Linux内核学习笔记之中断和中断处理
相比于轮询,中断是让硬件在需要的时候再向内核发出信号
中文版里把
software interrupt和softirq都翻译成软中断,造成了混淆。我把software interrupt统一翻译为软件中断
中断
硬件中断
硬件设备生成中断的时候并不考虑与处理器的时钟同步(异步中断),换句话说就是中断随时可以产生。
从物理学的角度看,中断是一种电信号,由硬件设备生成,并直接送入中断控制器的输入引脚中。中断控制器是个简单的电子芯片,其作用是将多路中断管线,采用复用技术只通过一个和处理器相连接的管线与处理器通信。当接收到一个中断后,中断控制器会给处理器发送一个电信号。处理器一经检测到此信号,便中断自己的当前工作转而处理中断。此后,处理器会通知操作系统已经产生中断,这样,操作系统就可以对这个中断进行适当地处理了。
而每个中断都通过一个唯一的数字标志区分,称为中断请求(IRQ)线(IRQ line,或叫中断号)
异常
异常与硬件中断不同,它在产生时必须考虑与处理器时钟同步(同步中断)。
处理器执行到由于编程失误而导致的错误指令(如被0除)的时候,或者是在执行期间出现特殊情况(如缺页),必须靠内核来处理的时候,处理器就会产生一个异常。
处理异常和硬件中断的方法基本相同,本文主要介绍硬件中断
有些人会把异常误认为是软中断(softirq),这是不对的,其实可以叫软件中断(software interrupt),和硬件中断相对。
中断处理程序
在响应一个特定中断的时候,内核会执行一个函数,称为中断处理程序(interrupt handler)或中断服务例程(interrupt service routine,ISR)。
中断处理程序是被内核调用来响应中断的而它们运行于我们称之为中断上下文的特殊上下文中
中断处理程序应该尽可能得短,原子性,不能阻塞。
中断处理分割上下部分
又想中断处理程序运行得快,又想中断处理程序完成的工作量多。就需要将中断处理分为上下两部分。
上半部(top half):运行
中断处理程序,需要运行快,处理重要的事务。如从网卡的
接收缓存拷贝到内存的操作,不及时处理会导致接收缓存溢出。下半部(bottom half):能够被允许
稍后完成的工作会推迟到下半部(bottomhalf)去。此后在合适的时机,下半部会被开中断执行。如处理从接收缓存拷贝到内存的数据,因为内存很大,不需要及时处理。
下半部运行的程序不被称为
中断处理程序
注册中断处理程序
驱动程序可以通过request_irq()函数注册一个中断处理程序(它被声明在文件<linux/interrupt.h>中),并且激活给定的中断线,以处理中断:
1
2
3
4
5
6
// 分配一条给定的中断线
request_irq(unsigned int irq, // 中断号数字
irq_handler_t handler, // 中断处理函数指针
unsigned long flags,
const char *name,
void *dev)
1
2
// irq_handler_t原型
typedef irqreturn_t (*irq_handler_t) (int, void *);
参数: flags
中断处理程序标志,位掩码
IRQF_DISABLED:
处理该中断时,无需关注,新 Linux 内核已移除关中断(关所有中断,如果未置位,只关闭当前中断线的中断)旧的内核(2.6.35 版本之前)认为有两种 interrupt handler:
slow handler和fast handle(注意不是上一节提到的上下部分)。在 request irq 的时候,对于 fast handler,需要传递 IRQF_DISABLED 的参数,确保其中断处理过程中是关闭本地 CPU 的中断的(禁止中断嵌套),因为是 fast handler,执行很快,即便是关闭 CPU 中断不会影响系统的性能。但是,并不是每一种外设中断的 handler 都是那么快(例如磁盘),因此就有 slow handler 的概念,说明其在中断处理过程中会耗时比较长。对于这种情况,在执行 interrupt handler 的时候不能关闭 CPU 中断,否则对系统的 performance 会有影响。新的内核已经不区分 slow handler 和 fast handler,都是
fast handler,都是需要关闭 CPU 中断的,那些需要后续处理的内容推到threaded interrupt handler中去执行。- IRQF_SAMPLE_RANDOM: 该中断的间隔时间作为熵加入
内核熵池(entropy pool),用于产生真随机数的熵。 - IRQF_TIMER: 系统定时器专属标志
- IRQF_SHARED: 允许多个中断处理函数在单个中断线上共享,在同一个给定线上(irq 参数相同)注册的每个处理程序必须指定这个标志
参数: name
中断相关设备的名字,用 ASCII 文本表示,比如"keyboard"
参数: dev
在启用共享中断线(IRQF_SHARED)时用于区分不同的中断处理程序的唯一标志。当中断处理程序需要释放时(如卸载驱动程序),内核将根据该信息释放众多中断处理程序中的对应的中断处理程序。
返回值
成功返回 0,不成功返回错误码。
最常见的错误是-EBUSY,它表示给定的中断线已经在使用(没有指定 IRQF_SHARED)
注册注意事项
request_irq()函数可能会睡眠,所以绝对不要在不允许阻塞的函数(上下文)中调用它!
