《Operating Systems: Three Easy Pieces》学习笔记(二十八) I/O 设备
系统架构
我们先看一个典型系统的架构(见图 36.1)。其中,CPU 通过某种内存总线(memory bus)或互连电缆连接到系统内存。图像或者其他高性能 I/O 设备通过常规的 I/O 总线(I/O bus)连接到系统,在许多现代系统中会是 PCI 或它的衍生形式。最后,更下面是外围总线(peripheral bus),比如 SCSI、SATA 或者 USB。它们将最慢的设备连接到系统,包括磁盘、鼠标及其他类似设备。
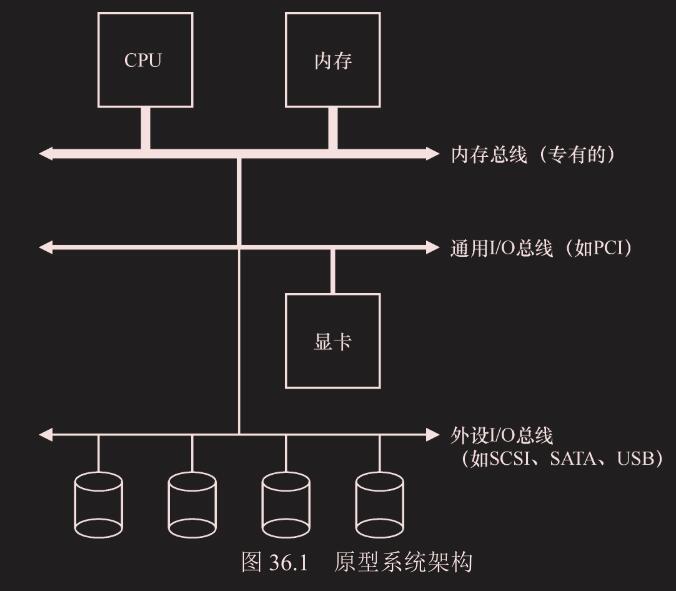
为什么要用这样的分层架构?简单回答:因为物理布局及造价成本。越快的总线越短,因此高性能的内存总线没有足够的空间连接太多设备。另外,在工程上高性能总线的造价非常高。所以,系统的设计采用了这种分层的方式,这样可以让要求高性能的设备(比如显卡)离 CPU 更近一些,低性能的设备离 CPU 远一些。将磁盘和其他低速设备连到外围总线的好处很多,其中较为突出的好处就是你可以在外围总线上连接大量的设备。
标准设备

第一部分是向系统其他部分展现的硬件接口(interface)。就是操作外设硬件的各种寄存器实现和外设硬件的交互
第二部分是它的内部结构(internal structure)。这部分包含设备相关的特定实现,负责具体实现设备展示给系统的抽象接口。非常简单的设备通常用一个或几个芯片来实现它们的功能。更复杂的设备会包含简单的 CPU、一些通用内存、设备相关的特定芯片,来完成它们的工作。
标准协议
在图 36.2 中,一个(简化的)设备接口包含 3 个寄存器:
- 一个
状态(status)寄存器, 可以读取并查看设备的当前状态; - 一个
命令(command)寄存器,用于通知设备执行某个具体任务 - 一个
数据(data)寄存器,将数据传给设备或从设备接收数据。
操作系统与该设备的典型交互:
1
2
3
4
5
6
7
8
9
10
While (STATUS == BUSY)
; // wait until device is not busy
// 数据写入DATA寄存器,如一个4KB的磁盘块
Write data to DATA register
// 命令写入命令寄存器,如写入磁盘命令
Write command to COMMAND register
(Doing so starts the device and executes the command)
// 轮询是否完成,会阻塞占用系统CPU
While (STATUS == BUSY)
; // wait until device is done with your request
利用中断减少 CPU 开销

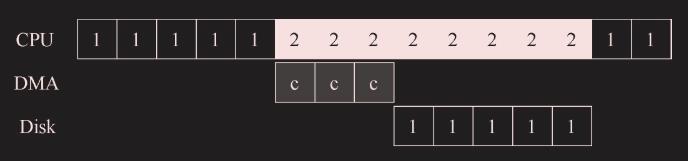
进程 1 在 CPU 上运行一段时间(对应 CPU 那一行上重复的 1),然后发出一个读取数据的 I/O 请求给磁盘。如果没有中断,那么操作系统就会简单自旋,不断轮询设备状态,直到设备完成 I/O 操作(对应其中的 p)。当设备完成请求的操作后,进程 1 又可以继续运行。

在磁盘处理进程 1 的请求时,操作系统在 CPU 上运行进程 2。磁盘处理完成后,触发一个中断,然后操作系统唤醒进程 1 继续运行。这样,在这段时间,无论 CPU 还是磁盘都可以有效地利用。
使用中断并非总是最佳方案:
- 假如有一个非常
高性能的设备,它处理请求很快: 通常在 CPU第一次轮询时就可以返回结果。此时如果使用中断,反而会使系统变慢:进程切换和处理中断的代价。可以考虑使用混合(hybrid)策略,先尝试轮询一小段时间,如果设备没有完成操作,此时再使用中断。 - 另一个最好不要使用中断的场景是
网络。网络端收到大量数据包,如果每一个包都发生一次中断,那么有可能导致操作系统发生活锁(livelock),即不断处理中断而无法处理用户层的请求(高负载场景),此时轮询更好 - 另一个基于中断的优化就是
合并(coalescing)。设备在抛出中断之前往往会等待一小段时间,在此期间,其他请求可能很快完成,因此多次中断可以合并为一次中断抛出,从而降低处理中断的代价
利用 DMA 进行更高效的数据传送

c就是写寄存器过程,将数据从内存拷贝到硬件的寄存器。这段时间也占用 CPU,浪费了。
解决方案就是使用DMA(Direct Memory Access)。DMA 引擎是系统中的一个特殊设备, 它可以协调完成内存和设备间的数据传递,不需要 CPU 介入。
