littlefs技术介绍
特性
- 断电恢复能力 - 在嵌入式系统上,
随时可能断电。 如果断电损坏了任何持久性数据结构,这可能会导致设备变得不可恢复。嵌入式文件系统必须设计为从任何写入操作期间的断电中恢复。 - 磨损均衡 - 写入闪存具有破坏性。如果文件系统
反复写入同一个块,最终该块将磨损。 不考虑磨损的文件系统很容易烧毁用于存储频繁更新的元数据的块,并导致设备过早死亡。 - 有限 RAM/ROM - 嵌入式设备的内存量也非常有限。许多现有的文件系统设计无法适应这种情况,比如依赖于相对大量的 RAM 用于临时存储文件系统元数据。
概念
基于块的存储
存储被划分为块(block),每个文件都存储为块的集合,实际上这些块还会组成一个链表。这样对文件的操作将不是按字节操作,而是对块的操作,减少了管理上的复杂性。
元数据
元数据是用于描述数据的数据,在大多数文件系统中,元数据和文件内容是分开的,元数据用于记录文件的大小,文件名,存放文件的物理位置等信息。同时文件系统的一些基本信息也属于元数据。
日志文件系统
对文件系统的各个操作(如修改一个文件,删除一个文件)通过追加日志的形式记录,而不是直接修改元数据
日志记录文件系统可以保证文件系统操作的一致性。使用校验和(如 CRC)对日志条目进行错误检测,我们可以轻松地检测断电并通过忽略失败回退到以前的状态。
1
2
3
4
5
6
v
.--------.--------.--------.--------.--------.--------.--------.--------.
| C | new B | new A | | A | B |
| | | |-> | | |
| | | | | | |
'--------'--------'--------'--------'--------'--------'--------'--------'
图中显示了一种日志循环的情况,元数据A、B、C 写入完成后接下来修改 B、A,新的日志内容就存在于 C 之后,而不是修改原位置的A和B。
通过不断追加而不是修改也非常适合flash只写一次的特性。
但这带来一个问题,读取时需要遍历日志以重建文件系统。可以使用缓存以避免读取成本,这就需要与 RAM 的占用做权衡。
写时复制(CoW)技术
不去更新原位置的内容,需要修改时复制一份并在修改后写入新的位置
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
.--------. .--------.
| root | write |new root|
| | ==> | |
| | | |
'--------' '--------'
.-' '-. | '-.
| .-------|------------------' v
v v v .--------.
.--------. .--------. | new B |
| A | | B | | |
| | | | | |
| | | | '--------'
'--------' '--------' .-' |
.-' .-' '-. .------------|------'
| | | | v
v v v v .--------.
.--------. .--------. .--------. | new D |
| C | | D | | E | | |
| | | | | | | |
| | | | | | '--------'
'--------' '--------' '--------'
写入一致性
上图是一棵文件树,在上图中对文件 D 的修改不是直接修改 D 所在的块,而是将新的 D 拷贝到新分配的块。导致 D 的位置发生变化,导致目录 B 的指针发生变化,需要修改,对 B 的修改又导致了 B 位置的变化,继而引起 root 位置的变化。在这之后,原 root、B 和 D 将被视为空闲块,可被再次使用。
即使上述步骤因掉电而在任意位置中断,文件系统下次启动时会使用原来的目录结构,而丢弃了未完成的修改动作,保证了修改一致性
flash 特性
因为 flash 只写一次的特性,在 D 上直接修改本身就难以实现,写时复制技术也能解决该问题
擦写均衡
对于非 flash 存储介质,多次对同一个区域进行写入也可能产生磨损从而影响存储介质寿命,通过写时复制不断更换写入的位置也能很好的规避该问题
设计
总览
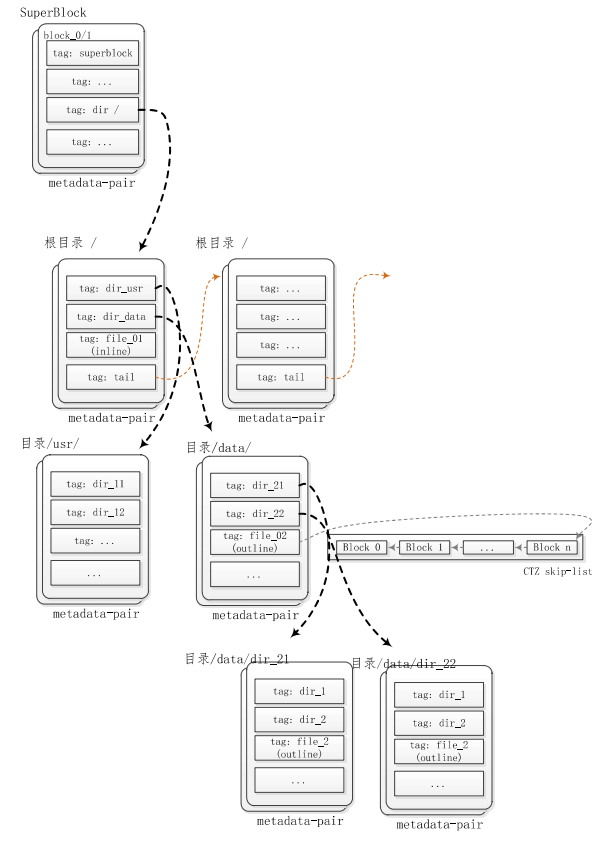
数据的存储默认是小端序(除 tag 外),采用元数据+数据的形式,使用 tag 标识元数据
元数据中的inline表示文件和元数据存储在一起,一般用于比较小的文件;元数据中的outline表示文件存储在另外的块上,通过指针引用。
块分类
块的用途分为两类:
- 存储
元数据,称其为元数据块 - 存储
文件内容,一般这些块使用 ctz 链表连接
元数据
littlefs 的元数据使用日志方式存储,每个操作都对应一条记录,如创建文件等。记录依次存储在元数据块中。
由于采用主备互切的方式,每块元数据实际上需要占用两个物理块,我们称其为元数据对。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
metadata pair pointer: {block 0, block 1}
| '--------------------.
'-. |
disk v v
.--------.--------.--------.--------.--------.--------.--------.--------.
| | |metadata| |metadata| |
| | |block 0 | |block 1 | |
| | | | | | |
'--------'--------'--------'--------'--------'--------'--------'--------'
'--. .----'
v v
metadata pair .----------------.----------------.
| revision 11 | revision 12 |
block 1 is |----------------|----------------|
most recent | A | A'' |
|----------------|----------------|
| checksum | checksum |
|----------------|----------------|
| B | A''' | <- most recent A
|----------------|----------------|
| A'' | checksum |
|----------------|----------------|
| checksum | | |
|----------------| v |
'----------------'----------------'
上图中,metadata block 0 和 block 1 实际上表示同一份 metadata,不过是两个不同的版本,以新的一份为准,上图中就是以 block 1 表示的 revision 12 为准。
每个元数据块包含若干条记录,每若干条记录后有一个 CRC32 checksum 用于校验:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
.---------------------------------------.
.-| revision count | tag ~A | \
| |-------------------+-------------------| |
| | data A | |
| | | |
| |-------------------+-------------------| |
| | tag AxB | data B | <--. |
| |-------------------+ | | |
| | | | +-- 1st commit
| | +-------------------+---------| | |
| | | tag BxC | | <-.| |
| |---------+-------------------+ | || |
| | data C | || |
| | | || |
| |-------------------+-------------------| || |
| | tag CxCRC | CRC | || /
| |-------------------+-------------------| ||
| | tag CRCxA' | data A' | || \
| |-------------------+ | || |
| | | || |
| | +-------------------+----| || +-- 2nd commit
| | | tag CRCxA' | | || |
| |--------------+-------------------+----| || |
| | CRC | padding | || /
| |--------------+----+-------------------| ||
| | tag CRCxA'' | data A'' | <---. \
| |-------------------+ | ||| |
| | | ||| |
| | +-------------------+---------| ||| |
| | | tag A''xD | | < ||| |
| |---------+-------------------+ | |||| +-- 3rd commit
| | data D | |||| |
| | +---------| |||| |
| | | tag Dx| |||| |
| |---------+-------------------+---------| |||| |
| |CRC | CRC | | |||| /
| |---------+-------------------+ | ||||
| | unwritten storage | |||| more commits
| | | |||| |
| | | |||| v
| | | ||||
| | | ||||
| '---------------------------------------' ||||
'---------------------------------------' |||'- most recent A
||'-- most recent B
|'--- most recent C
'---- most recent D
每个元数据类型都有 tag 标记用于识别,连 CRC 也有一个单独的标记。支持事务,每次 commit 以一个 CRC 结束。
tag 在磁盘上的存储使用了异或方式,也就是当前 tag 和上一个 tag 的异或值,第一个 tag 为自身和 0xFFFFFFFF 的异或值(也就是自身的反码)。使用该方式实现错误检查。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
Forward iteration Backward iteration
.-------------------. 0xffffffff .-------------------.