在注册的过程中,内核需要在/proc/irq文件中新创建一个与中断对应的项。需要使用kmalloc()分配内存,而kmalloc()是允许休眠的。
例子
1
2
3
4
5
if (request_irq(irqn, my_interrupt, IRQF_SHARED|IRQF_SAMPLE_RANDOM, "my_device", my_dev))
{
printk(KERN_ERR "my device: cannot register IRQ %d\n", irqn);
return -EIO;
}
初始化硬件和注册中断处理程序的顺序必须正确,以防止中断处理程序在设备初始化完成之前就开始执行。
释放中断处理程序
卸载驱动程序时,需要注销相应的中断处理程序,并释放中断线。
1
void free_irq(unsigned int irq, void *dev)
dev 的作用见参数: dev
如果中断线是共享的,直到最后一个关联的中断处理程序被释放,该中断线才会被禁用。
编写中断处理程序
声明示例:
1
static irqreturn_t intr_handler(int irq, void *dev)
注意与
request_irq要求的函数指针handler类型匹配,中断处理程序一般都用static修饰未局部函数,因为除了中断服务外不会有其它地方调用它。
- irq: 并没有多大用,中断处理程序一般不需要知道自己的 irq 号
- dev: 就是
request_irq的dev参数,见参数: dev。也可以作为一个参数,传递一个数据结构,告知产生源设备信息,所以参数名字叫 dev(device),因为不同的设备该信息结构肯定不同,所以能保证是唯一的。 - 返回类型 irqreturn_t:
IRQ_NONE和IRQ_HANDLED。当中断处理程序检测到一个中断,但该实际产生源和注册时的产生源不匹配时(dev参数),返回IRQ_NONE;当中断处理程序被正确调用,且产生源匹配时,返回IRQ_HANDLED。
重入和中断处理程序:
Linux 上的中断处理程序无须要求可重入。因为中断程序处理时相应中断线上的中断是必定关闭(或叫屏蔽)的,也就是不会发生相同中断的嵌套。但不同中断的嵌套是有可能发生的,因为不同中断的中断处理函数不同,这种情况也不用考虑可重入。
共享的中断处理程序
中断处理程序必须满足下列条件:
- 注册时
request_irq()的参数flags必须设置IRQF_SHARED标志。 - 同一个中断线下注册的
dev参数必须唯一,所以参数一般使用指向设备信息结构的指针,可以保证唯一 - 中断处理程序必须能够区分它的设备是否真的产生了中断(比如读一下硬件的状态寄存器)。因为同一中断线共享了很多中断处理程序,需要区分该中断是否是和自己相关的。
内核接收一个中断后,它将依次调用在该中断线上注册的每一个处理程序。因此,一个处理程序必须知道它是否应该为这个中断负责,如果发现不是和自己相关的要立即退出。
中断处理程序实例
real-time clock (RTC) 驱动程序,可以在drivers/charrtc.c中找到。用于设置系统时钟,提供报警器(alarm)或周期性的定时器。当需要报警或定时功能时,需要中断的支持。
1
2
3
4
5
6
7
if (request_irq(rtc_irq, rtc_interrupt, IRQF_SHARED, "rtc",
(void *)&rtc_port))
{
rtc_has_irq = 0;
printk(KERN_ERR "rtc: cannot register IRQ %d\n", rtc_irq);
return -EIO;
}
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
static irqreturn_t rtc_interrupt(int irq, void *dev_id)
{
/*
* 可以是报警器中断、更新完成的中断或周期性中断,
* 我们把状态保存在 rtc_irq_data 的低字节中,
* 而把从最后一次读取之后所接收的中断号保存在其余字节中
*/
spin_lock(&rtc_lock); // 自旋锁,保护临界资源rtc_irq_data
rtc_irq_data += 0x100; // 倒数第二字节加1,每次中断都更新
rtc_irq_data &= ~0xff; // 最低字节置0
if (is_hpet_enabled()) {
/*
* In this case it is HPET RTC interrupt handler
* calling us, with the interrupt information
* passed as arg1, instead of irq.
*/
rtc_irq_data |= (unsigned long)irq & 0xF0;
} else {
rtc_irq_data |= (CMOS_READ(RTC_INTR_FLAGS) & 0xF0);
}
if (rtc_status & RTC_TIMER_ON)
mod_timer(&rtc_irq_timer, jiffies + HZ/rtc_freq + 2*HZ/100);
spin_unlock(&rtc_lock);
/* Now do the rest of the actions */
spin_lock(&rtc_task_lock); // 自旋锁,保护临界资源rtc_callback
if (rtc_callback) // RTC允许一个已注册的回调函数在每次进中断时执行
rtc_callback->func(rtc_callback->private_data);
spin_unlock(&rtc_task_lock);
wake_up_interruptible(&rtc_wait);
kill_fasync(&rtc_async_queue, SIGIO, POLL_IN);
return IRQ_HANDLED;// 总是返回IRQ_HANDLED,因为没有判断请求合法性的机制
}
中断上下文
当执行一个中断处理程序时,内核处于中断上下文(interrput context)中。
中断上下文不可以睡眠,也不需要睡眠,因为不存在进程的切换。所以中断处理程序不能调用阻塞式的函数。
中断上下文具有较为严格的时间限制,因为它打断了其他代码。尽量把工作从中断处理程序中分离出来,放在下半部来执行,因为下半部可以在更合适的时间运行。
中断处理程序栈有两种配置:
- 和中断进程的内核栈共享。内核栈的大小是2 页,具体地说,在 32 位体系结构上是 8KB,在 64 位体系结构上是 16KB。
- 独立栈。从 2.6 开始,可选减少内核栈大小为 1 页,因为每个进程占用 2 页太大。为了应对栈大小的减少,中断处理程序拥有了自己的栈,每个处理器一个,大小为 1 页。
中断处理机制的实现
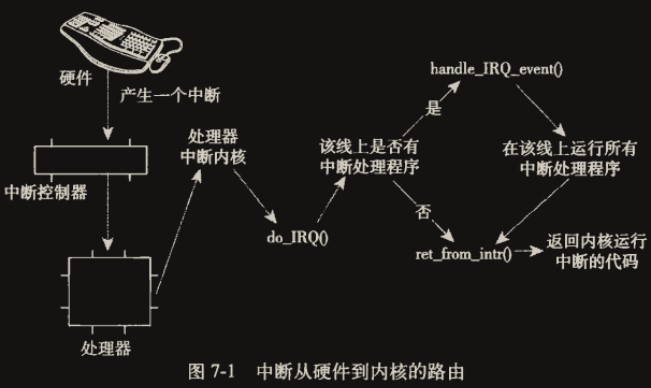
发生中断时,处理器会中断正在执行的任务,跳转到内存预定义的硬件中断处理初始入口点(一般是用汇编写的,由内核启动时注册到 CPU 上,x86 上是在<arch/x86/kernel/entry_32.S>中的common_interrupt):
common_interrupt:
ASM_CLAC
addl $-0x80,(%esp) /* 将栈顶的值减去0x80,Adjust vector into the [-256,-1] range */
SAVE_ALL /* 保存所有寄存器到栈,中断处理完后恢复 */
TRACE_IRQS_OFF
movl %esp,%eax /* 将栈指针(ESP)的值保存到通用寄存器EAX */
call do_IRQ /* 执行IRQ_handler */
jmp ret_from_intr /* 从中断返回 */
初始入口点在栈中保存 IRQ 号,并存放当前寄存器的值(这些值属于被中断的任务,有关寄存器的保存具体见受限直接执行协议(时钟中断))。然后,调用函数do_IRQ()。
因为初始入口点已经将 IRQ 号和寄存器都存在栈中了,而且 C 语言的函数调用参数读取就是从栈顶读取,执行函数
do_IRQ()时非常自然的读取到了之前用汇编压栈的原始寄存器值作为其参数regs,包含了 IRQ 号。
声明:
1
2
// arch/x86/include/asm/irq.h
unsigned int do_IRQ(struct pt_regs *regs)
定义:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
// arch/x86/kernel/irq.c
/*
* do_IRQ handles all normal device IRQ's (the special
* SMP cross-CPU interrupts have their own specific
* handlers).
