DeepSeek R1 笔记
特点
DeepSeek R1 的两个关键贡献:
- Post-Training: Large-Scale Reinforcement Learning on the Base Model(改进的 Post-Training 方式)
- Distillation: Smaller Models Can Be Powerful Too(小模型同样可以做到很优秀)
学习方式概述
- supervised learning(监督学习) 在有标注的样本上学习,也就是需要外部给出学习的目标,缺点是对任务的泛化能力弱,一般只能解决一个问题,对于其没见过的问题就抓瞎了(二次训练或推理都是如此)。比如判断邮件是否是垃圾邮件的任务。
- unsupervised learning(无监督学习) 不需要外部给出目标的学习。大模型上用的比较多的 Self-Supervised Learning(自监督学习)就是属于 unsupervised learning,比如大模型训练中的 next token prediction,就是将输入进行偏移作为目标进行训练的方式,
reinforcement learning(强化学习) 由模型经过多步计算,得出结果,根据该最终结果的好坏来给予之前所有经过的步骤奖励或惩罚,重点是多步后判断,所以对模型的中间动作干涉比较少,让其可以自由发挥。也不像 supervised learning 需要为每一步都提供目标,只需要给定一个简单的(或者可以称为稀疏的)、最终的目标即可。
模型的行为可以分为两类,以下棋为例:
- policy based: 模拟下棋的动作,模型每次格局当前棋局预测下次下的位置,输出的是每个可以下的棋位的概率分布,可以理解为“玩家”。推理时直接下在概率最大的棋位就行。
- value based: 模型对输入的棋局做判断,比如判断黑棋是否处于优势,可以理解为“教练”。对于这种方式,可以随机选取下一步棋的位置,然后让其判断好不好,好就下,不好就换一个。
在 DeepMind 的 Alpha GO 中对棋局后续发展的预测就利用了这两个算法,这里做下举例。首先要知道遍历棋局后续的所有可能情况是不可能的,围棋的棋盘太大了,所有用 policy based 模型计算下一步棋要下的位置(这里其实使用了 supervised learning 训练的 policy based 模型从棋谱中获取最优下法,并非从长盘考虑),然后用 value based 判断这样下完后的胜率(这一步使用了 reinforcement learning),如果胜率大于一定的值,则继续沿着该路径预测后面的多步棋,如果胜率小于一定值,则直接放弃该分支,此时 reinforcement learning 就发力了,直接否定了棋谱的下法,很可能下出人类从来没考虑过的下法。