DMA 工作过程如下。为了能够将数据传送给设备,操作系统会通过编程告诉 DMA 引擎数据在内存的位置,要拷贝的大小以及要拷贝到哪个设备。在此之后,操作系统就可以处理其他请求了。当 DMA 的任务完成后,DMA 控制器会抛出一个中断来告诉操作系统自己已经完成数据传输。修改后的时间线如下:
设备交互的方法
- 特权指令(privileged)
- 当需要发送数据给设备时,调用者指定一个存入数据的特定寄存器及一个代表设备的特定端口。执行这个指令就可以实现期望的行为。操作系统是唯一可以直接与设备交互的实体
- 内存映射 I/O(memory- mapped I/O)
- 硬件将设备寄存器作为
内存地址提供。当需要访问设备寄存器时,操作系统装载(读取)或者存入(写入)到该内存地址;然后硬件会将装载/存入转移到设备上,而不是物理内存。
纳入操作系统:设备驱动程序
例如文件系统,我们希望开发一个文件系统可以工作在 SCSI 硬盘、IDE 硬盘、USB 钥匙串设备等设备之上,并且希望这个文件系统不那么清楚对这些不同设备发出读写请求的全部细节。
关键问题:如何实现一个
设备无关的操作系统如何保持操作系统的大部分与设备无关,从而对操作系统的主要子系统
隐藏设备交互的细节?
在最底层,操作系统的一部分软件清楚地知道设备如何工作,我们将这部分软件称为设备驱动程序(device driver),所有设备交互的细节都封装在其中。
这种封装也有不足的地方。例如,如果有一个设备可以提供很多特殊的功能, 但为了兼容大多数操作系统它不得不提供一个通用的接口,这样就使得自身的特殊功能无法使用。
案例研究:简单的 IDE 磁盘驱动程序
IDE 硬盘暴露给操作系统的接口比较简单,包含 4 种类型的寄存器,即控制、命令块、状态和错误。在 x86 上,利用 I/O 指令 in 和 out 向特定的 I/O 地址(如下面的 0x3F6)读取或写入时,可以访问这些寄存器,如下所示:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
Control Register:
Address 0x3F6 = 0x80 (0000 1RE0): R=reset, E=0 means "enable interrupt"
Command Block Registers:
Address 0x1F0 = Data Port
Address 0x1F1 = Error
Address 0x1F2 = Sector Count
Address 0x1F3 = LBA low byte
Address 0x1F4 = LBA mid byte
Address 0x1F5 = LBA hi byte
Address 0x1F6 = 1B1D TOP4LBA: B=LBA, D=drive
Address 0x1F7 = Command/status
Status Register (Address 0x1F7):
7 6 5 4 3 2 1 0
BUSY READY FAULT SEEK DRQ CORR IDDEX ERROR
Error Register (Address 0x1F1): (check when Status ERROR==1)
7 6 5 4 3 2 1 0
BBK UNC MC IDNF MCR ABRT T0NF AMNF
BBK = Bad Block
UNC = Uncorrectable data error
MC = Media Changed
IDNF = ID mark Not Found
MCR = Media Change Requested
ABRT = Command aborted
T0NF = Track 0 Not Found
AMNF = Address Mark Not Found
下面是与设备交互的简单协议,假设它已经初始化了,如图 36.5 所示。
- 等待驱动就绪。读取
状态寄存器(0x1F7)直到驱动READY而非忙碌。 - 向命令寄存器写入参数。写入扇区数,待访问扇区对应的逻辑块地址(LBA),并将驱动编号(master=0x00,slave=0x10,因为 IDE 允许接入两个硬盘)写入命令寄存器(0x1F2-0x1F6)。
- 开启 I/O。发送
读写命令到命令寄存器。向命令寄存器(0x1F7)中写入 READ-WRITE 命令。 - 数据传送(针对写请求):等待直到驱动状态为 READY 和 DRQ(驱动请求数据),向数据端口写入数据。
- 中断处理。在最简单的情况下,每个扇区的数据传送结束后都会触发一次中断处理程序。较复杂的方式支持批处理,全部数据传送结束后才会触发一次中断处理。
- 错误处理。在每次操作之后读取状态寄存器。如果 ERROR 位被置位,可以读取错误寄存器来获取详细信息。
xv6 的 IDE 硬盘驱动程序(简化的):