*/
unsigned int __irq_entry do_IRQ(struct pt_regs *regs)
{
struct pt_regs *old_regs = set_irq_regs(regs);
/* high bit used in ret_from_ code */
unsigned vector = ~regs->orig_ax;
unsigned irq;
irq_enter();
exit_idle();
irq = __this_cpu_read(vector_irq[vector]);
// 会调用handle_irq_event处理这条中断线上已注册的中断处理程序
if (!handle_irq(irq, regs))
{
ack_APIC_irq();
if (printk_ratelimit())
pr_emerg("%s: %d.%d No irq handler for vector (irq %d)\n",
__func__, smp_processor_id(), vector, irq);
}
irq_exit();
set_irq_regs(old_regs);
return 1;
}
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
// kernel/irq/handle.c
irqreturn_t handle_irq_event(struct irq_desc *desc)
{
struct irqaction *action = desc->action;
irqreturn_t ret;
desc->istate &= ~IRQS_PENDING;
irqd_set(&desc->irq_data, IRQD_IRQ_INPROGRESS);
raw_spin_unlock(&desc->lock);
// 单cpu的独立执行函数
ret = handle_irq_event_percpu(desc, action);
raw_spin_lock(&desc->lock);
irqd_clear(&desc->irq_data, IRQD_IRQ_INPROGRESS);
return ret;
}
irqreturn_t
handle_irq_event_percpu(struct irq_desc *desc, struct irqaction *action)
{
irqreturn_t retval = IRQ_NONE;
unsigned int flags = 0, irq = desc->irq_data.irq;
// 原来此处是需要根据IRQF_DISABLED标志决定是否关所有中断的,
// 进中断时CPU默认关闭全部中断,如果IRQF_DISABLED未置位,则此处在
// 处理中断处理程序前需要临时打开除了本中断线以外的中断实现中断抢占,
// 现在已不再需要
// if (!(action->flags & IRQF_DISABLED))
// local_irq_enable_in_hardirg();
// while循环以执行所有的已注册的中断处理程序
do
{
irqreturn_t res;
trace_irq_handler_entry(irq, action);
// 执行中断处理程序
res = action->handler(irq, action->dev_id);
trace_irq_handler_exit(irq, action, res);
if (WARN_ONCE(!irqs_disabled(), "irq %u handler %pF enabled interrupts\n",
irq, action->handler))
local_irq_disable();
// 检查中断处理程序的返回值
switch (res)
{
// 中断处理程序希望在工作队列处理下半部
case IRQ_WAKE_THREAD:
/*
* Catch drivers which return WAKE_THREAD but
* did not set up a thread function
*/
// 检查,如果中断处理程序返回 IRQ_WAKE_THREAD,
// 但未定义线程处理函数,则错误
if (unlikely(!action->thread_fn))
{
warn_no_thread(irq, action);
break;
}
// 在工作队列处理(下半部)
irq_wake_thread(desc, action);
/* Fall through to add to randomness */
// 中断处理程序处理成功
case IRQ_HANDLED:
flags |= action->flags;
break;
default:
break;
}
retval |= res;
// action是个链表
action = action->next;
} while (action);
// 如果指定了 IRQF_SAMPLE_RANDOM,需要将信息加入到内核熵池
add_interrupt_randomness(irq, flags);
if (!noirqdebug)
note_interrupt(irq, desc, retval);
// 关闭全部中断,对应上面的开中断
// local_irq_disable();
return retval;
}
检查重新调度
do_IRQ()执行完毕处理完所有中断服务程序后,会执行ret_from_intr()(汇编),检查是否需要重新调度(need_resched 标志):
- 返回用户空间:发生在内核正在返回用户空间(中断打断的是用户进程),
schedule()将被调用(就像利用定时中断执行调度,见时钟中断) 返回内核空间:在支持内核抢占的内核上,发生在内核正在返回内核空间(中断打断的是内核),在
preempt_count为 0 时,schedule()会被调用;否则将不触发重新调度(比如自旋锁会调用preempt_disable临时关闭内核抢占);在不支持内核抢占的内核上,只要在内核空间,就永远不会发生重新调度。关闭内核抢占是比关中断更加温和的同步方式,只是禁止了重新调度,中断还是可以发生的
/proc/interrupts
procfs是一个虚拟文件系统,它只存在于内核内存,一般安装于/proc目录。在procfs中读写文件都要调用内核函数
/proc/interupts文件,存放的是系统中与中断相关的统计信息:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
CPU0
1: 9 IO-APIC 1-edge i8042
6: 3 IO-APIC 6-edge floppy
8: 0 IO-APIC 8-edge rtc0
9: 0 IO-APIC 9-fasteoi acpi
10: 0 IO-APIC 10-fasteoi virtio2
11: 0 IO-APIC 11-fasteoi uhci_hcd:usb1
12: 15 IO-APIC 12-edge i8042
14: 0 IO-APIC 14-edge ata_piix
15: 12818466 IO-APIC 15-edge ata_piix
24: 0 PCI-MSI 65536-edge virtio1-config
25: 25943188 PCI-MSI 65537-edge virtio1-req.0
26: 0 PCI-MSI 49152-edge virtio0-config
27: 518971441 PCI-MSI 49153-edge virtio0-input.0
28: 173245743 PCI-MSI 49154-edge virtio0-output.0
NMI: 0 Non-maskable interrupts
LOC: 1913750057 Local timer interrupts
SPU: 0 Spurious interrupts
PMI: 0 Performance monitoring interrupts
IWI: 1 IRQ work interrupts
RTR: 0 APIC ICR read retries
RES: 0 Rescheduling interrupts
CAL: 0 Function call interrupts
TLB: 0 TLB shootdowns
TRM: 0 Thermal event interrupts
THR: 0 Threshold APIC interrupts
DFR: 0 Deferred Error APIC interrupts
MCE: 0 Machine check exceptions
MCP: 41518 Machine check polls
ERR: 0
MIS: 0
PIN: 0 Posted-interrupt notification event
NPI: 0 Nested posted-interrupt event
PIW: 0 Posted-interrupt wakeup event
第 1 列是中断线,第 2 列是接收中断的计数器,第 3 列是处理这个中断的中断控制器,第 4 列是设备名
