z_t$ 就是和该单词关联的一个向量。
decoder 就是将 encoder 的输出作为其输入,转为 $(y_1,y_2,…,y_m)$ 序列。长度可能和输入序列不同,比如英文翻译为中文。
这样的模型也是 auto-regressive(自回归) 的。每一次的输出都会使用之前的输出作为输入。
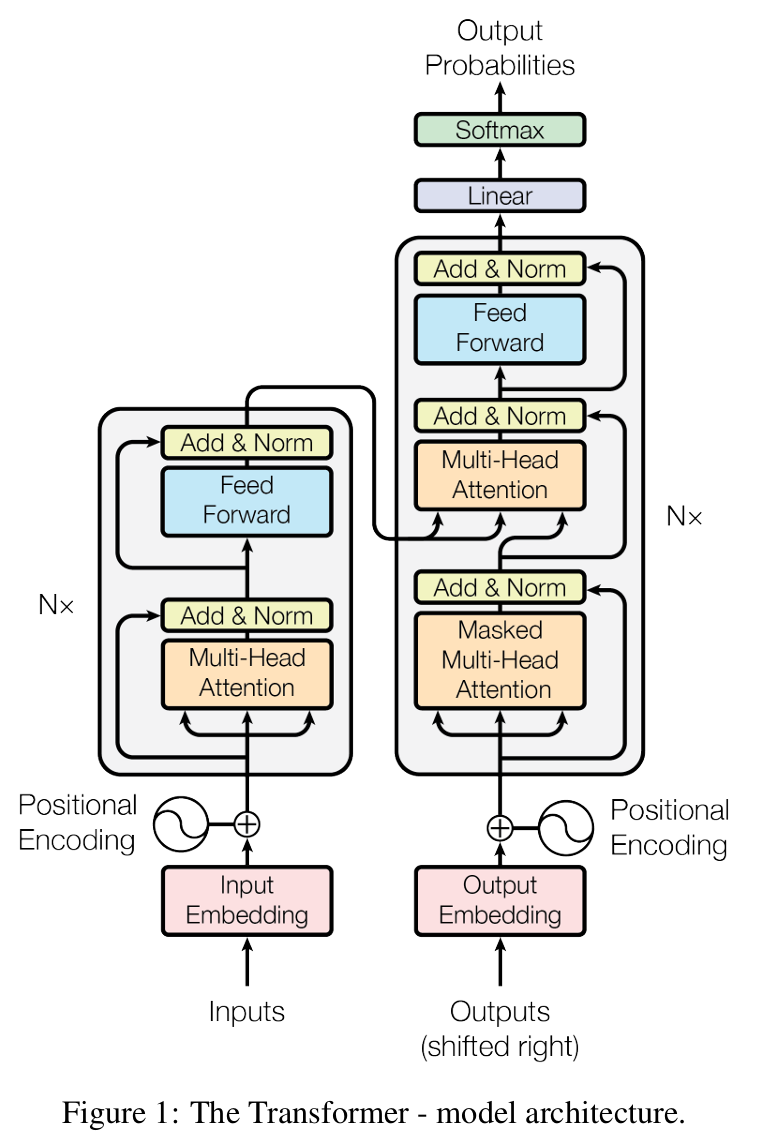
本架构图中,左边是 encoder ,右边是 decoder。注意到右边下面的 output 作为输入说明它是 auto-regressive 的。Nx 表示方框内的同样的层有 N 个。“Add & Norm” 层有一个输入是跳过它之前的层的,这个就是残差连接(residual connection)。
Encoder
简化的表示形式是 $LayerNorm(x + Sublayer(x))$。比如第一部分,Sublayer 就是 Multi-Head Attiontion 层,加上 x 表示是残差连接需要原始数据作为输入,这两个参数作为输入传递到 (Add & Norm) 层,上面一部分也是同理。
其中的 Normalization(标准化) 使用的是 LayerNorm 而不是 BatchNorm。
Normalization(标准化)是让一组数据减去其均值再除以标准差得到的,得到的结果就是均值为 0 ,标准差为 1 的一组数据。通过这种方式让每一层的输出都相对标准化,类似于应用间进行数据通信的 API。
BatchNorm 是将一个 batch 内不同样本间的同一个的特征进行标准化,而 LayerNorm 是将一个 batch 内同一个样本的所有特征进行标准化。
Decoder
decoder 相比于 Encoder 增加了一个 Masked Multi-Head Attention 层,该层用于实现 auto-regressive ,在推理阶段会用于处理之前的输出结果来作为输入。