| revision count | | | revision count |
|-------------------| v |-------------------|
| tag ~A |---> xor -> tag A | tag ~A |---> xor -> 0xffffffff
|-------------------| | |-------------------| ^
| data A | | | data A | |
| | | | | |
| | | | | |
|-------------------| v |-------------------| |
| tag AxB |---> xor -> tag B | tag AxB |---> xor -> tag A
|-------------------| | |-------------------| ^
| data B | | | data B | |
| | | | | |
| | | | | |
|-------------------| v |-------------------| |
| tag BxC |---> xor -> tag C | tag BxC |---> xor -> tag B
|-------------------| |-------------------| ^
| data C | | data C | |
| | | | tag C
| | | |
| | | |
'-------------------' '-------------------'
元数据 tag
tag 为 4 字节大小的整体,用于标识元数据,使用大端序存储,因为要保证第一个写入的位为 valid bit。
1
2
3
4
5
6
7
8
9
[---- 32 ----]
[1|-- 11 --|-- 10 --|-- 10 --]
^. ^ . ^ ^- length
|. | . '------------ id
|. '-----.------------------ type (type3)
'.-----------.------------------ valid bit
[-3-|-- 8 --]
^ ^- chunk
'------- type (type1)
元数据 tag 字段:
- 有效位(1 位)- 指示标签是否有效。
Type3(11 位)- 标签的类型。 该字段进一步细分为 3 位 type 类型和 8 位 chunk 字段。 请注意,值 0x000 无效且未分配类型。
- Type1(3 位)- 标签的抽象类型。 将标记分为 8 个类别,以促进位掩码查找。
- chunk(8 位)- 不同抽象类型用于各种目的的 chunk 字段。 type1+chunk+id 构成元数据块中每个标签的
唯一标识符。
- Id(10 位)- 与标签关联的文件 ID。 元数据块中的每个文件都有一个唯一的 ID,用于将标签与该文件相关联。 特殊值 0x3ff 用于与文件无关的任何标记,例如目录和全局元数据。
- 长度(10 位)- 以字节为单位的数据长度。 特殊值 0x3ff 表示该标签已被删除。
超级块
超级块是特殊的元数据块。
superblock 使用元数据对的方式存储,可能会通过 tail 占用多个元数据对,但起始元数据对总是位于 block 0 和 block 1,方便初始化时重构文件系统信息。
根目录信息保存在 superblock 中。
超级块包含了一个超级块 tag:
1
2
3
4
5
6
7
8
tag data
[-- 32 --][-- 32 --|-- 32 --]
[1|- 11 -| 10 | 10 ][--- 64 ---]
^ ^ ^ ^- size (8) ^- magic string ("littlefs")
| | '------ id (0)
| '------------ type (0x0ff)
'----------------- valid bit
其中魔术字符串始终为”littlefs”
超级块还包含了一个内联结构,用于保存文件系统基本配置信息:
1
2
3
4
5
6
7
8
9
10
11
tag data
[-- 32 --][-- 32 --|-- 32 --|-- 32 --]
[1|- 11 -| 10 | 10 ][-- 32 --|-- 32 --|-- 32 --]
^ ^ ^ ^ ^- version ^- block size ^- block count
| | | | [-- 32 --|-- 32 --|-- 32 --]
| | | | [-- 32 --|-- 32 --|-- 32 --]
| | | | ^- name max ^- file max ^- attr max
| | | '- size (24)
| | '------ id (0)
| '------------ type (0x201)
'----------------- valid bit
该内联结构之后的内容都属于根目录。比如有个创建文件的操作,那么该文件就处于根目录中;如有个 LFS_TYPE_DIRSTRUCT tag,表示这个目录是根目录的直接下级目录
超级块实例
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
// 元数据对其一,块大小为128字节,这是块0
// 03 00 00 00为大端序下的版本号,标识元数据版本。
// F0 0F FF F7的反码为0FF00008,也就是实际的tag,0x0FF表示
// 超级块type,后面的id为0,长度为8,也就是魔术字符串长度。
// 6C 69 74 74 6C 65 66 73 为data内容,就是魔术字符串"littlefs"
03 00 00 00 F0 0F FF F7 6C 69 74 74 6C 65 66 73
// 至此,第一个tag结束,下面为第二个tag
// 第一个tag 0FF00008和2F E0 00 10的异或为20100018,也就是
// 第二个tag。0x201为内联结构type,长度为24字节,包含了文件系统信息
2F E0 00 10 00 00 02 00 80 00 00 00 00 01 00 00
// 第三个tag为601FFC08,就是40 0F FC 10和20100018的异或。
// type为0x601表示hardtail,长度为8,保存了一对元数据对指针
// hardtail表示下个元数据对属于本目录,这里就表示超级块的扩展
FF 00 00 00 FF FF FF 7F FE 03 00 00 40 0F FC 10
// 有00000007和00000008两个指针,使用小端序保存。
// 601FFC08和30 10 00 0C异或为500FFC04,0x5xx表示CRC,长度4字节
07 00 00 00 08 00 00 00 30 10 00 0C FD 32 76 C4
FF FF FF FF FF FF FF FF FF FF FF FF FF FF FF FF
FF FF FF FF FF FF FF FF FF FF FF FF FF FF FF FF
FF FF FF FF FF FF FF FF FF FF FF FF FF FF FF FF
FF FF FF FF FF FF FF FF FF FF FF FF FF FF FF FF
// 元数据对其二,块大小为128字节,这是块1
02 00 00 00 F0 0F FF F7 6C 69 74 74 6C 65 66 73
2F E0 00 10 00 00 02 00 80 00 00 00 00 01 00 00
// 这里的tag和上面的不同,70 1F FC 08和20100018异或为500FFC10
// 0x5xx表示CRC,长度为16字节,
FF 00 00 00 FF FF FF 7F FE 03 00 00 70 1F FC 08
// 实际CRC占用4字节,其他的是padding。
C5 D0 7E 55 FF FF FF FF FF FF FF FF FF FF FF FF
// 10 1F F8 10和500FFC10异或为40100400,0x401表示LFS_TYPE_CREATE,
// 也就是文件创建,长度为0。
// 下一个tag为0010040A(4000000A),0x001表示LFS_TYPE_REG常规文件,长度为10,
// 表示文件名长度,data域为文件名"boot_count"。
10 1F F8 10 40 00 00 0A 62 6F 6F 74 5F 63 6F 75
// 下个tag为20100400(2000000A),0x201表示内联结构,跟在
// 常规文件后的内联结构表示内联文件,初始长度为0,表示空文件。
// 下个tag为500FFC06(701FF806),0x5xx表示CRC,带padding共6字节。
6E 74 20 00 00 0A 70 1F F8 06 E8 5E F3 2D FF FF
// 下个tag为40100400(101FF806), 创建文件。
// 下个tag为0010040B(4000000B),LFS_TYPE_REG
10 1F F8 06 40 00 00 0B 62 6F 6F 74 5F 63 6F 75
// 下个tag为20100400(2000000B),内联结构
// 下个tag为500FFC05(701FF805),CRC
6E 74 30 20 00 00 0B 70 1F F8 05 6C 44 5F 4B FF
// 可以发现这个块没有hardtail,也就是说没有后续块,也就是说超级块已经结束了,
// 这个情况发生在仅创建了两个文件的情况下,在创建第三个文件时会发现不够用了,
// 就会重新整理超级块内容,将多余的日志通过hardtail连接到其他块来实现
// 对超级块的扩展,也就是上面那个版本3的块的内容
...
// 块7,块0的hardtail
// 第一个tag为0010000B(FFEFFFF4),因为重新整理后可以去掉create tag,
// 所以相较于版本2,这里没有了LFS_TYPE_CREATE,直接就是LFS_TYPE_REG
03 00 00 00 FF EF FF F4 62 6F 6F 74 5F 63 6F 75
// 下个tag为20100004(2000000F),内联结构,长度为4,
// data值为0,和测试程序相符。
// 下个tag为0010040C(20000408),表示文件"boot_count10"
6E 74 30 20 00 00 0F 00 00 00 00 20 00 04 08 62
// 下个tag为20100404(20000008),内联结构,长度为4,
// data值为0x0A,和测试程序相符。
6F 6F 74 5F 63 6F 75 6E 74 31 30 20 00 00 08 0A
00 00 00 40 0F F8 0C 11 00 00 00 12 00 00 00 30
10 00 05 10 A6 F0 25 FF FF FF FF FF FF FF FF FF
10 1F F8 0D 40 00 00 0D 62 6F 6F 74 5F 63 6F 75
6E 74 31 30 30 20 00 00 0D 70 1F F8 13 D5 83 93
2E FF FF FF FF FF FF FF FF FF FF FF FF FF FF FF
// 块8,块0的hardtail
04 00 00 00 FF EF FF F4 62 6F 6F 74 5F 63 6F 75
// 601FFC08(400FFC0C)表示hardtail
6E 74 30 20 00 00 0F 00 00 00 00 40 0F FC 0C 77
// 500FFC05(3010000D)表示CRC
00 00 00 78 00 00 00 30 10 00 0D AE E2 47 DD FF
// 后面这些不知道什么意义,照理说hardtail后不应该有数据
70 1F FC 01 00 00 00 00 70 1F FC 00 5D 1A 29 44
70 1F FC 00 00 00 00 00 70 1F FC 00 1E 0E 52 53
70 1F FC 00 00 00 00 00 70 1F FC 00 1E 0E 52 53
70 1F FC 00 00 00 00 00 70 1F FC 00 1E 0E 52 53
FF FF FF FF FF FF FF FF FF FF FF FF FF FF FF FF
元数据整理
当某一个元数据块写满时,需要删除不需要的条目来腾出空间,如下图,对文件 B 修改后,对 B 的本身来说 B’才是有效记录,记录 B 已经没用了,同时对 A 来说 A’是最新记录,记录 A 也没用了,这时就可以整理为 revision2 的形式。
这就是为什么元数据需要成对的原因,成对后两份元数据可以交替更新,保证写入时的一致性。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
commit B', need to compact
.----------------.----------------. .----------------.----------------.