中断控制
Linux 内核提供了一组接口用于操作机器上的中断状态。这些接口为我们提供了能够禁止当前处理器的中断系统,或屏蔽掉整个机器的一条中断线的能力,这些例程都是与体系结构相关的,可以在<asm/system.h>和<asm/irq.h>中找到。
| 函数 | 说明 |
|---|---|
| local_irq_disable() | 禁止本地中断传递 |
| local_irq_enable() | 激活本地中断传递 |
| local_irq_save() | 保存本地中断传递的当前状态,然后禁止本地中断传递 |
| local_irq_restore() | 恢复本地中断传递到给定的状态 |
| disable_irq() | 禁止给定中断线,并确保该函数返回之前在该中断线上没有处理程序在运行 |
| disable_irq_nosync() | 禁止给定中断线激活给定中断线 |
| enable_irq() | 如果本地中断传递被禁止,则返回非 0;否则返回 0 |
| irqs_disabled() | 如果在中断上下文中,则返回非 0; |
| in_interrupt() | 如果在进程上下文中,则返回 0 |
| in_irq() | 如果当前正在执行中断处理程序,则返回非 0;否则返回 0 |
中断控制的作用是实现同步。
实现同步需要两种方式:
- 锁:锁用于实现不同处理器间对临界资源(CPU 间共享资源)访问的同步
- 中断控制:通过禁用中断防止同一个处理器中的资源被其他中断服务程序并发访问
禁止和激活中断
1
2
local_irq_disable(); // 关所有中断(当前CPU)
local_irq_enable(); // 开所有中断(当前CPU)
这两个函数通常都是使用单条汇编指令实现,local_irq_disable()对应cli,local_irq_enable()对应sti。
目前的
cli和sti都只对本 CPU 有效,全局的开关中断功能已被取消。全局的开关中断可以实现自旋锁的功能,当一个 CPU 调用cli关中断,进入临界区,另一个 CPU 也调用cli,就会等待,无法进入临界区。但该方法太浪费性能,随着临界区种类的变多,细粒度更高的锁的性能明显大于单个的全局开关中断(比如没有关系的两个临界区也会被锁定,因为锁只有一把),所以被废弃。
保存并恢复:
还需要一种机制,能够读取并保存原来的中断状态,并在之后恢复,防止出现在关中断的情况下在关中断导致死锁的情况。
1
2
3
4
5
unsigned long flags;
local_irq_save(flags); /* 检测并保存中断状态,并禁止中断*/
/* do something */
local_irq_restore(flags); /* 恢复中断状态*/
要保证 flags 一直在同一个栈中,也就是这两个函数必须再同一个函数中。一般这两个函数比上面两个函数用的多。
本小节的 4 个函数函数既可以在中断中调用,也可以在进程上下文中调用。
禁止指定中断线
以下函数控制目标为全 CPU
1
2
3
4
void disable_irq(unsigned int irq); // 关指定中断线中断(同步)
void disable_irq_nosync(unsigned int irq); // 关指定中断线中断(异步,立即返回)
void enable_irq(unsigned int irq); // 开指定中断线中断
void synchronize_irq(unsigned int irq); // 等待一个特定的中断处理程序的退出(同步)
disable_irq 需要等待中断线上所有中断处理程序退出才会返回,而 disable_irq_nosync 则不需要。
synchronize_irq 也需要等待中断线上所有中断处理程序退出才会返回,所以 disable_irq 类似于 synchronize_irq+disable_irq_nosync
以上函数可以嵌套使用,enable_irq 与 disable_irq/disable_irq_nosync 配对,也就是说多次的 disable 需要对应次数的 enable 才能真正启用(类似于#if和#endif宏的嵌套)
以上函数可以从中断或进程上下文中调用,而且不会睡眠(不会导致进程的切换,可以理解为不停执行空操作,独占当前 CPU,如果有另一个 CPU 在做对这个中断线的中断处理,同步的接口会等待那个操作完成。TODO:应该还是会被定时中断强制切换进程,只不过不是主动放弃 CPU)。但在中断上下文调用时要注意不要启用当前真正执行中断处理的中断线,中断处理时对应中断线必须是被屏蔽的
由于现代设备较多使用中断线共享,禁止一条中断线也就禁止了这条线上所有设备的中断传递,影响较大,一般不使用这些接口。
中断系统的状态
中断的状态(禁止、激活):
irqs_disable():定义在 <asm/system.h> 中,返回值如下:
- 0:中断开启
- 非 0:中断关闭
in_interrupt():定义在 <linuxyhardirq.h> 中,检查内核是否处于任何中断处理中(包含上下半部分)
in_irq():定义在 <linuxyhardirq.h> 中,检查内核是否处于任何中断处理的上半部分(中断处理程序)
下半部
下半部的任务就是执行与中断处理密切相关但中断处理程序本身不执行的工作
一般有如下标准:
- 如果一个任务对时间敏感,将其放在中断处理程序中执行。
- 如果一个任务和硬件相关,将其放在中断处理程序中执行。
- 如果一个任务要保证不被其他中断(特别是相同的中断)打断,将其放在中断处理程序中执行。
- 其他所有任务,考虑放置在下半部执行。
BH: 下半部的起源
最早的 Linux 只提供”bottom half”这种机制用于实现下半部。称其为 BH 防止和现在的下半部混淆。内核静态创建了 32 个 bottom halves 组成的链表,上半部通过一个整型值通知内核链表中的哪个 BH 程序应该运行。BH 在全局范围内进行同步。即使分属于不同的处理器,也不允许任何两个 bottom half 同时执行。这种机制使用方便却不够灵活,简单却有性能瓶颈。
任务队列
任务队列 (task queue) 机制定义了一组队列,每个队列是一个链表,每有一个推迟的任务就加入链表中等待被执行。驱动程序可以把它们自己的下半部注册到合适的队列上去。这种机制表现得还不错,但仍不够灵活,没法代替 BH。
软中断(softirqs)和 tasklet
在 2.3 版本引入,取代 BH。tasklet 是一种基于软中断实现的灵活性强、动态创建的下半部实现机制。
内核定时器
内核定时器把操作推迟到某个确定的时间段之后执行。对时间要求较高的可以使用这种方式
小结
| 下半部机制 | 状态 |
|---|---|
| BH | 在 2.5 中去除 |
| 任务队列(Task queues) | 在 2.5 中去除 |
| 软中断(Softirq) | 从 2.3 开始引入 |
| tasklet | 从 2.3 开始引入 |
| 工作队列(Work queues) | 从 2.5 开始引入 |
软中断
软中断使用得比较少;而 tasklet 是下半部更常用的一种形式。但是,由于 tasklet 是通过软中断实现的,所以我们先来研究软中断。软中断的代码位于<kernel/softirq.c>文件中。
软中断的实现
软中断是静态分配的,在<linux/interrupt.h>中声明 softirq_action 结构:
1
2
3
4
struct softirq_action
{
void (*action)(struct softirq_action *);
};
在 <kenel/softirq.c> 中定义了一个包含有 32 个该结构体的数组。
1
static struct softirq_action softirq_vec[NR_SOFTIRQS] __cacheline_aligned_in_smp;
每个被注册的软中断都占据该数组的一项,因此最多可能有 32 个软中断。
软中断处理程序
软中断处理程序示例(函数名可以自定义,也就是 softirq_action 里的 action 函数结构):
1
void softirq_handler(struct softirq_action *)
软中断执行时机
一个注册的软中断必须在被标记后才会执行。这被称作触发软中断(Taising the softirq)。中断处理程序会在返回前标记它的软中断,使其在稍后被执行。在下列地方,待处理的软中断会被检查和执行:
- 一个硬件中断代码处返回时(此时中断处理程序已执行完),在do_IRQ()中的
irq_exit()会调用do_softirq() - 在
ksoftirqd内核线程中 - 在那些显式检查和执行待处理的软中断的代码中,如网络子系统中
执行软中断
唤起检查后,使用do_softirq()检查并执行待执行的中断处理程序,简化的do_softirq():
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
asmlinkage void __do_softirq(void)
{
struct softirq_action *h;
__u32 pending;
...