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
// 在发起请求之前调用,确保驱动处于就绪状态。
static int ide_wait_ready() {
while (((int r = inb(0x1f7)) & IDE_BSY) || !(r & IDE_DRDY))
; // loop until drive isn't busy
}
// 将请求发送到磁盘(在写请求时,可能是发送数据)。
// 此时 x86 的 in 或 out 指令会被调用,
// 以读取或写入设备寄存器。
static void ide_start_request(struct buf *b) {
ide_wait_ready();
outb(0x3f6, 0); // generate interrupt
outb(0x1f2, 1); // how many sectors?
outb(0x1f3, b->sector & 0xff); // LBA goes here ...
outb(0x1f4, (b->sector >> 8) & 0xff); // ... and here
outb(0x1f5, (b->sector >> 16) & 0xff); // ... and here!
outb(0x1f6, 0xe0 | ((b->dev&1)<<4) | ((b->sector>>24)&0x0f));
if(b->flags & B_DIRTY){
outb(0x1f7, IDE_CMD_WRITE); // this is a WRITE
outsl(0x1f0, b->data, 512/4); // transfer data too!
} else {
outb(0x1f7, IDE_CMD_READ); // this is a READ (no data)
}
}
// 将一个请求加入队列(如果前面还有请求未处理完成),
// 或者直接将请求发送到磁盘(通过 ide_start_request())
void ide_rw(struct buf *b) {
acquire(&ide_lock);
// 找ide_queue链表第一个空元素,pp赋值为链表的头元素指针,相当于对链表的引用,
// *pp表示元素,(*pp)->qnext表示下一个元素,pp=&(*pp)->qnext表示指针移向下个元素,
// 循环条件是*pp,也就是元素不为空(不是元素指针pp不为空),由此实现遍历链表中的有效项
for (struct buf **pp = &ide_queue; *pp; pp=&(*pp)->qnext)
; // walk queue
// 元素赋值为b(深拷贝)
*pp = b; // add request to end
// 当pp是当前头元素时成立
if (ide_queue == b) // if q is empty
ide_start_request(b); // send req to disk
// 是否不可用或是脏状态
while ((b->flags & (B_VALID|B_DIRTY)) != B_VALID)
sleep(b, &ide_lock); // wait for completion
release(&ide_lock);
}
// 当发生中断时调用,从设备读取数据(如果是读请求), 并且在结束后唤醒等待的进程,
// 如果此时在队列中还有别的未处理的请求,则调用 ide_start_request() 接着处理下一个 I/O 请求。
void ide_intr() {
struct buf *b;
acquire(&ide_lock);
if (!(b->flags & B_DIRTY) && ide_wait_ready() >= 0)
insl(0x1f0, b->data, 512/4); // if READ: get data
b->flags |= B_VALID;
b->flags &= ˜B_DIRTY;
wakeup(b); // wake waiting process
if ((ide_queue = b->qnext) != 0) // start next request
ide_start_request(ide_queue); // (if one exists)
release(&ide_lock);
}
小结
中断和 DMA,用于提高设备效率。
访问设备寄存器的两种方式,I/O 指令和 内存映射 I/O。
设备驱动程序的概念,展示了操作系统本身如何封装底层细节,从而更容易以设备无关的方式构建操作系统的其余部分。