| revision 1 | revision 0 | => | revision 1 | revision 2 |
|----------------|----------------| |----------------|----------------|
| A | | | A | A' |
|----------------| | |----------------|----------------|
| checksum | | | checksum | B' |
|----------------| | |----------------|----------------|
| B | | | B | checksum |
|----------------| | |----------------|----------------|
| A' | | | A' | | |
|----------------| | |----------------| v |
| checksum | | | checksum | |
|----------------| | |----------------| |
'----------------'----------------' '----------------'----------------'
元数据扩展
元数据的扩展有两种类型
拓展当前目录(hardtail)
如果没有垃圾数据无法通过整理的方式腾出空间,就要对元数据块做拓展,拓展块也是以元数据对的方式呈现,通过 tail 指针指向扩展元数据对。
我们可以将该元数据块和扩展的元数据块视为一个很大的元数据块,它们在逻辑上是连续的,且属于同一个目录。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
commit C and D, need to split
.----------------.----------------. .----------------.----------------.
| revision 1 | revision 2 | => | revision 3 | revision 2 |
|----------------|----------------| |----------------|----------------|
| A | A' | | A' | A' |
|----------------|----------------| |----------------|----------------|
| checksum | B' | | B' | B' |
|----------------|----------------| |----------------|----------------|
| B | checksum | | hardtail ---------------------.
|----------------|----------------| |----------------|----------------| |
| A' | | | | checksum | | |
|----------------| v | |----------------| | |
| checksum | | | | | | |
|----------------| | | v | | |
'----------------'----------------' '----------------'----------------' |
.----------------.---------'
v v
.----------------.----------------.
| revision 1 | revision 0 |
|----------------|----------------|
| C | |
|----------------| |
| D | |
|----------------| |
| checksum | |
|----------------| |
| | | |
| v | |
| | |
| | |
'----------------'----------------'
新建下级目录(softtail)
类似于 hardtail,softtail 用于指向下级目录的元数据对,且该目录不是本目录的扩展,遍历本目录时无需访问 softtail 指针。
块分配器
用于为 COW 系统分配新的块和管理空闲块。
空闲位图
可以在 RAM 中保存一份位图用于表示空闲的块,加速分配
1
2
3
4
5
6
7
8
.----.----.----.----.----.----.----.----.----.----.----.----.
| A | |root| C | B | | D | | E | |
| | | | | | | | | | |
'----'----'----'----'----'----'----'----'----'----'----'----'
1 0 1 1 1 0 0 1 0 1 0 0
\---------------------------+----------------------------/
v
bitmap: 0xb94 (0b101110010100)
优化位图容量
使用位图表示整个磁盘会带来大量的 RAM 消耗,littlefs 中的块分配器是位图和暴力遍历之间的折衷。
我们跟踪一个小的、固定大小的位图,称为先行缓冲区,而不是存储整个磁盘的位图。 在块分配期间,我们从先行缓冲区中获取块。 如果先行缓冲区为空,我们将扫描文件系统以寻找更多空闲块,填充我们的先行缓冲区。在每次扫描中,我们使用递增的偏移量,在分配块时循环存储。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
boot... lookahead:
fs blocks: fffff9fffffffffeffffffffffff0000
scanning... lookahead: fffff9ff
fs blocks: fffff9fffffffffeffffffffffff0000
alloc = 21 lookahead: fffffdff
fs blocks: fffffdfffffffffeffffffffffff0000
alloc = 22 lookahead: ffffffff
fs blocks: fffffffffffffffeffffffffffff0000
scanning... lookahead: fffffffe
fs blocks: fffffffffffffffeffffffffffff0000
alloc = 63 lookahead: ffffffff
fs blocks: ffffffffffffffffffffffffffff0000
scanning... lookahead: ffffffff
fs blocks: ffffffffffffffffffffffffffff0000
scanning... lookahead: ffffffff
fs blocks: ffffffffffffffffffffffffffff0000
scanning... lookahead: ffff0000
fs blocks: ffffffffffffffffffffffffffff0000
alloc = 112 lookahead: ffff8000
fs blocks: ffffffffffffffffffffffffffff8000
上图中 lookahead 就表示当前的缓冲位图,对于分配块来说,这样一个缓冲区就能实现找到最近一个空闲块的功能了。当缓冲区内找不到可用空闲块时就扫描下一个区域并构建新的缓冲区。
通过调整缓冲区大小来达到 RAM 占用和扫描效率之间的平衡
磨损均衡
坏块检测
通过写入后立刻回读进行坏块检测
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
.----.
|root|
| |
'----'
v--' '----------------------v
.----. .----.
| A | | B |
| | | |
'----' '----'
. . v---' .
. . .----. .
. . | C | .
. . | | .
. . '----' .
. . . . .
.----.----.----.----.----.----.----.----.----.----.
| A |root| | C | B | |
| | | | | | |
'----'----'----'----'----'----'----'----'----'----'
update C
=>
.----.
|root|
| |
'----'
v--' '----------------------v
.----. .----.
| A | | B |
| | | |
'----' '----'
. . v---' .
. . .----. .
. . |bad | .
. . |blck| .
. . '----' .
. . . . .
.----.----.----.----.----.----.----.----.----.----.
| A |root| |bad | B |bad | |
| | | |blck| |blck| |
'----'----'----'----'----'----'----'----'----'----'
--------->
oh no! bad block! relocate C(it happened twice)
=>
.----.
|root|
| |
'----'
v--' '----------------------v
.----. .----.
| A | | B |
| | | |
'----' '----'
. . v---' .
. . .----. . .----.
. . |bad | . | C' |
. . |blck| . | |
. . '----' . '----'
. . . . . . .
.----.----.----.----.----.----.----.----.----.----.
| A |root| |bad | B |bad | C' | |
| | | |blck| |blck| | |
'----'----'----'----'----'----'----'----'----'----'
-------------->
successfully relocated C, update B
=>
.----.
|root|
| |
'----'
v--' '----------------------v
.----. .----. .----.
| A | |bad | |bad |
| | |blck| |blck|
'----' '----' '----'
. . v---' . . .
. . .----. . .----. .
. . |bad | . | C' | .
. . |blck| . | | .
. . '----' . '----' .
. . . . . . . .
.----.----.----.----.----.----.----.----.----.----.
| A |root| |bad |bad |bad | C' |bad |
| | | |blck|blck|blck| |blck|
'----'----'----'----'----'----'----'----'----'----'
-------------->
oh no! bad block! relocate B(it happened twice)
=>
.----.
|root|
| |
'----'
v--' '----------------------v
.----. .----. .----.
| A | | B' | |bad |
| | | | |blck|
'----' '----' '----'
. . . | . .---' .
. . . '--------------v-------------v
. . . . .----. . .----.
. . . . |bad | . | C' |
. . . . |blck| . | |
. . . . '----' . '----'
. . . . . . . . .
.----.----.----.----.----.----.----.----.----.----.
| A |root| B' | |bad |bad |bad | C' |bad |
| | | | |blck|blck|blck| |blck|
'----'----'----'----'----'----'----'----'----'----'
------------> ------------------
successfully relocated B, update root
=>
.----.
|root|
| |
'----'
v--' '--v
.----. .----.
| A | | B' |
| | | |
'----' '----'
. . . '---------------------------v
. . . . .----.
. . . . | C' |
. . . . | |
. . . . '----'
. . . . . .
.----.----.----.----.----.----.----.----.----.----.
| A |root| B' | |bad |bad |bad | C' |bad |
| | | | |blck|blck|blck| |blck|
'----'----'----'----'----'----'----'----'----'----'
ECC 纠错
另一个方法是通过 ECC 算法为每个块纠错,但 littlefs 并不提供该功能。这需要硬件层面来实现。
静态磨损均衡
考虑已经使用的块和空闲块,让所有块的擦写次数都能达到均衡。也就是需要定时去挪动未被修改但已经使用的块,防止冷数据占用过长时间。
littlefs 不使用静态磨损均衡,但可以通过和 FTL 层结合可以实现完全的静态磨损均衡。
动态磨损均衡
仅考虑空闲块,对已经有数据的块不做考虑。为了简化操作,littlefs 不会去跟踪每个块的磨损情况
设备启动后随机确定开始位置,在运行过程中线性的寻找并分配空闲块,达到近似动态磨损均衡的效果。随机熵可以从当前所有文件的 CRC 中获取
目录
littlefs 中的目录作为元数据对的链接列表存储在磁盘上,元数据对包含按字母顺序排列的任意数量的文件。
1
2
3
4
5
6
7
8
|
v
.--------. .--------. .--------. .--------. .--------. .--------.
.| file A |->| file D |->| file G |->| file I |->| file J |->| file M |
|| file B | || file E | || file H | || | || file K | || file N |
|| file C | || file F | || | || | || file L | || |
|'--------' |'--------' |'--------' |'--------' |'--------' |'--------'
'--------' '--------' '--------' '--------' '--------' '--------'
元数据结构
type:0x200 LFS_TYPE_DIRSTRUCT
1
2
3
4
5
6
7
tag data
[-- 32 --][-- 32 --|-- 32 --]
[1|- 11 -| 10 | 10 ][--- 64 ---]
^ ^ ^ ^- size (8) ^- metadata pair
| | '------ id
| '------------ type (0x200)
'----------------- valid bit
- metadata pair(8 字节)- 指向存放目录的第一个元数据对的指针。
文件
littlefs 将文件信息作为元数据保存在元数据块中,包含了文件名和文件跳跃链表的头指针。如果文件占用多个块,就可以通过跳跃链表访问该文件的所有块。如果文件仅占用极小空间,那么为其单独分配一个跳跃链表都是很浪费的,此时可以直接把数据内容也写在元数据中,littlefs 将占用空间小于1/4个块大小的文件放置于元数据块中,称为内联文件。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
inline files stored in metadata pair, 4 bytes costs ~16 bytes
.----------------.