// 待处理32位位图,置位表示 softirq_vec 中对应软中断处理程序等待执行
pending = local_softirq_pending();
...
// 位图已经临时保存到pending,可清空
set_softirq_pending(0);
// 开启中断
local_irq_enable();
// 将指针 h 指向 softirq_vec 的第一项
h = softirq_vec;
do
{
// 位图的位置位时,执行对应的软中断处理程序
if (pending & 1)
{
...
h->action(h);
...
}
// 指针偏移,位图已处理位右移弹出
h++;
pending >>= 1;
} while (pending);
// 位全部弹出或没有被置位的位时结束循环
...
}
这里将整个softirq_action 结构(变量 h)作为参数传递给了 action (h->action(h);),是为了向后兼容性,如果softirq_action 结构后续更新了(现在只有一个 action 函数指针),也不需要改动该接口代码,只需改动对应解析该结构的代码。
一个软中断不会抢占另外一个软中断,因为只在do_softirq中顺序执行。实际上,唯一可以抢占软中断的是中断处理程序(执行软中断处理程序时中断总是打开的,见 local_irq_enable();)。不过,其他的软中断(甚至是相同类型的软中断)可以在其他处理器上同时执行。
使用软中断的条件
软中断保留给系统中对时间要求最严格以及最重要的下半部使用。即使是对时间要求没有上半部严格的下半部,内部也细分重要等级。目前,只有两个重要的子系统(网络和SCSI)直接使用软中断。
其他的下半部都建立在内核定时器和tasklet上,不过内核定时器和 tasklet 都是建立在软中断上的,也就是封装了一层。
使用软中断
分配索引
在<linux/interrupt.h>中定义的一个枚举类型来静态地声明软中断,索引越小优先级越高。这个索引就是softirq_vec数组的索引,也就是最大有 32 个,每个索引只能注册一个软中断处理程序。
软中断向量表:
| 软中断枚举名 | 优先级 | 软中断描述 |
|---|---|---|
| HI_SOFTIRQ | 0 | 优先级高的 tasklets |
| TIMER_SOFTIRQ | 1 | 定时器的下半部 |
| NET_TX_SOFTIRQ | 2 | 发送网络数据包 |
| NET_RX_SOFTIRQ | 3 | 接收网络数据包 |
| BLOCK_SOFTIRQ | 4 | BLOCK 装置 |
| TASKLET_SOFTIRQ | 5 | 正常优先权的 tasklets |
| SCHED_SOFTIRQ | 6 | 调度程序 |
| HRTIMER_SOFTIRQ | 7 | 高分辩率定时器 |
| RCU_SOFTIRQ | 8 | RCU 锁定 |
新增一个枚举名一般在其中插入,而不是仅能在尾部追加
注册处理程序
在运行时通过调用open_softirq()注册软中断处理程序,两个参数:软中断的索引号和处理函数。
如网络子系统,在net/coreldev.c通过以下方式注册自己的软中断:
1
2
open_softirq(NET_TX_SOFTIRQ, net_tx_action);
open_softirq(NET_RX_SOFTIRQ, net_rx_action);
软中断处理程序执行时独占当前 CPU,不会主动睡眠,无法处理当前 CPU 的其他软中断,但可以被硬件中断打断。
不同 CPU 可以同时执行软中断,甚至是同一个中断处理程序,没有互斥,所以如果有能在 CPU 间共享的数据(临界资源),需要程序员自己在中断处理程序内加锁防止并发访问。但是加锁后会让不同 CPU 间的软中断的执行变得同步,影响性能。可以通过避免使用共享数据,让所有数据都是每个 CPU 独享(单处理器数据)的方式避免该问题(在内存管理中的每个 CPU 的分配一节有提到)。这个缺点会在下一节中的 tasklet 中解决
触发软中断
也就是软中断位图置位,挂起软中断处理程序等待执行。
1
raise_softirq(NET_TX_SOFTIRQ);
一般会在中断处理程序中调用,来延后执行下半部任务。而且根据软中断执行时机,在中断处理程序完成后硬件中断返回时有一个执行触发时机,可以较为及时地处理下半部。
该函数需要在关中断的情况下调用,也就是调用前关中断,调用后立即打开,可能是为了保护临界资源。如果中断已禁用,可以直接调用以下函数提高性能:
1
raise_softirq_irqoff(NET_TX_SOFTIRQ) ;
raise_softirq()实际上就是封装了中断状态的保存恢复和raise_softirq_irqoff()
ksoftirqd
每个处理器都有一组辅助处理软中断(和 tasklet)的内核线程。当内核中出现大量软中断的时候,这些内核进程就会辅助处理它们。
软中断的优先级高于一般用户程序,而且软中断还拥有在运行中重新被激活的能力,这会导致可能出现大量的软中断,需要方法处理:
- 总是执行:对于重新激活的软中断,总是立即执行。它们不断重新被激活将导致
__do_softirq()内的循环永远无法退出,用户程序将无法得到执行而饿死。此时软中断和中断处理程序其实没区别,都占据了中断上下文太长时间。 - 总是延后执行:对于重新激活的软中断,总是不执行,而是放到下次检测再执行。对于实时性要求较高的软中断这显然无法满足需求,不知道下次检测要等到什么时候。
- 延后后放入专用线程:目前的实现方案是总是不执行并延后,和 2 相同,但当负载比较大时,将这些延后的任务放入特定线程 ksoftirqd 执行,这些线程优先级一般很低,不会影响正常的用户程序
这些线程通过 ps -e 命令能看到,命名为 ksoftirqd/n (n 为 CPU 编号),每个 CPU 都绑定有这样一个线程
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
static void run_ksoftirqd(unsigned int cpu)
{
local_irq_disable();
if (local_softirq_pending())
{
__do_softirq();
local_irq_enable();
cond_resched();
preempt_disable();
rcu_note_context_switch(cpu);
preempt_enable();
return;
}
local_irq_enable();
}
通过 local_softirq_pending() 判断本 CPU 上是否有延后的软中断处理程序,随后调用 __do_softirq() 运行那些被延后的任务。
tasklet
根据上节表述,我们编写下半部时应该更倾向于使用 tasklet 而非直接使用软中断。
tasklet 的实现
tasklet 本身就是一种软中断,根据分配索引,tasklet 按优先级分为两类:HI_SOFTIRQ和TASKLET_SOFTIRQ。
tasklet 结构
1
2
3
4
5
6
7
8
9
//<linux/interrupt.h>
struct tasklet_struct
{
struct tasklet_struct *next;// 链表