在训练时,Decoder 的输入是训练集的数据(teacher forcing),而不是 Encoder 的输出,我们希望让其模拟在推理时将产生的输出作为输入的过程,所以增加一个 Mask 去遮盖后面的部分,避免其看到完整的训练集数据。
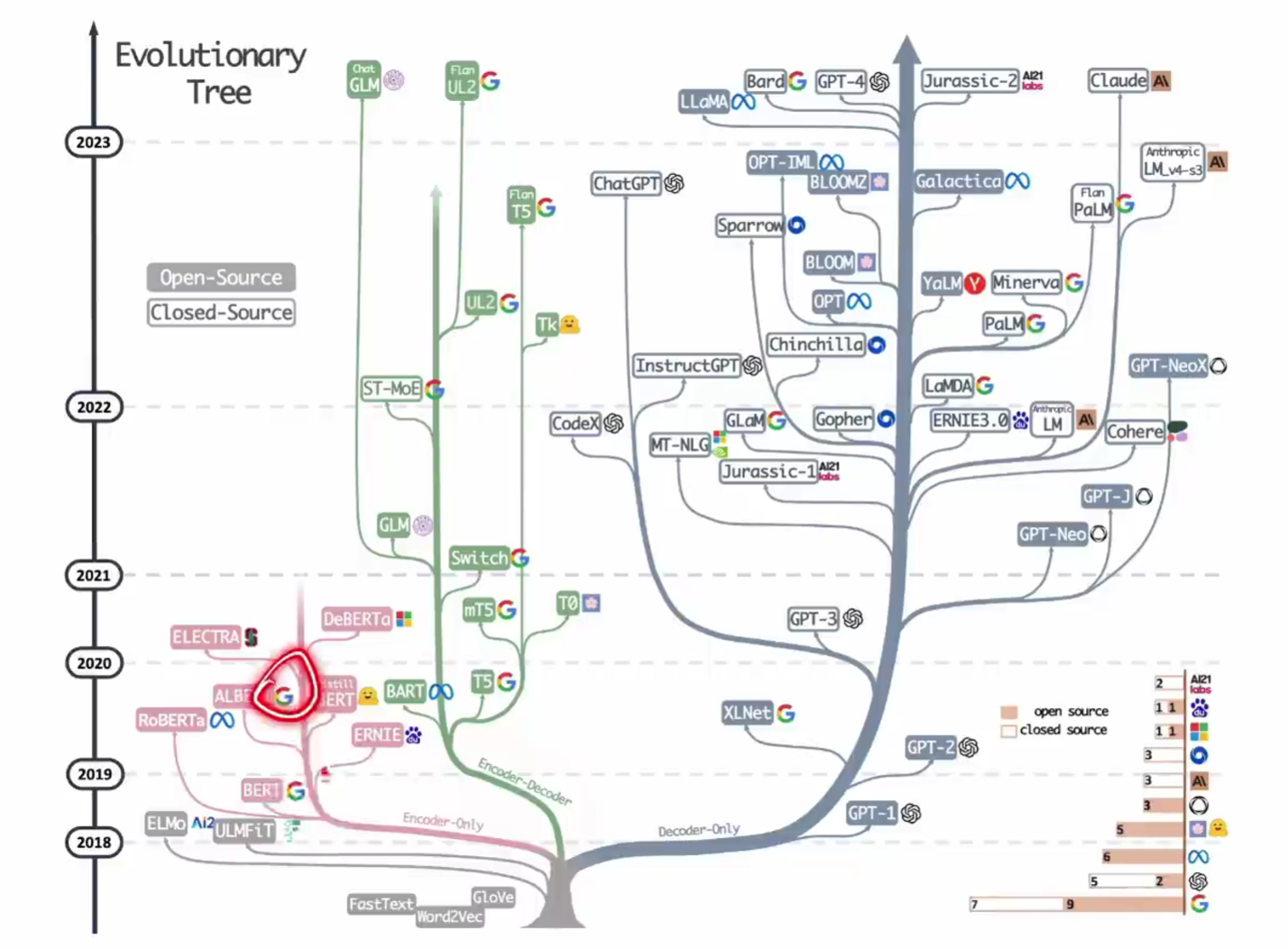
关于当前大模型使用的变种架构的情况如下,基本上都偏向于 Decoder-only 架构:
Attention
注意力函数需要一个 query 和 一组 key-value 作为输入,它会根据 query 和 key 的相似度作为对应的 value 的权重。不同的注意力函数的区别就是计算相似度的相似函数。
我们用 $h_t$ 表示某个 token 的相关信息,包含了该 token 以及其上下文,作为 attention 操作的原始输入数据,它可能是这样的 $[t_1,t_2,…,t_n]$,我们就假设表示的是第 2 个 token 的信息,除了它本身,它相关的上下文也包含在这个 $h_t$ 中。
然后 $h_t$ 会经过三个不同的投影矩阵,变为 $q_t$, $k_t$, $v_t$,它们来源相同,但目的的不同导致了它们的投影矩阵不同
每个 token 都同时扮演着三重角色:
- 当它”主动询问”时,它使用自己的 Q
- 当它”被其他词询问”时,它提供自己的 K 供匹配
- 当匹配成功时,它贡献自己的 V 作为价值信息
我们希望当前 token 的 q 和每个其他 token 的 key 做匹配:
- $q_t$: $[q_2,q_2,…,q_2]$(总是用第二个 token 的 query)
- $k_t$: $[k_1,k_2,…,k_n]$
- $v_t$: $[v_1,v_2,…,v_n]$
attention 匹配模式是一种模糊匹配,不是说 q 和 k 必须完全配对,一个 q 可能匹配好多 key,每个 key 的关联度(权重)不同。得到的结果是一个权重向量。
假设图书馆有一本名为《人工智能大模型》和《人工智能导论》的书,现在你进入图书馆打算问管理员:
- q: 将你的想法转变为自然语言
- $q_1$:“我要找一本人工智能导论的书籍,它在哪里?”