.| revision |
||----------------|
|| A name |
|| A skiplist ---.
||----------------| | \
|| B name | | +- data
|| B data | | | 4x4 bytes
||----------------| | / 16 bytes
|| checksum | |
||----------------| |
|| | | |
|| v | |
|'----------------' |
'----------------' |
.---------'
v
.----------------.
| A data |
| |
| |
| |
| |
| |
| |
| |
|----------------|
| |
| |
| |
'----------------'
其中 A 为外联文件,B 为内联文件
文件名
littlefs 使用一个文件 tag 标识一个文件,data 域是文件名,文件名占用空间为可变长空间:
1
2
3
4
5
6
7
8
tag data
[-- 32 --][--- variable length ---]
[1| 3| 8 | 10 | 10 ][--- (size * 8) ---]
^ ^ ^ ^ ^- size ^- file name
| | | '------ id
| | '----------- file type
| '-------------- type1 (0x0)
'----------------- valid bit
内联文件
内联文件使用内联结构(type:0x201)来保存文件内容,紧跟在文件 tag 之后:
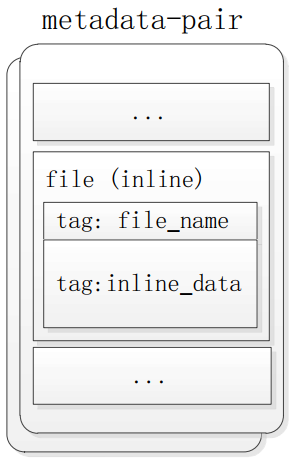
1
2
3
4
5
6
7
tag data
[-- 32 --][--- variable length ---]
[1|- 11 -| 10 | 10 ][--- (size * 8) ---]
^ ^ ^ ^- size ^- inline data
| | '------ id
| '------------ type (0x201)
'----------------- valid bit
外联文件
外联文件的内容不存于元数据块,元数据块中仅保存 ctz 跳跃链表头指针。
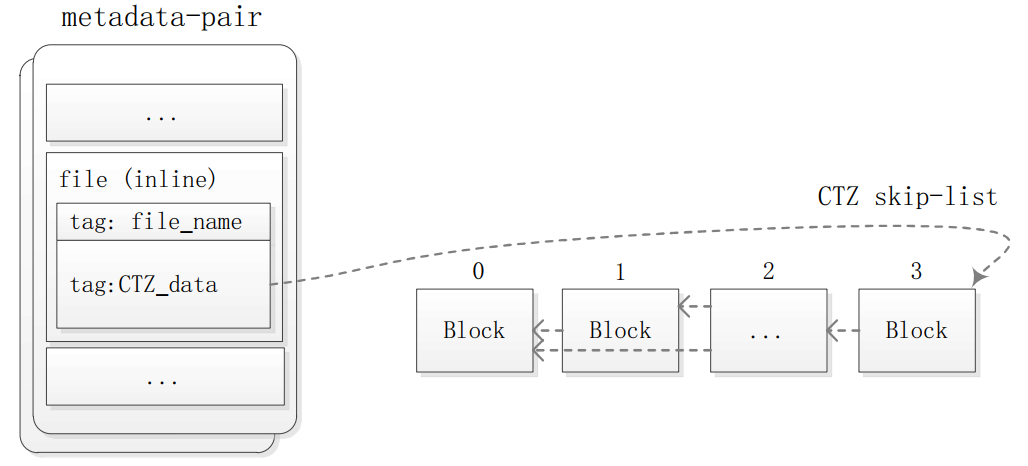
图中的
inline应该改为outline
CTZ skip-lists 跳跃链表
littlefs 通过链表方式管理文件对应的块
前序链表
每个节点存放执行新节点的指针,最大的问题是每增加一个节点(写入新数据,节点就是 block)都要修改原来的节点。因为 COW 策略被修改的节点必须挪动到新位置,导致该节点的上一个节点也要修改指针用于指向该节点的新位置,最终导致所有节点都被挪动。
1
2
3
4
5
6
A linked-list
.--------. .--------. .--------. .--------. .--------. .--------.
| data 0 |->| data 1 |->| data 2 |->| data 4 |->| data 5 |->| data 6 |
| | | | | | | | | | | |
| | | | | | | | | | | |
'--------' '--------' '--------' '--------' '--------' '--------'
后序链表
每个节点存放前一个节点的指针,此时增加节点不会导致之前节点的改动。
1
2
3
4
5
6
A backwards linked-list
.--------. .--------. .--------. .--------. .--------. .--------.
| data 0 |<-| data 1 |<-| data 2 |<-| data 4 |<-| data 5 |<-| data 6 |
| | | | | | | | | | | |
| | | | | | | | | | | |
'--------' '--------' '--------' '--------' '--------' '--------'
但是遍历方向变为了和前序链表相反。如果要按顺序读取该文件的所有块,就需要从 6 遍历到 0 来读取 0,从 6 遍历到 1 来读取 1,以此类推,复杂度为 $O(n^2)$ 。
后序跳跃链表
为了避免后序遍历情况下顺序读取性能差的问题,littlefs 使用了跳跃链表的方式。若一个数据块在 CTZ skip-list 链表内的索引值 N 能被 $2^x$ 整除,那么他就存在指向 $N – 2^x$ 的指针,指针的数目为 $ctz(N)+1$。如表 1,对于 block 2,包含了 2 个指针,分别指向 block 0 和 block 1,其它块也是采用相同的规则
1
2
3
4
5
6
A backwards CTZ skip-list
.--------. .--------. .--------. .--------. .--------. .--------.
| data 0 |<-| data 1 |<-| data 2 |<-| data 3 |<-| data 4 |<-| data 5 |
| |<-| |--| |<-| |--| | | |
| |<-| |--| |--| |--| | | |
'--------' '--------' '--------' '--------' '--------' '--------'
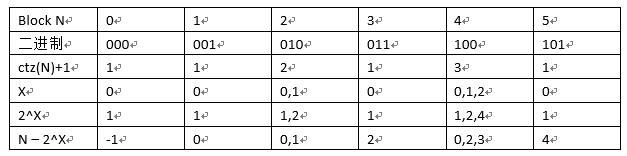
以此类推,6 为 3 个,8 为 4 个,非 2 的幂的偶数的指针数和上一个 2 的幂的偶数的指针数相同,平均下来每个块包含了大约两个指针。
汇编中 CTZ 指令的意思是求 $log_2{x}$,计算方法是取数字二进制格式末尾 0 的数量,这里用 CTZ 作为名字的意思是每个节点的指针数量为 CTZ(x)+1,如 8 末尾 0 的数量是 3,CTZ(x)就是 3,指针数量就是 3+1=4 个。
这样一来反向遍历的速度能加快。顺序遍历时间复杂度变为 $O(nlogn)$。
CTZ skip-list 结构
只需要 4 字节的文件指针和 4 字节的文件大小信息,其中文件指针指向一个单独的块(CTZ 表头),也就是说该文件至少会占用一个完整块。
1
2
3
4
5
6
7
8
9
tag data
[-- 32 --][-- 32 --|-- 32 --]
[1|- 11 -| 10 | 10 ][-- 32 --|-- 32 --]
^ ^ ^ ^ ^ ^- file size
| | | | '-------------------- file head
| | | '- size (8)
| | '------ id
| '------------ type (0x202)
'----------------- valid bit
实现
格式化
创建超级块,并将文件系统信息写入超级块
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
static int lfs_rawformat(lfs_t *lfs, const struct lfs_config *cfg) {
int err = 0;
{
// 使用入参的默认配置
err = lfs_init(lfs, cfg);
if (err) {
return err;
}
// create free lookahead
memset(lfs->free.buffer, 0, lfs->cfg->lookahead_size);
lfs->free.off = 0;
lfs->free.size = lfs_min(8*lfs->cfg->lookahead_size,
lfs->cfg->block_count);
lfs->free.i = 0;
lfs_alloc_ack(lfs);
// create root dir
lfs_mdir_t root;
// lfs_dir_alloc用于分配元数据块,每个元数据块都有两个块,用于表示元数据对
err = lfs_dir_alloc(lfs, &root);
if (err) {
goto cleanup;
}
// write one superblock
lfs_superblock_t superblock = {
.version = LFS_DISK_VERSION,
.block_size = lfs->cfg->block_size,
.block_count = lfs->cfg->block_count,
.name_max = lfs->name_max,
.file_max = lfs->file_max,
.attr_max = lfs->attr_max,
};
lfs_superblock_tole32(&superblock);
// 创建一个元数据提交,包含create,superblock和内联结构
err = lfs_dir_commit(lfs, &root, LFS_MKATTRS(
{LFS_MKTAG(LFS_TYPE_CREATE, 0, 0), NULL},
{LFS_MKTAG(LFS_TYPE_SUPERBLOCK, 0, 8), "littlefs"},
{LFS_MKTAG(LFS_TYPE_INLINESTRUCT, 0, sizeof(superblock)),
&superblock}));
if (err) {
goto cleanup;
}
// force compaction to prevent accidentally mounting any
// older version of littlefs that may live on disk
root.erased = false;
err = lfs_dir_commit(lfs, &root, NULL, 0);
if (err) {
goto cleanup;
}
// sanity check that fetch works
err = lfs_dir_fetch(lfs, &root, (const lfs_block_t[2]){0, 1});
if (err) {
goto cleanup;
}
}
cleanup:
lfs_deinit(lfs);
return err;
}
挂载
读取超级块中的文件系统信息,启动文件系统的内存实例
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
164
165
166
167
168
169
static int lfs_rawmount(lfs_t *lfs, const struct lfs_config *cfg) {
// 使用默认配置初始化lfs结构
int err = lfs_init(lfs, cfg);
if (err) {
return err;
}
// scan directory blocks for superblock and any global updates
// 扫描所有目录,因为根目录信息在超级块中,所以先从超级块所在的块0和块1开始扫描
lfs_mdir_t dir = {.tail = {0, 1}};
lfs_block_t cycle = 0;
while (!lfs_pair_isnull(dir.tail)) {
// 回环检测
if (cycle >= lfs->cfg->block_count/2) {
// loop detected
err = LFS_ERR_CORRUPT;
goto cleanup;
}
cycle += 1;
// fetch next block in tail list
// 从tail找下一个元数据对(属于超级块)
/** lfs_dir_fetchmatch用于找出元数据对中tag和data都符合参数描述条件的tag,这里是
* 为了查找当前块是否是超级块,也就是是否有超级块tag和包含魔术字符串的data。还有将
* 元数据对中信息赋值到dir内的功能,比如版本号,offset偏移,tail指针等等
*/
// lfs_dir_find_match用于比较两个tag内的data是否相同,这里是要找到data为"littlefs"的tag,也就是超级块标志。
lfs_stag_t tag = lfs_dir_fetchmatch(lfs, &dir, dir.tail,
LFS_MKTAG(0x7ff, 0x3ff, 0),
LFS_MKTAG(LFS_TYPE_SUPERBLOCK, 0, 8),
NULL,
lfs_dir_find_match, &(struct lfs_dir_find_match){
lfs, "littlefs", 8});
/**
* lfs:文件系统信息实例,
* dir:RAM里的mdir结构,此处用于出参,
* pair:需要搜索的元数据对的块指针,
* fmask:tag的mask(表示tag的32位中需要比较的部分),
* ftag:需要搜索的tag,
* id:需要搜索的id,
* cb:data部分比较函数,
* data:需要搜索的data
*/
// static lfs_stag_t lfs_dir_fetchmatch(lfs_t *lfs,
// lfs_mdir_t *dir, const lfs_block_t pair[2],
// lfs_tag_t fmask, lfs_tag_t ftag, uint16_t *id,
// int (*cb)(void *data, lfs_tag_t tag, const void *buffer), void *data)
if (tag < 0) {
err = tag;
goto cleanup;
}
// has superblock?