unsigned long state;// tasklet 的状态
atomic_t count;// 引用计数器
void (*func)(unsigned long);// tasklet 处理函数
unsigned long data;// 给 tasklet 处理函数的参数
};
state: 运行状态位图。
TASKLET_STATE_SCHED是第 0 位,其置位表明 tasklet 已被调度,正准备投入运行;TASKLET_STATE_RUN是第 1 位,其置位表明该 tasklet 正在运行。TASKLET_STATE_RUN只有在多处理器的系统上才会作为一种优化来使用,单处理器系统任何时候都清楚单个 tasklet 是不是正在运行;若两者都未置位,值为 0,表明未运行且未等待调度。
count:
用于多 CPU 情况下,表示该结构被几个链表引用(也就是几个 CPU 引用),如果它不为 0,则 tasklet 被禁止,不允许执行;只有当它为 0 时,tasklet 才被激活,并且在被设置为挂起状态时,该 tasklet 才能够执行。
调度 tasklet
每个处理器都有两条链表,存放已调度的 tasklet 结构(state 为 TASKLET_STATE_SCHED):
tasklet_vec:普通 tasklet,对应优先级TASKLET_SOFTIRQ的软中断tasklet_hi_vec:高优先级的 tasklet,对应优先级HI_SOFTIRQ的软中断
两个调度函数,参数为待调度的 tasklet_struct,类比于raise_softirq,一般在中断处理程序中调用:
- tasklet_schedule()
- tasklet_hi_schedule()
它们的执行步骤:
- 检查该 tasklet_struct 的状态是否为
TASKLET_STATE_SCHED。是的话说明已经被调度,不需要做任何事,直接返回 - 如果该 tasklet_struct 未挂起,调用
_tasklet_schedule()。 - 保存中断状态,然后关中断,进入临界区。
- 把这个需要调度的 tasklet_struct 加到每个处理器一个的
tasklet_vec链表或tasklet_hi_vec链表的表头上去,这两个变量都是临界资源,所以第 3 步关了中断。这两个链表保存的信息就是为了后续触发 tasklet 处理时要执行的子任务。 - 唤起
TASKLET_SOFTIRQ或HI_SOFTIRQ软中断(见触发软中断,调用时必须关中断,第 3 步已经关了),这样在下一次调用do_softirq()时就会执行一次 tasklet 处理。(当然如果已经该软中断已经唤醒过这一步就没有效果,相当于重复唤醒)。 - 恢复中断到原状态并返回,退出临界区。
如果本函数是在中断处理程序内调用的,下一次软中断检查(do_softirq())就是在中断处理程序退出后硬件中断返回时,只要 tasklet 相关的软中断(HI_SOFTIRQ和TASKLET_SOFTIRQ)被唤醒过,就能触发 tasklet。
tasklet 检测和处理
tasklet_action() 和 tasklet_hi_action()是标准的软中断处理程序,被注册到软中断向量表中(TASKLET_SOFTIRQ和HI_SOFTIRQ),tasklet 被触发后由它们再去执行注册到 tasklet 里的 tasklet 服务程序。
它们的执行步骤:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
// <kernel/softirq.c>
static void tasklet_action(struct softirq_action *a)
{
struct tasklet_struct *list;
local_irq_disable(); // 关中断,tasklet_vec 对当前cpu来说是临界资源
list = __this_cpu_read(tasklet_vec.head); // 临时保存链表
__this_cpu_write(tasklet_vec.head, NULL); // 清空当前链表(创建新链)
__this_cpu_write(tasklet_vec.tail, &__get_cpu_var(tasklet_vec).head);
local_irq_enable();// 开中断
// 获取链表上每个 tasklet 处理程序
while (list)
{
struct tasklet_struct *t = list;
list = list->next;
// 判断 state 是否是 TASKLET_STATE_RUN,
// 如果是则表示其他CPU正在运行该处理程序,
// 本次无需运行该 tasklet 处理程序
if (tasklet_trylock(t))
{
// 根据 tasklet_struct 中的count引用计数器
// 判断该 tasklet 处理程序是否被唤醒(是否需要执行)
if (!atomic_read(&t->count))
{
if (!test_and_clear_bit(TASKLET_STATE_SCHED, &t->state))
BUG();
t->func(t->data);
tasklet_unlock(t);
continue;
}
tasklet_unlock(t);
}
// 对于未执行的 tasklet 处理程序继续放回到链表末尾,等待下次检测
local_irq_disable();
t->next = NULL;
*__this_cpu_read(tasklet_vec.tail) = t;
__this_cpu_write(tasklet_vec.tail, &(t->next));
__raise_softirq_irqoff(TASKLET_SOFTIRQ);
local_irq_enable();
}
}
- 关中断(在执行软中断中提到软中断处理程序执行时,中断总是打开的,所以无需考虑检测并保存状态),检索本处理器的
tasklet_vec或tasklet_hi_vec链表 - 临时保存当前链表(在栈中)并清空当前链表,该链表为临界资源,通过临时变量保存来防止占用过长时间
- 开中断,退出临界区
- 循环遍历获得链表上的每一个待处理的 tasklet 处理程序。
- 判断是否正在运行(
TASKLET_STATE_RUN置位,当然了,不可能是正在本 CPU 上运行,只可能正在其他 CPU 上运行),如果正在运行,就先不处理,直接跳过(tasklet 规则之一:同一时间相同的处理程序只运行一个) - 如果未在运行,那
tasklet_trylock(t)内就会将TASKLET_STATE_RUN置位,这里使用了test_and_set_bit()保证检测和置位的原子性 - 检查 count 值是否为 0,确保 tasklet 没有被禁止。否则也跳过
- 开始执行 tasklet 处理程序(tasklet_struct 中的 func)
- 执行完毕时在
tasklet_unlock(t);中清空TASKLET_STATE_RUN标志。 - 回到第 4 步并重复,知道所有tasklet 处理程序处理完成