通过这两个模型结合就能大大减少搜索分支的数量,也就能充分利用计算量计算胜率更高的下法。有趣的是在后来与李世石的对战中,李世石下出了一个人类棋谱中没有的下法,直接让 Alpha GO 宕机了,通过这件事,Alpha GO 团队发现学习人类的棋谱是没有必要的,在后面的迭代版本优化中去掉了 supervised learning 模型,相当于完全放弃了人类棋谱,性能得到了提高。
reward 的特点:
- spare(稀疏的):reward 和输入矩阵并不是一一对应的,比如输入一个句子,reward 只有好与坏的 bool 值。
- reward根据其可验证性分为两类:
- verifiable reward: 确定的,比如游戏/数学/编程,存在唯一最优答案
- unverifiable reward: 主观的,比如创意写作,有些人觉得写得好,有些人认为不好,没有明确答案。这时候可以根据人类标注数据单独训练一个 reward model 出来,来作为 reward 判断依据
总结下 reinforcement learning 和 supervised learning 区别,supervised learning 需要明确的目标监督每一步的训练结果,而 reinforcement learning 只在最后给出目标,中间的过程不受监督,仅在输出的地方与目标做比对。
reinforcement learning 的另一大优势是会去尝试更多的可能性,以下棋为例,它不像 supervised learning 一样学习既有的棋谱,而是自己去探索每一步棋的位置,有时候甚至能出奇制胜,下出比棋谱更精妙的棋。
减少人类的思维范式
人们发现为模型添加人类的思维范式(structure),在训练初期可以提高模型的性能,但最终会收敛,其实这就说明人类的思维范式限制了模型的进一步优化。而不添加人类的思维范式,一开始其效率较低,当计算量达到一定程度时,其效率突然会大幅增加。
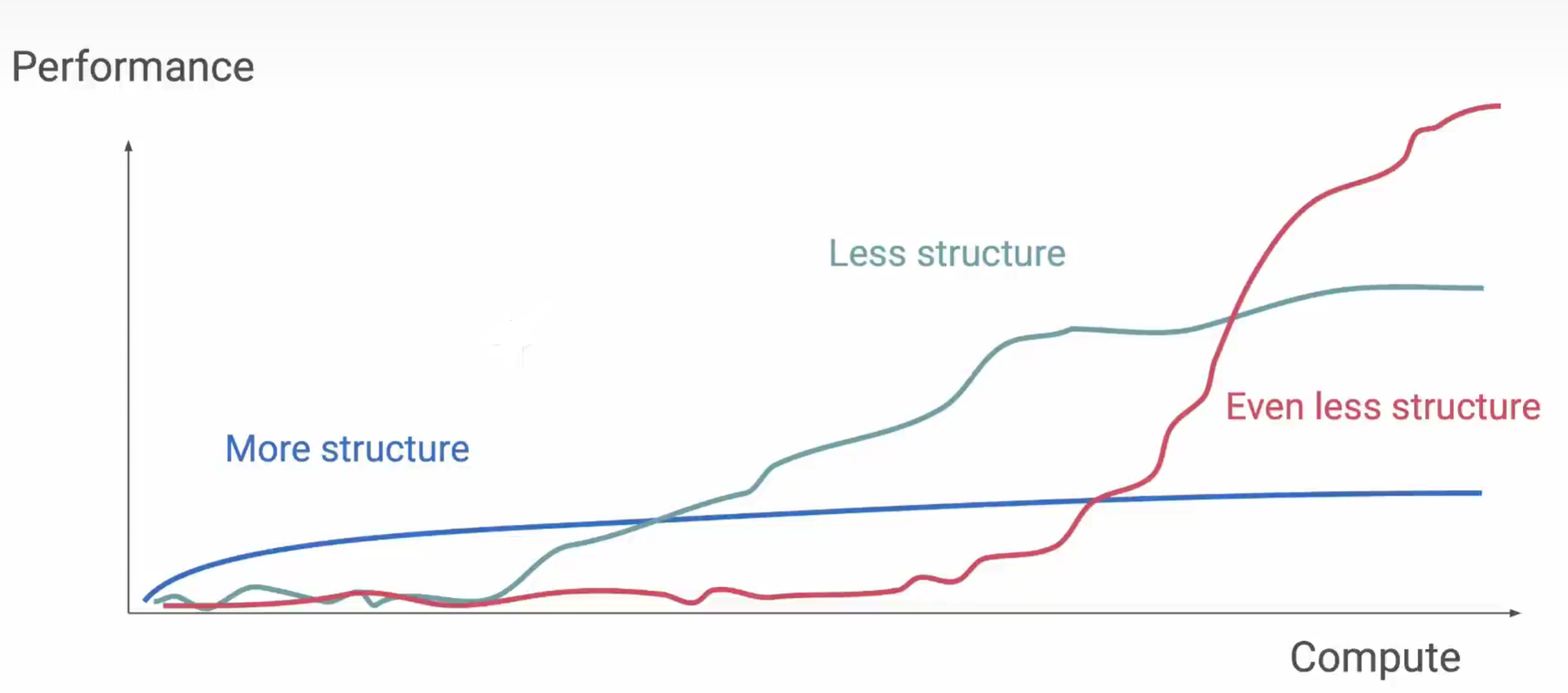
从上文提到的 Alpha GO 的进化过程中也能发现同样的结论,当抛弃了人类棋谱后,Alpha GO 终于突破了人类的极限。
在后续的研究中,人们开始更加关注 reinforcement learning(RL) 相关的技术。
scale up