if (tag && !lfs_tag_isdelete(tag)) {
// update root
// 更新lfs的超级块信息对应的元数据对,一般就是物理块的块0和块1
lfs->root[0] = dir.pair[0];
lfs->root[1] = dir.pair[1];
// grab superblock
lfs_superblock_t superblock;
// 获取超级块内的内联结构,包含了文件系统配置信息
tag = lfs_dir_get(lfs, &dir, LFS_MKTAG(0x7ff, 0x3ff, 0),
LFS_MKTAG(LFS_TYPE_INLINESTRUCT, 0, sizeof(superblock)),
&superblock);
if (tag < 0) {
err = tag;
goto cleanup;
}
lfs_superblock_fromle32(&superblock);
// 检测文件系统配置信息是否合法,并更新到内存实例中
// check version
uint16_t major_version = (0xffff & (superblock.version >> 16));
uint16_t minor_version = (0xffff & (superblock.version >> 0));
if ((major_version != LFS_DISK_VERSION_MAJOR ||
minor_version > LFS_DISK_VERSION_MINOR)) {
LFS_ERROR("Invalid version v%"PRIu16".%"PRIu16,
major_version, minor_version);
err = LFS_ERR_INVAL;
goto cleanup;
}
// check superblock configuration
if (superblock.name_max) {
if (superblock.name_max > lfs->name_max) {
LFS_ERROR("Unsupported name_max (%"PRIu32" > %"PRIu32")",
superblock.name_max, lfs->name_max);
err = LFS_ERR_INVAL;
goto cleanup;
}
lfs->name_max = superblock.name_max;
}
if (superblock.file_max) {
if (superblock.file_max > lfs->file_max) {
LFS_ERROR("Unsupported file_max (%"PRIu32" > %"PRIu32")",
superblock.file_max, lfs->file_max);
err = LFS_ERR_INVAL;
goto cleanup;
}
lfs->file_max = superblock.file_max;
}
if (superblock.attr_max) {
if (superblock.attr_max > lfs->attr_max) {
LFS_ERROR("Unsupported attr_max (%"PRIu32" > %"PRIu32")",
superblock.attr_max, lfs->attr_max);
err = LFS_ERR_INVAL;
goto cleanup;
}
lfs->attr_max = superblock.attr_max;
}
if (superblock.block_count != lfs->cfg->block_count) {
LFS_ERROR("Invalid block count (%"PRIu32" != %"PRIu32")",
superblock.block_count, lfs->cfg->block_count);
err = LFS_ERR_INVAL;
goto cleanup;
}
if (superblock.block_size != lfs->cfg->block_size) {
LFS_ERROR("Invalid block size (%"PRIu32" != %"PRIu32")",
superblock.block_size, lfs->cfg->block_size);
err = LFS_ERR_INVAL;
goto cleanup;
}
}
// has gstate?
err = lfs_dir_getgstate(lfs, &dir, &lfs->gstate);
if (err) {
goto cleanup;
}
}
// found superblock?
if (lfs_pair_isnull(lfs->root)) {
err = LFS_ERR_INVAL;
goto cleanup;
}
// update littlefs with gstate
if (!lfs_gstate_iszero(&lfs->gstate)) {
LFS_DEBUG("Found pending gstate 0x%08"PRIx32"%08"PRIx32"%08"PRIx32,
lfs->gstate.tag,
lfs->gstate.pair[0],
lfs->gstate.pair[1]);
}
lfs->gstate.tag += !lfs_tag_isvalid(lfs->gstate.tag);
lfs->gdisk = lfs->gstate;
// 更新空闲块位图的lookahead信息,seed表示随机种子,在lfs_dir_fetchmatch函数内通过CRC计算
// setup free lookahead, to distribute allocations uniformly across
// boots, we start the allocator at a random location
lfs->free.off = lfs->seed % lfs->cfg->block_count;
lfs_alloc_drop(lfs);
return 0;
cleanup:
lfs_rawunmount(lfs);
return err;
}
打开目录
根据路径查找并打开目录
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
// 获取文件对应的元数据信息,保存在出参dir中,
// 获取文件的id信息,保存在出参id中
static lfs_stag_t lfs_dir_find(lfs_t *lfs, lfs_mdir_t *dir,
const char **path, uint16_t *id) {
// we reduce path to a single name if we can find it
const char *name = *path;
// 0x3ff表示目录
if (id) {
*id = 0x3ff;
}
// default to root dir
// 从根目录开始搜索
lfs_stag_t tag = LFS_MKTAG(LFS_TYPE_DIR, 0x3ff, 0);
dir->tail[0] = lfs->root[0];
dir->tail[1] = lfs->root[1];
while (true) {
nextname:
// skip slashes
// strspn用于找到第一个不是'/'的字符(过滤第一个'/')
name += strspn(name, "/");
// strcspn用于找到第一个'/'字符,找到的就是路径第一部分(找第一层目录)
lfs_size_t namelen = strcspn(name, "/");
// skip '.' and root '..'
// 第一层路径不支持.和..,跳过
if ((namelen == 1 && memcmp(name, ".", 1) == 0) ||
(namelen == 2 && memcmp(name, "..", 2) == 0)) {
name += namelen;
goto nextname;
}
// skip if matched by '..' in name
/** 下面这个循环用于过滤路径字符串中无效的部分,
* 比如'/abc/../cba'中'/abc/..'是进入后返回,
* 对目录定位并没有作用,防止后续的目录进入退出操作查找元数据对消耗无谓的时间。
* /
/** 不过通过这种方式过滤就没办法判断目录的有效性了,
* 比如abc本就不是根目录下的目录,就判断不出来
*/
const char *suffix = name + namelen;
lfs_size_t sufflen;
// 初始化深度为1,这个变量仅用于下面循环的字符串过滤功能
int depth = 1;
while (true) {
suffix += strspn(suffix, "/");
sufflen = strcspn(suffix, "/");
if (sufflen == 0) {
// 找不到后续的'/',说明是路径的最后一部分
break;
}
if (sufflen == 2 && memcmp(suffix, "..", 2) == 0) {
// ..表示上级目录,深度减1
depth -= 1;
if (depth == 0) {
// 深度为0,表示返回了进入本循环前的目录
// 这种情况就要过滤掉
name = suffix + sufflen;
goto nextname;
}
} else {
// 进入下层目录并继续循环
depth += 1;
}
suffix += sufflen;
}
// found path
// 路径字符串遍历完毕,且参数内的元数据内容(dir和id)已赋值,可以返回
if (name[0] == '\0') {
return tag;
}
// update what we've found so far
// 修改path指针,偏移到新的位置,path对应字符串占用空间由调用者负责回收,
// 头指针也由调用者保管,所以可以修改这个参数。
*path = name;
// only continue if we hit a directory
// 这之后的部分是从目录中查找下层目录,所以当前的tag变量必须表示目录。
// tag默认是LFS_TYPE_DIR类型
if (lfs_tag_type3(tag) != LFS_TYPE_DIR) {
return LFS_ERR_NOTDIR;
}
// grab the entry data
// 开始寻找目录的元数据块信息,该操作相对于打开目录,更新dir变量信息,
// 因为根目录默认就是打开状态,就不需要这一步
if (lfs_tag_id(tag) != 0x3ff) {
// LFS_TYPE_STRUCT的tag为0x2xx,xx表示可以为任意值,目前有0x200,0x201,0x202,
// 只要前三位等于0x2就可以,所以第三个参数gmask需要为0x700,
// 表示只判断tag的前3位
/** 用于获取内联结构,包含了下层目录的元数据对指针。
* 在上一个循环中,dir已经更新为包含下层目录的元数据对,
* 且dir->off偏移也已经指向了0x002:LFS_TYPE_DIR之后
*(上面的lfs_tag_type3(tag) != LFS_TYPE_DIR就是用于判断这个的),
* 那么下个tag就是包含下层目录元数据指针的内联结构,
* 将这个信息赋值给dir->tail(这里应该是为了节省空间,重用变量了,
* 正常应该单独使用一个tail变量专门存放这个数据,防止混淆)
*/
lfs_stag_t res = lfs_dir_get(lfs, dir, LFS_MKTAG(0x700, 0x3ff, 0),
LFS_MKTAG(LFS_TYPE_STRUCT, lfs_tag_id(tag), 8), dir->tail);
if (res < 0) {
return res;
}
// 大小端转换,存在存储中的是小端序,放到RAM里需要依据CPU实际字节序
lfs_pair_fromle32(dir->tail);
}
// find entry matching name
// 在当前打开的目录下查找对应的目录(或文件)
while (true) {
// 查找元数据对中的LFS_TYPE_NAME tag,data域为文件名
// LFS_TYPE_NAME包含0x002:LFS_TYPE_DIR和0x001:LFS_TYPE_REG
// 如果是路径最后一部分这里查找的就是LFS_TYPE_REG,否则是LFS_TYPE_DIR
tag = lfs_dir_fetchmatch(lfs, dir, dir->tail,
LFS_MKTAG(0x780, 0, 0),
LFS_MKTAG(LFS_TYPE_NAME, 0, namelen),
// are we last name?