在 tasklet 内部,没有使用自旋锁,对于正在其他 CPU 上运行的同一个处理程序,tasklet 选择直接跳过它并等待下次检测,而不是同步等待,大大提高了性能。
相比于直接使用软中断,主要优点是实现了处理程序间的同步(软中断允许同一处理程序在不同 CPU 上同时运行,程序员需要自己保证临界资源的同步,而 tasklet 直接禁止了同时运行,改为顺序运行)。另一个优点是可以注册很多很多的独立处理程序(因为链表的特性),而软中断上只能注册最大 32 个(数组的特性),其他有些注册位还是已经被抢占了的。
使用 tasklet
声明你自己的 tasklet
内核提供两个宏,用于静态创建(自动分配内存) tasklet_struct 结构:
1
2
3
4
5
#define DECLARE_TASKLET(name, func, data) \
struct tasklet_struct name = { NULL, 0, ATOMIC_INIT(0), func, data }
#define DECLARE_TASKLET_DISABLED(name, func, data) \
struct tasklet_struct name = { NULL, 0, ATOMIC_INIT(1), func, data }
DECLARE_TASKLET 创建的结构默认是激活状态(count 为 0),而 DECLARE_TASKLET_DISABLED 反之
内核还提供动态创建(自行分配内存,可以分配在堆中)的方式:
1
2
3
4
5
6
7
8
9
void tasklet_init(struct tasklet_struct *t,
void (*func)(unsigned long), unsigned long data)
{
t->next = NULL;
t->state = 0;
atomic_set(&t->count, 0);
t->func = func;
t->data = data;
}
编写你自己的 tasklet 处理程序
tasklet 处理程序必须符合规定的函数类型:
1
void tasklet_handler(unsigned long data)
禁止在 tasklet 处理程序中使用阻塞式函数(TODO:自旋锁之类的应该没关系,因为只是循环等待,没有放弃 CPU)。如果和其他的tasklet 处理程序或软中断处理程序共享了数据,注意还是要适当加锁保护。(tasklet 只是保证了同一个tasklet 处理程序不会并发执行)
调度你自己的 tasklet
通过调用 tasklet_schedule() 就能让自己的处理程序注册并挂起(不同于软中断是需要提前注册的)。
1
tasklet_schedule(&my_tasklet);/*把my_tasklet标记为挂起*/
从调度 tasklet一节中可以看出,同一个 tasklet 处理程序(也就是同一个 tasklet_struct)只能调度一次,第二次调度时因为tasklet_schedule()会检测TASKLET_STATE_SCHED导致直接返回。再看tasklet-检测和处理,只有当执行test_and_clear_bit(TASKLET_STATE_SCHED, &t->state)后,处理程序运行时,才有机会能调度第二次(比如此时本 CPU 又触发了一个硬件中断,或者另一个 CPU 又调度了一次)。
作为优化,一个 tasklet 总在调度它的处理器上执行——这是希望能更好地利用处理器的高速缓存
控制激活状态(count 的值):
1
2
3
tasklet_disable(&my_tasklet); // 禁用该 tasklet (同步,如果正在执行需要等待执行完成)
tasklet_disable_nosync(&my_tasklet); // 禁用该 tasklet (异步)
tasklet_enable(&my_tasklet); // 启用该 tasklet
控制挂起状态(是否在链表中):
1
tasklet_kill(&my_tasklet) // 取消挂起,也就是从挂起队列链表中移除(同步)
BH
BH 从最早的内核版本开始活到了 2.5 版本。
BH 和软中断很像,支持 32 个处理程序,需要静态定义,但它只支持单线程顺序执行,不支持多 CPU 并发。这让同步变得简单,但严重限制了多 CPU 的性能
最终被软中断和 tasklet 取代。
工作队列
工作队列(workqueue)是另外一种将工作推后执行的形式,工作队列可以把工作推后,交由一个内核线程去执行——这个下半部分总是会在进程上下文中执行。
相较于软中断,它的好处是允许处理程序睡眠,就像一个普通用户程序一样,可以接受内核调度。在需要大量内存,需要获取信号量,需要执行阻塞式 I/O 操作时必须使用该方式处理下半部
在中断处理机制的实现中出现的
irq_wake_thread()就是用于该目的的
工作队列的实现
工作队列拥有一个独立的进程,运行了工作队列管理系统,负责处理分派到各队列里的任务。工作队列管理系统管理若干个工作队列,每个工作队列管理一组工作者(worker)线程(每个 CPU 一个),来执行工作任务。有一个默认的工作队列,其管理的工作者线程名为 events/n ,如果任务发起者不指定,那默认就是在这个默认工作队列所属的工作者线程中排队执行。任务发起者(如驱动程序)可以指定创建一个新的、专属于自己的工作队列用于处理自己的任务,该工作队列和默认工作队列一样拥有每个 CPU 一个的工作者线程(比如取名叫falcon/n),以便执行大量且繁重的任务,防止阻塞默认的工作队列中的工作者线程。大部分任务发起者都使用默认工作队列。
TODO:工作者线程这个逻辑比较像 nginx,以后可以研究下
工作队列结构:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
// <kernel/workqueue.c>
/**
* 外部可见的工作队列抽象是
* 由每个CPU的工作队列组成的数组
*/
struct workqueue_struct
{
struct cpu_workqueue_struct cpu_wq[NR_CPUS];// 每个CPU一个的工作者线程
struct list_head list;
const char *name;
int singlethread;
int freezeable;
int rt;
}
该结构只是一个抽象,实际实现会更复杂。比如
cpu_wq其实是链表而非数组。
工作者线程结构:
1
2
3
4
5
6
7
8
9
struct cpu_workqueue_struct
{
spinlock_t lock; /* 保护本结构的锁 */
struct list_head worklist; /* 本结构链表,用于实现 cpu_wq */
wait_queue_head_t more_work;
struct work_struct *current_struct; // 工作任务,链表实现
struct workqueue_struct *wq; /* 关联所属工作队列结构,也就是其父亲 */
task_t *thread; /* 关联线程 */
}
该结构也只是一个抽象
工作任务的数据结构:
1
2
3
4
5
6
7
// <linux/workqueue.h>
struct work_struct
{