GPT 的研发人员一开始就选用了 Decoder-only transformer 架构,并相信只要模型的规模足够大,就能超过 Encoder-Decoder 或是 Encoder-only架构,仿佛永远不会达到上限。
所以有了 scale up 概念,scale up 的意思是扩大规模。对模型性能的提高的一大路径就是 scale up,相关的技术有:提高 GPU 的算力(更多轮次的训练)、增加输入的数据量、增加神经网络的参数量。
RLHF 训练范式
当大模型的 pre-train 完成后,为了让模型能听懂人类指令,需要通过专门的训练去引导模型。这个步骤也称为 post-train。
OpenAI 提出了RLHF(Reinforcement Learning from Human Feedback,基于人类反馈的强化学习)训练范式,和 Alpha GO 很像,分为三步:
- Supervised Fine-Tuning(SFT,监督微调):大模型用 supervised learning 训练人类的问答数据,让大模型具有基本的回答问题的能力
- 训练一个包含人类偏好的 reward model
- 大模型用 policy 方式产生结果,用 reinforcement learning 方式使用 reward model 去验证结果(value based),并通过结果调整大模型的参数。这个过程被称为 PPO
该范式存在一定的问题,首先就是 reward model 的设计非常的难,reward model 如果不能正确表示人类偏好,就会被大模型钻空子(reward hacking),使用不正确的方式提高 reward 分数,这种方式反而不是人类预期的。
还记得以前在编程网站刷编程题的时候,有时就会想着钻空子,因为大概能猜到答案的评判逻辑,比如评判系统只判断程序的输出是否为 (1,3,5),此时写个代码直接 return (1,3,5),甚至因为运行时间极短,内存占用极低,能获得最高评价。这其实就是一种 reward hacking,用错误的方式却获得了很高的 reward,大模型在钻空子方面的能力可比人类强多了,毕竟它能快速遍历各种可能的情况。
Chain-of-Thought(CoT)
没有思维链的模型训练中,仅仅是让模型学习问题和答案,而思维链的思想是在模型训练中加入思考过程:
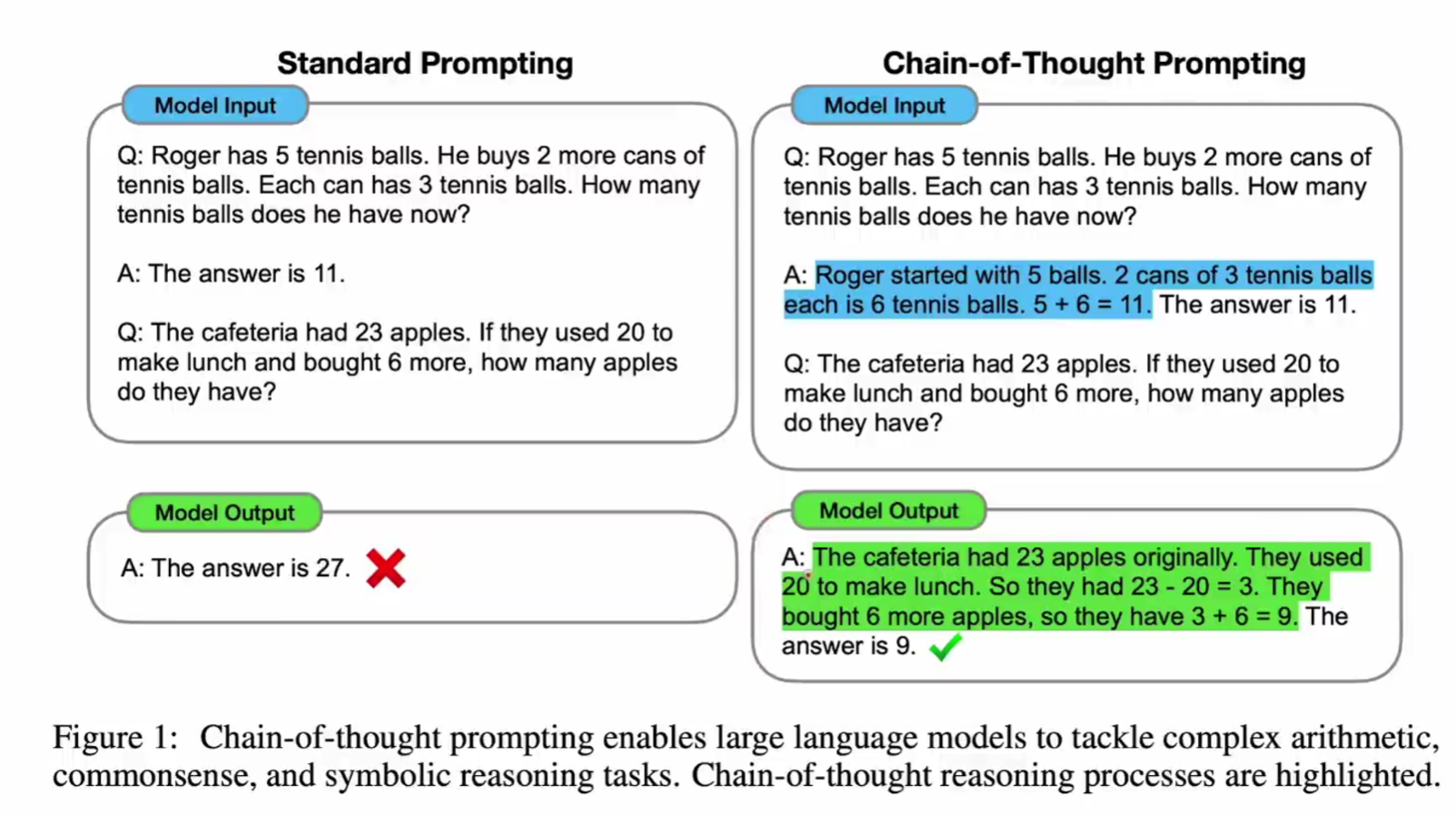
让模型学习思考过程的本质其实和之前的训练没什么区别,核心也是 next token predication,只不过以前是预测 answer,现在是预测 thought。