// 查找第一次出现'/'的位置,如果为NULL表示没有后续了,
// 路径最后一部分应该就是表示文件,id是指针,作为该函数的出参
// id就是这个文件的id
(strchr(name, '/') == NULL) ? id : NULL,
lfs_dir_find_match, &(struct lfs_dir_find_match){
lfs, name, namelen});
// 当前打开的目录下有需要查找的目录(或文件),表示路径不合法
if (tag < 0) {
return tag;
}
// 当前打开的目录下有需要查找的目录(或文件)
if (tag) {
break;
}
// dir->split为true表示元数据对有后续内容,需要继续读取tail,
// 否则就说明是目录元数据的最后一个元数据对,没有后续内容,不用再继续查找了。
if (!dir->split) {
return LFS_ERR_NOENT;
}
}
// to next name
name += namelen;
}
}
打开文件(新建文件)
读取文件信息,并构建句柄
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
164
165
166
167
168
169
170
171
172
173
174
175
176
177
178
179
180
181
182
183
184
185
186
187
188
189
190
191
192
193
194
195
196
197
198
199
200
201
202
203
204
205
206
// lfs.h
// 文件句柄结构,占用104字节
typedef struct lfs_file {
struct lfs_file *next;
uint16_t id;
uint8_t type;
// 元数据信息
lfs_mdir_t m;
struct lfs_ctz {
// block序号,不是指针
lfs_block_t head;
lfs_size_t size;
} ctz;
uint32_t flags;
lfs_off_t pos;
// 临时保存某个块序号
lfs_block_t block;
// 临时保存块内偏移
lfs_off_t off;
lfs_cache_t cache;
const struct lfs_file_config *cfg;
} lfs_file_t;
// lfs.c
static int lfs_file_rawopencfg(lfs_t *lfs, lfs_file_t *file,
const char *path, int flags,
const struct lfs_file_config *cfg) {
#ifndef LFS_READONLY
// deorphan if we haven't yet, needed at most once after poweron
if ((flags & LFS_O_WRONLY) == LFS_O_WRONLY) {
int err = lfs_fs_forceconsistency(lfs);
if (err) {
return err;
}
}
#else
LFS_ASSERT((flags & LFS_O_RDONLY) == LFS_O_RDONLY);
#endif
// setup simple file details
// 初始化句柄对象
int err;
file->cfg = cfg;
file->flags = flags;
file->pos = 0;
file->off = 0;
file->cache.buffer = NULL;
// allocate entry for file if it doesn't exist
lfs_stag_t tag = lfs_dir_find(lfs, &file->m, &path, &file->id);
if (tag < 0 && !(tag == LFS_ERR_NOENT && file->id != 0x3ff)) {
err = tag;
goto cleanup;
}
// get id, add to list of mdirs to catch update changes
file->type = LFS_TYPE_REG;
// 追加到文件系统对象的已打开文件列表(链表)。
// 通过RAM空间换取搜索的时间,下次对该文件的操作无需重复搜索文件物理位置
lfs_mlist_append(lfs, (struct lfs_mlist *)file);
#ifdef LFS_READONLY
if (tag == LFS_ERR_NOENT) {
err = LFS_ERR_NOENT;
goto cleanup;
#else
// 如果最终文件不存在
if (tag == LFS_ERR_NOENT) {
// 如果包含<不存在就创建>标识(LFS_O_CREAT),则创建文件
if (!(flags & LFS_O_CREAT)) {
err = LFS_ERR_NOENT;
goto cleanup;
}
// check that name fits
lfs_size_t nlen = strlen(path);
if (nlen > lfs->name_max) {
err = LFS_ERR_NAMETOOLONG;
goto cleanup;
}
// get next slot and create entry to remember name
err = lfs_dir_commit(lfs, &file->m, LFS_MKATTRS(
{LFS_MKTAG(LFS_TYPE_CREATE, file->id, 0), NULL},
{LFS_MKTAG(LFS_TYPE_REG, file->id, nlen), path},
{LFS_MKTAG(LFS_TYPE_INLINESTRUCT, file->id, 0), NULL}));
// it may happen that the file name doesn't fit in the metadata blocks, e.g., a 256 byte file name will
// not fit in a 128 byte block.
err = (err == LFS_ERR_NOSPC) ? LFS_ERR_NAMETOOLONG : err;
if (err) {
goto cleanup;
}
tag = LFS_MKTAG(LFS_TYPE_INLINESTRUCT, 0, 0);
}
// LFS_O_EXCL:如果文件已经存在则失败,一般在创建文件时使用
else if (flags & LFS_O_EXCL) {
err = LFS_ERR_EXIST;
goto cleanup;
#endif
}
// 如果tag成功返回但不是文件,也失败,也就是路径里只有目录没有文件
else if (lfs_tag_type3(tag) != LFS_TYPE_REG) {
err = LFS_ERR_ISDIR;
goto cleanup;
#ifndef LFS_READONLY
}
// LFS_O_TRUNC:清空文件
else if (flags & LFS_O_TRUNC) {
// truncate if requested
tag = LFS_MKTAG(LFS_TYPE_INLINESTRUCT, file->id, 0);
file->flags |= LFS_F_DIRTY;
#endif
} else {
// 从file->m文件元数据中获取指向文件内容的指针,可能是内联结构,
// 后面处理
// try to load what's on disk, if it's inlined we'll fix it later
tag = lfs_dir_get(lfs, &file->m, LFS_MKTAG(0x700, 0x3ff, 0),
LFS_MKTAG(LFS_TYPE_STRUCT, file->id, 8), &file->ctz);
if (tag < 0) {
err = tag;
goto cleanup;
}
lfs_ctz_fromle32(&file->ctz);
}
// fetch attrs
for (unsigned i = 0; i < file->cfg->attr_count; i++) {
// if opened for read / read-write operations
if ((file->flags & LFS_O_RDONLY) == LFS_O_RDONLY) {
lfs_stag_t res = lfs_dir_get(lfs, &file->m,
LFS_MKTAG(0x7ff, 0x3ff, 0),
LFS_MKTAG(LFS_TYPE_USERATTR + file->cfg->attrs[i].type,
file->id, file->cfg->attrs[i].size),
file->cfg->attrs[i].buffer);
if (res < 0 && res != LFS_ERR_NOENT) {
err = res;
goto cleanup;
}
}
#ifndef LFS_READONLY
// if opened for write / read-write operations
if ((file->flags & LFS_O_WRONLY) == LFS_O_WRONLY) {
if (file->cfg->attrs[i].size > lfs->attr_max) {
err = LFS_ERR_NOSPC;
goto cleanup;
}
file->flags |= LFS_F_DIRTY;
}
#endif
}
// allocate buffer if needed
if (file->cfg->buffer) {
file->cache.buffer = file->cfg->buffer;
} else {
file->cache.buffer = lfs_malloc(lfs->cfg->cache_size);
if (!file->cache.buffer) {
err = LFS_ERR_NOMEM;
goto cleanup;
}
}
// zero to avoid information leak
lfs_cache_zero(lfs, &file->cache);
// 如果是内联结构
if (lfs_tag_type3(tag) == LFS_TYPE_INLINESTRUCT) {
// load inline files
file->ctz.head = LFS_BLOCK_INLINE;
file->ctz.size = lfs_tag_size(tag);
file->flags |= LFS_F_INLINE;
file->cache.block = file->ctz.head;
file->cache.off = 0;
file->cache.size = lfs->cfg->cache_size;
// don't always read (may be new/trunc file)
if (file->ctz.size > 0) {
lfs_stag_t res = lfs_dir_get(lfs, &file->m,
LFS_MKTAG(0x700, 0x3ff, 0),
LFS_MKTAG(LFS_TYPE_STRUCT, file->id,
lfs_min(file->cache.size, 0x3fe)),
file->cache.buffer);
if (res < 0) {
err = res;
goto cleanup;
}
}
}
return 0;
cleanup:
// clean up lingering resources
#ifndef LFS_READONLY
file->flags |= LFS_F_ERRED;
#endif
lfs_file_rawclose(lfs, file);
return err;
}
文件读取
读取文件内容
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
// 从ctz中寻找需要读取的块序号和块内偏移
static int lfs_ctz_find(lfs_t *lfs,