- $q_2$:“我要找一本人工智能大模型的书籍,它在哪里?”
- k: 图书管理员将书名和位置写在笔记本上,只要有人来问,他就看笔记本,回答位置
- $k_1$:“人工智能导论在第一排架子上”
- $k_2$:“人工智能大模型在第二排架子上”
- v: 书的实体,该信息并不适合用于被查询
- $v_1$:放在第一排架子上的那本书
- $v_2$:放在第二排架子上的那本书
每次查询,图书管理员根据一个 query 查询所有的 key,回答每个 key 对应的 value,因为图书管理员并不太懂人工智能专业,他听到书名会这么回答:“你要找的人工智能大模型大概率在第二排架子上(权重 0.9),不知道是不是你要找的那本,还有本类似的书,你可能要找的是那个,在第一排架子上。(权重 0.1)”。此时借书的那个人的“注意力”就会分散在两本书上:虽然他要找的是人工智能大模型,但人工智能导论这本书也值得关注下。
在上面的模型图中,下面的两个 Attention 层有三个输入,也就是 query、key、value,在 self-attention (自注意力)机制中这三个参数其实是原始输入序列的三份相同的复制。此时对于 query 中的一项,也就是原始序列的一个词,计算注意力函数时它和 key 中相同位置的自身相似度肯定最高,权重也最高,然后如果序列中还有其他相似度较高的词,也会被考虑进来(较高权重),最后每个 value 被附加对应的权重,实现了为序列中的每一个词附加同一个序列中其他它感兴趣的部分的信息。
公式如下:
\[Attention(Q,K,V)=softmax({QK^T\over \sqrt{d_k}})V\]权重指的其实就是“correlation(相关性)”,Attention 计算权重的方式就是点乘,也就是将 query 和 key 矩阵做点乘($QK^T$)。从本质上来说点乘是计算两个矩阵 correlation 的一种方式,还有其他很多方式,只不过 Transformer 综合考虑选择了点乘。这种关系和它们之间的距离形成反比,也就是距离越大,联系也会越小,所以除以了 d,也就是距离。softmax 将权重进行了归一化,让其分布在 (0,1) 之间且和为 1,方便计算。
这样,我们就得到了一个向量,也就是带有注意力的 token 序列。我们将其输入到一个 NN 中,得到一个输出。根据应用场景不同,可以制定不同的训练目标:
- 预测:使用原始数据右移一个词作为目标
架构图中上面的 Attention 层,它的 key ,value 来自于 Encoder 层,query 来自于下面的 Masked Multi-Head Attention 层。Encoder 和 Decoder 沟通的桥梁就是这个层。
Multi-Head Attention
将 query 、key 和 value 都投影到各自的 h 个低维空间中,再进行 Attention 操作,可以增加可学习的参数数量(变为 3 x h 倍)。投影的概念就是降低维度,比如三维物体的三视图就是降低一个维度的投影,通过 3 个二维图来展现三维物体。
通过在不同的维度分别计算 Attention 后再进行组合,有什么好处?首先以三视图举例子,在三维物体中的一个点,投影到三个平面上,会出现 3 个点,原来我们是去三维空间找两点(类比 query 和 key)的距离信息(类比 attention 计算 value 的权重的过程),现在是在三个平面上分别去找这 6 个点的距离信息($query_x$和$key_x$,$query_y$和$key_y$,$query_z$和$key_z$),而且我们会为每个平面分配权重,这样假设 y 平面上的两个点($query_y$和$key_y$)距离很远,而在其他平面上距离较近,但因为我们并不关心 y 平面也就是其权重较小,那么这样计算出来的两个点间的最终距离就会很小,符合我们的预期。换个说法就是分成多个通道去找特征。
每个 HEAD 平面表示的其实就是 token 之间的一种关系模式,对于自然语言的关系模式,举几个例子:
- 主题一致性:比如 “内存”、“硬盘” 都是电脑相关的,它们间的联系就大
- 主谓一致性:比如 “dogs” 和 “are” 相关性高,和 “is” 的就低。
MHA 中就会有一个 HEAD 表示主题关联度,另一个 HEAD 表示主谓关联度,以此类推。
Position-wise Feed-Forward Networks