所以其实这并不意味着模型学会了思考,它依然是在复述训练时教给它的数据,但换个角度考虑,人类思考时不也是在重复老师的解题思路吗,考试时遇到学到过的问题会做,遇到没学过的问题就不会了,人类思考的本质有没有可能就是和大模型的方式一样呢?
Rule-based Reward
因为之前提到的 RLHF 的 reward hacking 问题,DeepSeek R1 没有使用 reward model 做 RL,取而代之的是使用一种 Rule-based reward 机制,主要分为两类:
- Accuracy rewords: 用与判断结果是否正确。比如判断数学问题的答案是否正确,代码问题的代码是否能通过编译器编译。这一步骤比较简单,不需要单独训练一个大的 reward model。
- Format rewords: 用于判断结果是否符合格式,比如要求 CoT 训练时其输出必须包含在
<think></think>标签内
DeepSeek R1 训练过程
大致和 openAI 提出的 RLHF 训练范式相同:
在 DeepSeek V3 的基础上再做 SFT,使用 reasoning data 和 non-reasoning data 混合的数据进行训练。
- reasoning data 的产生方式是先由上一次训练完的模型(第一次训练时上一次的模型就是V3,后面几次就是上次训练完的 R1)产生一些 CoT 数据,但是这些数据肯定有很多是错误的,利用 DeepSeek V3 作为 verifier 模型对他们做筛选(左脚踩右脚上天),就能得到一批较好的 reasoning data,优势是完全不用人类做筛选,大大降低了工作量。
- non-reasoning data 和 V3 类似
跳过了训练一个 reward model,直接进行第三步的 reinforcement learning,不过使用的是 Rule-based Reward。不过对于无法使用 Rule-based Reward 进行评估的问题,比如文章写作,依然使用了 reward model(?)
小模型蒸馏
虽然蒸馏小模型不是由 DeepSeek 首次提出,但 DeepSeek 真正第一次做到了产生了一个实际可以运行且效果很好的小模型,证明了小模型蒸馏的可行性。这就是 DeepSeek 的开创性贡献。
DeepSeek 还尝试了在 32B qwen 模型上直接用和 R1 一样的训练过程,但效果和通过 R1 蒸馏这个模型相比差了很多,说明 R1 训练范式或者 RLHF 在小参数模型上无法达到预期的效果,该训练范式仅适用于大参数模型。