const lfs_cache_t *pcache, lfs_cache_t *rcache,
lfs_block_t head, lfs_size_t size,
lfs_size_t pos, lfs_block_t *block, lfs_off_t *off) {
if (size == 0) {
*block = LFS_BLOCK_NULL;
*off = 0;
return 0;
}
// 跳跃链表当前指针位置
lfs_off_t current = lfs_ctz_index(lfs, &(lfs_off_t){size-1});
// 跳跃链表目标指针位置
lfs_off_t target = lfs_ctz_index(lfs, &pos);
// 因为是反向链表,当前序号(地址)总是比目标的大
while (current > target) {
lfs_size_t skip = lfs_min(
// 大于或等于参数的最小2的幂的指数部分,如参数3返回为2,因为2^2大于3,
// ctz序号中2的幂的块之间都有直接指针连接,以实现快速跳跃
lfs_npw2(current-target+1) - 1,
// ctz算法,找后导0数量,奇数恒为0,
// 该位置指针直接指向ctz链表中的0块
lfs_ctz(current));
// 从这可以看出ctz指针是存储在块开头位置的,
// 以4个字节的块序号表示,根据ctz链表的规则,
// 奇数块存储1个指针,偶数块存储多个指针
int err = lfs_bd_read(lfs,
pcache, rcache, sizeof(head),
head, 4*skip, &head, sizeof(head));
head = lfs_fromle32(head);
if (err) {
return err;
}
current -= 1 << skip;
}
*block = head;
*off = pos;
return 0;
}
static lfs_ssize_t lfs_file_flushedread(lfs_t *lfs, lfs_file_t *file,
void *buffer, lfs_size_t size) {
uint8_t *data = buffer;
lfs_size_t nsize = size;
// 当前指针在文件末尾不读取
if (file->pos >= file->ctz.size) {
// eof if past end
return 0;
}
size = lfs_min(size, file->ctz.size - file->pos);
nsize = size;
while (nsize > 0) {
// check if we need a new block
// 如果是第一次读取文件(未被读取过),或上一次读取到达了block的末尾
if (!(file->flags & LFS_F_READING) ||
// 是否达到一个block的末尾,需要跳到下个block,
// off表示一个block内的偏移
file->off == lfs->cfg->block_size) {
// 非内联文件
if (!(file->flags & LFS_F_INLINE)) {
// 找到pos所在的块序号和块内偏移,
// file->block和file->off作为出参
int err = lfs_ctz_find(lfs, NULL, &file->cache,
file->ctz.head, file->ctz.size,
file->pos, &file->block, &file->off);
if (err) {
return err;
}
// 内联文件
} else {
// 定义#define LFS_BLOCK_INLINE ((lfs_block_t)-2),
// 保证不会和可用的块序号重复
file->block = LFS_BLOCK_INLINE;
file->off = file->pos;
}
file->flags |= LFS_F_READING;
}
// 每次都读到block的末尾或达到要读取的size
// read as much as we can in current block
lfs_size_t diff = lfs_min(nsize, lfs->cfg->block_size - file->off);
if (file->flags & LFS_F_INLINE) {
int err = lfs_dir_getread(lfs, &file->m,
NULL, &file->cache, lfs->cfg->block_size,
LFS_MKTAG(0xfff, 0x1ff, 0),
LFS_MKTAG(LFS_TYPE_INLINESTRUCT, file->id, 0),
file->off, data, diff);
if (err) {
return err;
}
} else {
// 从block的off位置开始读取diff长度到data
int err = lfs_bd_read(lfs,
NULL, &file->cache, lfs->cfg->block_size,
file->block, file->off, data, diff);
if (err) {
return err;
}
}
file->pos += diff;
file->off += diff;
data += diff;
nsize -= diff;
}
return size;
}
文件写入
追加写入:指针偏移到文件末尾,并追加写入(写时复制)
1 2 3 4 5 6 7 8 9 10 11 12
.--------. .--------. .--------. .--------. | data 0 |<-| data 1 |<-| data 2 |<-- | data 4 | | | | | | |<-. | | | | | | | | | | | '--------' '--------' '--------' | '--------' | | | .--------. '-| data 4'|<-ctz.head | | | | '--------'- 扩展写入:指针偏移到文件末尾并逐字节写 0(写时复制),直到指针偏移到需要写入的位置,再追加写入(写时复制)
中间修改:指针偏移到要修改的位置,通过写时复制创建要修改的块的副本(仅拷贝本块头部到指针前的内容),从指针位置追加写入,注意只支持修改(覆盖),不支持插入(这很正常,Linux 内核的 write 系统调用也不能插入),也就是文件大小一般不会变。此时新修改的数据并没有合并到原 ctz 链上,后续如果有函数调用了 rawflush(如 close 的时候),那么会从 pos 位置开始到 ctz.size 拷贝原 ctz 链上的数据逐字节拷贝到当前文件,此时就会产生新的 ctz 链,直到最后修改完 ctz.head 启用新链。
修改位于 data3 的数据(长度横跨 data3 和 data4)
1 2 3 4 5 6 7 8 9 10 11
.--------. .--------. .--------. .--------. .--------. .--------. | data 0 |<-| data 1 |<-| data 2 |<-- | data 3 |<-| data 4 |<-| data 5 |<-ctz.head | | | | | |<-. | | | | | | | | | | | | | | | | | | | '--------' '--------' '--------' | '--------' '--------' '--------' | | .--------. .--------. '-| data 3'|<-| data 4'| | | | | | | | | '--------' '--------'调用 flush 后
1 2 3 4 5 6 7 8 9 10 11 12
.--------. .--------. .--------. .--------. .--------. .--------. | data 0 |<-| data 1 |<-| data 2 |<-- | data 3 |<-| data 4 |<-| data 5 | | | | | | |<-. | | | | | | | | | | | | | | | | | | | '--------' '--------' '--------' | '--------' '--------' '--------' | |(copy) | v | .--------. .--------. .--------. '-| data 3'|<-| data 4'|<-| data 5'|<-ctz.head | | | | | | | | | | | | '--------' '--------' '--------'
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
164
165
166
167
168
169
170
171
172
173
174
175
176
177
178
179
180
181
182
183
184
185
186
187
188
189
190
191
192
193
194
195
196
197
198
199
200
201
202
203
204
205
206
207
208
209
210
211
212
213
214
215
216
217
218
219
220
221
222
223
224
225
226
227
228
229
230
231
232
233
234
235
236
237
238
239
240
241
242
243
244
245
246
247
248
249
250
251
252
253
254
255
256
257
258
259
260
261
262
263
264
265
266
267
268
269
270
271
272
273
274
275
// 扩展ctz链表
// head:从该块开始扩展
// size:一般表示pos,表示要写入的位置
static int lfs_ctz_extend(lfs_t *lfs,
lfs_cache_t *pcache, lfs_cache_t *rcache,
lfs_block_t head, lfs_size_t size,
lfs_block_t *block, lfs_off_t *off) {
// 这里的while循环只用于新块为坏块时继续尝试分配新块
while (true) {
// go ahead and grab a block
lfs_block_t nblock;
// 从空闲块位图找一个空闲块
int err = lfs_alloc(lfs, &nblock);
if (err) {
return err;
}
{
// 首次使用要先擦除
err = lfs_bd_erase(lfs, nblock);
if (err) {
if (err == LFS_ERR_CORRUPT) {
goto relocate;
}
return err;
}
if (size == 0) {
*block = nblock;
*off = 0;
return 0;
}
// size表示希望扩展到的文件总长度
// size位置如果是追加写入可能还不存在,而size-1位置为已有数据,
// 必定存在
lfs_size_t noff = size - 1;
// 计算该位置的块序号和偏移
lfs_off_t index = lfs_ctz_index(lfs, &noff);
// 偏移加一定位到实际要写的位置
noff = noff + 1;
// just copy out the last block if it is incomplete
// 如果noff和block_size不相同,表示要写的位置还在本块内,
// 使用写时复制,把noff前的原数据先拷贝到新块
// TODO:只写一个字节且是追加写入的情况也要用到写时复制吗,
// 这未免太浪费了?(块的第一次写会使用写时复制创建副本,后续不会)
// TODO:为什么一个字节一个字节拷贝,而不是整段拷贝?(可能利用了缓存让写入不那么频繁)
// TODO:只拷贝noff前的数据,意味着本块后面的数据都丢了?