Feed-Forward 层实际就是一个 MLP,它对一个附带了 attention 的 token(我们称其为隐藏状态) 进行 MLP 的计算得到一个新的 token。其输入是 attention 层的输出,而通过 attention 层的处理,token 已经被附加了整个原始序列中它感兴趣的部分(与之相关的部分),所以不需要像 RNN 一样把前一个词的 MLP 计算结果作为输入,只要每个词单独输入就行,没有任何依赖。
现有的 LLM 主要参数都在 Feed-Forward 层中,大模型之所以强大,就是将大量的知识都保存到了这个层中。而计算量主要集中在 Attention 层。当然不能忽略大参数量带来的内存拷贝问题,CPU 或 GPU 从内存读取数据到 cache 处理也是非常耗时的一个过程,所以 FFN 即使计算量不大,在训练和推理中的耗时也是较高的。随着大模型参数的增加,数据传输时间已经成为实际瓶颈。
speculative decoding
而且因为推理时只能一个一个 token 生成,不能并行处理,进一步降低了速度。为了提高推理速度,有一种思路是利用一个小模型先推理一遍,因为参数小,推理也很快,但质量不太行,这时候再让大模型进行 check,这个 check 过程和训练很像,都是已经有完整的输入后进行的,可以并行处理提高效率,check 主要做的事就是检查每个 token 和自己预测的是否相同,发现错误时就主动从错误的地方再重新生成一遍。因为可以并行,理想情况下,大模型 check 过程和生成一个 token 的时间就是一样的。
如果运气好,小模型输出就是正确的,这就大幅提高了效率。
如果小模型输出到中间开始后面全错了,大模型也会从错误的地方开始重新生成,然后让小模型从这里继续,不断交替,总时间有很大概率也是减少的。

- 绿色:小模型正确的
- 红色:小模型错误的
- 蓝色:大模型
当然这个小模型其实可以塞到大模型中,成为其独立的 heads,这样达到的效果也是一样的。
这种方式我们可以称为传统的 speculative decoding,后面出现了 MTP 技术,从训练阶段就考虑到了多 token 预测,效果也会更好。
Embeddings and Softmax
Embedding 就是将输入数据映射成计算机可以进行计算的向量,这里固定每个词映射成 512 长度的向量。
Positional Encoding
attention 机制带来的一个问题是其注意力信息是位置无关的,因为权重信息中没有位置信息,这也导致在翻译过程中将输入的词任意打乱,其注意力信息也是相同的,即使语义已经发生了很大的变化。
此时该模型在输入中加入了位置信息来解决该问题。
应用:预测
Transformer 可以用来做 token 预测,此时只需要 Decoder 就行,即 Decoder-only
训练
我们为输入
I love you
添加一个 <s> 标签(right shift 一个 token):
<s> I love you
将输出设置为原始的输入:
I love you
然后就能从 <s> 推理出 I,从 I 推理出 love。得益于 Attention 机制的并行性,训练过程中,一个句子的每个单词的推理可以并行执行(因为训练中输入是确定的,不是从上一次的输出得到的),然后统一计算 loss 并回归。
为了实现预测,我们不能将输入中该单词之后的单词信息提供给注意力机制,比如 love 的注意力只能看到 I 和 <s> ,但不能看到 you,所以训练时在处理每个单词的注意力时会给句子添加对应的掩码。
推理
在上面的训练过程中,因为每个 token 都已知,可以并行的附加 attention,它们的预测结果也是已知的,可以并行的进行推理得到结果,整个训练过程中对于所有 token 都是并行的。
推理和训练过程不同,必须一个一个 token 生成,生成完的 token 作为下一次的输入,所以并行性并不如训练过程。比如推理时只能由 I 预测 have,然后才能由 I have 生成 attention,然后预测 a 。
这样还会有一个训练中不存在的问题,训练过程每个 token 的推理过程都是独立的,中间有个 token 预测错没什么关系。但推理过程中,一个 token 预测错,后面就全错了,这也是预测这个应用的一个问题。
应用:翻译
Transformer 可以用来做机器翻译,这也是 Google 提出 transformer 时想要其解决的主要问题。这会利用到 Encoder-Decoder 架构。