atomic_long_t data; // 处理程序的参数
struct list_head entry; // 本结构链表,用于实现 current_struct
work_func_t func; // 处理程序
};
使用工作队列
创建工作任务
也就是需要延后的处理内容
静态构建:
1
DECLARE_WORK(name, void (*func) (void *), void wdata)
动态构建(自行分配结构并传递结构指针):
1
INIT_WORK(struct work_struct *work,void(*func) (void *), void *data);
函数原型:
1
void work_handler(void *data)
任务对应的函数会由工作者线程执行。函数会运行在进程上下文中。默认情况下,允许响应中断,并且不持有任何锁。如果需要,函数可以睡眠。需要注意的是,尽管操作处理函数运行在进程上下文中,但它不能访问用户空间,因为内核线程在用户空间没有相关的内存映射。
在发生系统调用时,内核会代表用户空间的进程运行,此时它才能访问用户空间,也只有在此时它才会映射用户空间的内存。
对工作进行调度
调度给默认工作者线程(events/n),并立即执行:
1
schedule_work(&work);
调度后延迟执行:
1
schedule_delayed_work(&work, delay);
调度给自定义的工作队列中的工作者线程:
1
2
3
4
5
6
7
int queue_work(struct workqueue_struct *wq,
struct work_struct *work);
int queue_delayed_work(struct workqueue_struct *wq,
struct work_struct *work,
unsigned long delay);
清空队列
等待默认工作队列所有任务执行完毕:
1
void flush_scheduled_work(void);
自定义的工作队列相关方法:
1
void flush_workqueue(struct workqueue_struct *wq);
如果队列还有需要执行的任务,会进入睡眠(只能在进程上下文调用),直到所有任务执行完毕,包括队列中所有延迟执行的任务。
清除所有延迟执行的任务:
1
int cancel_delayed_work(struct work_struct *work);
为了防止延迟执行的任务让flush_scheduled_work等待太长时间
创建新的工作队列
如果不想使用默认工作队列,可以自行创建一个专属工作队列,以及对应的工作者线程
创建函数声明:
1
struct workqueue_struct *create_workqueue(const char *name) ;
默认工作队列创建示例:
1
2
struct workqueue_struct *keventd_wq;
keventd_wq = create_workqueue("events") ;
这会创建一个工作队列,并创建关联的工作者线程
老的任务队列机制
任务队列机制通过定义一组队列来实现其功能。每个队列都有自己的名字,比如调度程序队 列、立即队列和定时器队列。
- 调度程序队列最终进化为现在的工作队列。
- 立即队列会立刻执行任务。
- 定时器队列会在每个系统节拍执行。
因为接口过于复杂零散,最终被淘汰
下半部机制的选择
| 下半部 | 上下文 | 顺序执行保障 |
|---|---|---|
| 软中断 | 中断 | 没有(需要自己实现同步) |
| tasklet | 中断 | 同类型不能同时执行 |
| 工作队列 | 进程 | 没有(和进程上下文一样被调度) |
如果需要及时性,选 tasklet;否则,可选工作队列。
除非对性能要求非常高,需要并发执行处理程序而非顺序执行,否则没必要使用软中断。
在下半部之间加锁
- tasklet:需要考虑不同处理程序之间的同步。使用禁中断并获取锁的方式。
- 软中断:除了 tasklet 考虑的之外,还需要不同 CPU 并发执行相同处理程序间的同步。
- 工作队列:需要考虑的和软中断相同,还要加上相同 CPU 上处理程序间的同步。使用禁止下半部(这里特指在中断上下文中的部分)执行并获取锁的方式。
禁止下半部
void local_bh_disable():禁止本地处理器的软中断和 tasklet 的处理void local_bh_enable():激活本地处理器的软中断和 tasklet 的处理
它们是嵌套的,一定次数的 local_bh_disable 必须对应相同次数的 local_bh_enable
实现(抽象代码):
1
2
3
4
5
6
void local_bh_disable(void)
{
struct thread_info *t = current_thread_info();
// 增加 preempt_count 计数器阻止其执行,可以理解为信号量
t->preempt_count += SOPTIRQ_OFFSET;
}
1
2
3
4
5
6
7
8
9
void local_bh_enable(void)
{
struct thread_info *t = current_thread_info();
// 减少计数器
t->preempt_count -= SOPTIRQ_OFFSET;
// 直到计数器变为0,表示可以执行,立即触发一次软中断的检测并执行
if (unlikely(!t->preempt_count && softirq_pending(smp_processor_id())))
do_softirq();
}
附录:信号处理
信号是一种类似于中断的可以”打断”当前进程正常执行的机制。
所以信号处理也应该和中断处理程序一样,不允许存在阻塞操作。
在 Linux 操作系统中,信号处理可以在几种不同的上下文中被触发,主要取决于进程的当前状态和操作系统的具体实现。信号处理可能被执行的其他几种时机:
进程从内核态返回到用户态
当进程从内核态返回到用户态时,内核会检查是否有待处理的信号。这不仅包括系统调用的完成,还包括从中断处理程序或其他内核模式操作返回时。这确保了即使进程在内核模式下操作时收到信号,这些信号也会在进程回到用户模式时得到处理。
进程被唤醒
当一个处于睡眠状态(例如,等待某个事件或资源)的进程被唤醒时,内核在将控制权返回给进程前检查待处理的信号。如果有信号待处理,内核会优先处理这些信号。
用户模式下的可中断点
进程在执行用户态代码时,虽然大部分时间内核不会主动介入执行流程,但是在某些可中断点(如循环检查、长时间运行的计算等),进程可能会主动或被动检查待处理的信号。这通常涉及到编程语言或运行时环境层面的支持,例如,某些语言运行时可能会在合适的时机主动检查并处理信号。
异步信号安全的系统调用中
某些系统调用被设计为异步信号安全的,意味着它们可以在信号处理函数中安全调用。当进程在这类系统调用期间收到信号,并且对应信号的处理函数被执行时,这也算是一种特殊的执行时机。
利用 sigwait() 等函数主动等待信号
进程可以使用 sigwait()或类似的函数主动等待一个或多个信号的到来。这种情况下,进程处于阻塞状态,直到指定的信号之一到达。这种方式允许进程以同步的方式处理信号,与异步的信号处理机制形成对比。