// 如果是中间插入的情况呢?(rawclose调用lfs_file_rawsync调用lfs_file_flush,
// 将所有pos到ctz->size间原来的数据逐字节通过rawwrite写入,该操作会导致
// ctz后续所有块的新的分配,全部处理完后相对于后续链表的重新构建)
if (noff != lfs->cfg->block_size) {
for (lfs_off_t i = 0; i < noff; i++) {
uint8_t data;
err = lfs_bd_read(lfs,
NULL, rcache, noff-i,
head, i, &data, 1);
if (err) {
return err;
}
err = lfs_bd_prog(lfs,
pcache, rcache, true,
nblock, i, &data, 1);
if (err) {
if (err == LFS_ERR_CORRUPT) {
goto relocate;
}
return err;
}
}
*block = nblock;
*off = noff;
return 0;
}
// 如果noff和block_size相同,表示要写的位置超出了本块,
// 此时之前分配的nblock作为扩展的新块,需要填充ctz信息
// append block
index += 1;
// ctz指针数量
lfs_size_t skips = lfs_ctz(index) + 1;
lfs_block_t nhead = head;
for (lfs_off_t i = 0; i < skips; i++) {
nhead = lfs_tole32(nhead);
err = lfs_bd_prog(lfs, pcache, rcache, true,
nblock, 4*i, &nhead, 4);
nhead = lfs_fromle32(nhead);
if (err) {
if (err == LFS_ERR_CORRUPT) {
goto relocate;
}
return err;
}
if (i != skips-1) {
err = lfs_bd_read(lfs,
NULL, rcache, sizeof(nhead),
nhead, 4*i, &nhead, sizeof(nhead));
nhead = lfs_fromle32(nhead);
if (err) {
return err;
}
}
}
*block = nblock;
*off = 4*skips;
return 0;
}
relocate:
LFS_DEBUG("Bad block at 0x%"PRIx32, nblock);
// just clear cache and try a new block
lfs_cache_drop(lfs, pcache);
}
}
static lfs_ssize_t lfs_file_flushedwrite(lfs_t *lfs, lfs_file_t *file,
const void *buffer, lfs_size_t size) {
const uint8_t *data = buffer;
lfs_size_t nsize = size;
// 内联文件且写入后文件大小大于内联文件大小上限或cache大小,要转成外联文件
if ((file->flags & LFS_F_INLINE) &&
lfs_max(file->pos+nsize, file->ctz.size) >
lfs_min(0x3fe, lfs_min(
lfs->cfg->cache_size,
(lfs->cfg->metadata_max ?
lfs->cfg->metadata_max : lfs->cfg->block_size) / 8))) {
// inline file doesn't fit anymore
// 转为外联文件,会新建一个文件并复制原来的内容
int err = lfs_file_outline(lfs, file);
if (err) {
file->flags |= LFS_F_ERRED;
return err;
}
}
while (nsize > 0) {
// 下面就和文件读取的逻辑差不多,写到块末尾就扩展块(和读取到末尾就读下一个块类似)
// check if we need a new block
if (!(file->flags & LFS_F_WRITING) ||
file->off == lfs->cfg->block_size) {
// 判断LFS_F_WRITING表示自上次flush以来已经写入过,
// 只有第一次写才会进入该分支,后续写入都可以跳过,
// 也就是可以追加写入而不使用写时复制(因为写时复制在第一次写开启了,
// 后续对本块的写入都是写在写时复制创建的新的块中,不会有不一致的问题)
if (!(file->flags & LFS_F_INLINE)) {
if (!(file->flags & LFS_F_WRITING) && file->pos > 0) {
// find out which block we're extending from
/**
* 找到pos所在的块序号和偏移,也就是要修改的位置,
* 这里pos减了1,也就是找pos的上一个字节的位置,
* 也就是原来有数据的位置,如果是追加写入的话pos位置
* 在ctz链表中是不存在的,所以要用这个方法。
*/
int err = lfs_ctz_find(lfs, NULL, &file->cache,
file->ctz.head, file->ctz.size,
file->pos-1, &file->block, &file->off);
if (err) {
file->flags |= LFS_F_ERRED;
return err;
}
// mark cache as dirty since we may have read data into it
lfs_cache_zero(lfs, &file->cache);
}
// extend file with new blocks
lfs_alloc_ack(lfs);
/**
* 对于在中间位置修改时,只有第一次会创建写时复制用的新块,后续写入不会执行此步,
* 同时head参数设为block以及出参也为block,保证了多次扩展块时新数据都在新链表上
* (该函数的多次调用发生在写入数据横跨多个块的情况)
*/
int err = lfs_ctz_extend(lfs, &file->cache, &lfs->rcache,
file->block, file->pos,
&file->block, &file->off);
if (err) {
file->flags |= LFS_F_ERRED;
return err;
}
} else {
file->block = LFS_BLOCK_INLINE;
file->off = file->pos;
}
file->flags |= LFS_F_WRITING;
}
// program as much as we can in current block
lfs_size_t diff = lfs_min(nsize, lfs->cfg->block_size - file->off);
while (true) {
// lfs_bd_prog内带有回读,如果回读出错表示有坏块,需要移动整个文件到新位置
// 追加写入可直接编程,无需先擦除
int err = lfs_bd_prog(lfs, &file->cache, &lfs->rcache, true,
file->block, file->off, data, diff);
if (err) {
if (err == LFS_ERR_CORRUPT) {
goto relocate;
}
file->flags |= LFS_F_ERRED;
return err;
}
break;
relocate:
err = lfs_file_relocate(lfs, file);
if (err) {
file->flags |= LFS_F_ERRED;
return err;
}
}
file->pos += diff;
file->off += diff;
data += diff;
nsize -= diff;
lfs_alloc_ack(lfs);
}
return size;
}
static lfs_ssize_t lfs_file_rawwrite(lfs_t *lfs, lfs_file_t *file,
const void *buffer, lfs_size_t size) {
LFS_ASSERT((file->flags & LFS_O_WRONLY) == LFS_O_WRONLY);
// 清空读缓存
if (file->flags & LFS_F_READING) {
// drop any reads
int err = lfs_file_flush(lfs, file);
if (err) {
return err;
}
}
// append模式表示在文件尾部追加,pos指针直接指向文件尾部
if ((file->flags & LFS_O_APPEND) && file->pos < file->ctz.size) {
file->pos = file->ctz.size;
}
if (file->pos + size > lfs->file_max) {
// Larger than file limit?
return LFS_ERR_FBIG;
}
// 写入位置大于总大小,中间位置填0,相当于lfs_file_rawtruncate的扩展功能;
// 小于或等于size时
if (!(file->flags & LFS_F_WRITING) && file->pos > file->ctz.size) {
// fill with zeros
lfs_off_t pos = file->pos;
file->pos = file->ctz.size;
while (file->pos < pos) {
lfs_ssize_t res = lfs_file_flushedwrite(lfs, file, &(uint8_t){0}, 1);
if (res < 0) {
return res;
}
}
}
lfs_ssize_t nsize = lfs_file_flushedwrite(lfs, file, buffer, size);
if (nsize < 0) {
return nsize;
}
file->flags &= ~LFS_F_ERRED;
return nsize;
}
调整文件大小
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
static int lfs_file_rawtruncate(lfs_t *lfs, lfs_file_t *file, lfs_off_t size) {
LFS_ASSERT((file->flags & LFS_O_WRONLY) == LFS_O_WRONLY);
if (size > LFS_FILE_MAX) {
return LFS_ERR_INVAL;
}
lfs_off_t pos = file->pos;
// 取pos和ctz.size中较大者为实际大小
lfs_off_t oldsize = lfs_file_rawsize(lfs, file);
// 如果是裁剪
if (size < oldsize) {
// need to flush since directly changing metadata
int err = lfs_file_flush(lfs, file);
if (err) {
return err;
}
// lookup new head in ctz skip list
err = lfs_ctz_find(lfs, NULL, &file->cache,
file->ctz.head, file->ctz.size,
size, &file->block, &file->off);
if (err) {
return err;
}
// need to set pos/block/off consistently so seeking back to
// the old position does not get confused
file->pos = size;
// 调整head(链表尾)指向即可
file->ctz.head = file->block;
file->ctz.size = size;
file->flags |= LFS_F_DIRTY | LFS_F_READING;
// 如果是扩展
} else if (size > oldsize) {
// flush+seek if not already at end
// 让file->pos指向尾部
lfs_soff_t res = lfs_file_rawseek(lfs, file, 0, LFS_SEEK_END);
if (res < 0) {
return (int)res;
}
// fill with zeros
// TODO:一个一个字节写效率太低了吧(可能利用了缓冲来优化性能)
// TODO:为什么要全填0(这里应该是为了使用lfs_file_rawwrite的扩展块功能)
// TODO:感觉还是用append模式写入好点,提前扩展并填充没有带来更好的性能(
// 因为写时复制功能的存在,不管有没有提前分配写入的时候都需要分配新块,
// 应该就剩提前占用空间防止文件写入扩展时空间不够这一个功能了)
while (file->pos < size) {
res = lfs_file_rawwrite(lfs, file, &(uint8_t){0}, 1);
if (res < 0) {
return (int)res;
}
}
}
// restore pos
// pos恢复原来的位置
lfs_soff_t res = lfs_file_rawseek(lfs, file, pos, LFS_SEEK_SET);
if (res < 0) {
return (int)res;
}
return 0;
}
完整实例
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
#include "lfs.h"
// variables used by the filesystem
lfs_t lfs;
lfs_file_t file;
// configuration of the filesystem is provided by this struct
const struct lfs_config cfg = {
// block device operations
.read = user_provided_block_device_read,
.prog = user_provided_block_device_prog,
.erase = user_provided_block_device_erase,
.sync = user_provided_block_device_sync,
// block device configuration
.read_size = 16,
.prog_size = 16,
.block_size = 4096,
.block_count = 128,
.cache_size = 16,
.lookahead_size = 16,
.block_cycles = 500,
};
// entry point
int main(void) {
// mount the filesystem
int err = lfs_mount(&lfs, &cfg);
// reformat if we can't mount the filesystem
// this should only happen on the first boot
if (err) {
lfs_format(&lfs, &cfg);
lfs_mount(&lfs, &cfg);
}
// read current count
uint32_t boot_count = 0;
lfs_file_open(&lfs, &file, "boot_count", LFS_O_RDWR | LFS_O_CREAT);
lfs_file_read(&lfs, &file, &boot_count, sizeof(boot_count));
// update boot count
boot_count += 1;
lfs_file_rewind(&lfs, &file);
lfs_file_write(&lfs, &file, &boot_count, sizeof(boot_count));
// remember the storage is not updated until the file is closed successfully
lfs_file_close(&lfs, &file);
// release any resources we were using
lfs_unmount(&lfs);
// print the boot count
printf("boot_count: %d\n", boot_count);
}
TODO
- gstate 机制:元数据修改的一致性
- cache 机制:优化向存储介质写入和读取性能
- tag 详情:在 github wiki 上有详细描述,这里不再赘述