《Operating Systems: Three Easy Pieces》学习笔记(三十四) 崩溃一致性:FSCK和日志
文件系统面临的一个主要挑战在于,如何在出现断电(power loss)或系统崩溃(system crash)的情况下,更新持久数据结构。称为崩溃一致性问题(crash-consistency problem)。
一个详细的例子
假定磁盘上使用标准的简单文件系统结构,包括一个 inode 位图(inode bitmap,只有 8 位,每个 inode 一个),一个数据位图(data bitmap,也是 8 位,每个数据块一个),inode(总共 8 个,编号为 0 到 7,分布在 4 个块上),以及数据块(总共 8 个,编号为 0 ~ 7)。

查看图中的结构,可以看到分配了一个 inode(inode 号为 2),它在 inode 位图中标记, 单个分配的数据块(数据块 4)也在数据中标记位图。inode 表示为 I[v1],因为它是此 inode 的第一个版本。inode 结构如下(省略):
1
2
3
4
5
6
7
owner : remzi
permissions : read-write
size : 1
pointer : 4
pointer : null
pointer : null
pointer : null
上述 inode 结构只使用了一个直接指针,并指向数据库块 4,大小为 1
向文件追加内容时,要向它添加一个新数据块,因此必须更新 3 个磁盘上的结构:inode I[v1](必须指向新块,并且由于追加而具有更大的大小),新数据块 Db 和新版本的数据位图(称之为 B[v2])表示新数据块已被分配。因此,在系统的内存中,有 3 个块必须写入磁盘。更新的 inode(inode 版本 2,或简称为 I[v2])现在看起来像这样:
1
2
3
4
5
6
7
owner : remzi
permissions : read-write
size : 2
pointer : 4
pointer : 5
pointer : null
pointer : null

要实现这种转变,文件系统必须对磁盘执行 3 次单独写入,分别针对 inode(I[v2]),位图(B[v2])和数据块(Db)。请注意,当用户发出 write()系统调用时,这些写操作通常不会立即发生。脏的 inode、位图和新数据先在内存(页面缓存,page cache,或缓冲区缓存,buffer cache)中存在一段时间。然后,当文件系统最终决定将它们写入磁盘时(比如说 5s 或 30s),文件系统将向磁盘发出必要的写入请求。遗憾的是,可能会发生崩溃,从而干扰磁盘的这些更新。特别是,如果这些写入中的一个或两个完成后发生崩溃,而不是全部 3 个,则会导致不一致问题。
崩溃场景
假设上述三步写入的顺序随机
只将数据块(Db)写入磁盘。
在这种情况下,数据在磁盘上,但是没有指向它的inode,也没有表示块已分配的位图。因此,就好像写入从未发生过一样。从文件系统崩溃一致性的角度来看,这种情况根本不是问题。
只有更新的 inode(I[v2])写入了磁盘。
在这种情况下,inode 指向磁盘地址(5),其中 Db 即将写入,但 Db 尚未写入。因此,如果我们信任该指针,我们将从磁盘读取
垃圾数据(磁盘地址 5 的旧内容)。此外,遇到了一个新问题,我们将它称为文件系统不一致(file-system inconsistency)。磁盘上的位图告诉我们数据块 5 尚未分配,但是 inode 说它已经分配了。文件系统数据结构中的这种不同意见,是文件系统的数据结构不一致。要使用文件系统,我们必须以某种方式解决这个问题。inode(I[v2])和位图(B[v2])写入了磁盘,但没有写入数据(Db)。
在这种情况下,文件系统元数据是完全一致的:inode 有一个指向块 5 的指针,位图指示 5 正在使用,因此从文件系统的元数据的角度来看,一切看起来都很正常。但是有一个问题:5 中又是垃圾。
写入了 inode(I[v2])和数据块(Db),但没有写入位图(B[v2])。
在这种情况下,inode 指向了磁盘上的正确数据,但同样在 inode 和位图(B1)的旧版本之间存在不一致。因此,我们在使用文件系统之前,又需要解决问题。
只有更新后的位图(B[v2])写入了磁盘。
在这种情况下,位图指示已分配块 5,但没有指向它的 inode。因此文件系统再次不一致。如果不解决,这种写入将导致空间泄露(space leak),因为文件系统永远不会使用块 5。在这个向磁盘写入 3 次的尝试中,还有 3 种崩溃场景。在这些情况下,两次写入成功,最后一次失败。
写入了位图(B[v2])和数据块(Db),但没有写入 inode(I[v2])。
和上一种情况一样,存在空间泄露。在这种情况下,inode 和数据位图之间再次存在不一致。但是,即使写入块并且位图指示其使用,我们也不知道它属于哪个文件,因为没有 inode 指向该块。
崩溃一致性问题
理想的做法是将文件系统从一个一致状态(在文件被追加之前),原子地(atomically)移动到另一个状态(在 inode、位图和新数据块被写入磁盘之后)。遗憾的是,做到这一点不容易,因为磁盘一次只提交一次写入,而这些更新之间可能会发生崩溃或断电。我们将这个一般问题称为崩溃一致性问题(crash-consistency problem,也可以称为一致性更新问题,consistent-update problem)。
解决方案 1:文件系统检查程序
决定让不一致的事情发生,然后再修复它们(重启时)。
fsck 是一个 UNIX 工具,用于查找这些不一致并修复它们
以下是 fsck 的基本总结:
- 超级块:fsck 首先检查超级块是否合理,主要是进行健全性检查,例如确保文件系统大小大于分配的块数。通常,这些健全性检查的目的是找到一个可疑的(冲突的)超级块。在这种情况下,系统(或管理员)可以决定使用超级块的备用副本。
- 空闲块:接下来,fsck 扫描 inode、间接块、双重间接块等,以了解当前在文件系统中分配的块。它利用这些知识生成正确版本的分配位图。因此,如果位图和 inode 之间存在任何不一致,则通过信任 inode 内的信息来解决它。对所有 inode 执行相同类型的检查,确保所有看起来像在用的 inode,都在 inode 位图中有标记。
- inode 状态:检查每个 inode 是否存在损坏或其他问题。例如,fsck 确保每个分配的 inode 具有有效的类型字段(即常规文件、目录、符号链接等)。如果 inode 字段存在问题,不易修复,则 inode 被认为是可疑的,并被 fsck 清除,inode 位图相应地更新。
- inode 链接:fsck 还会验证每个已分配的 inode 的链接数。你可能还记得,链接计数表示包含此特定文件的引用(即链接)的不同目录的数量。为了验证链接计数,fsck 从根目录开始扫描整个目录树,并为文件系统中的每个文件和目录构建自己的链接计数。如果新计算的计数与 inode 中找到的计数不匹配,则必须采取纠正措施,通常是修复 inode 中的计数。如果发现已分配的 inode 但没有目录引用它,则会将其移动到 lost + found 目录。
- 重复:fsck 还检查重复指针,即两个不同的 inode 引用同一个块的情况。如果一个 inode 明显不好,可能会被清除。或者,可以复制指向的块,从而根据需要为每个 inode 提供其自己的副本。
- 坏块:在扫描所有指针列表时,还会检查坏块指针。如果指针显然指向超出其有效范围的某个指针,则该指针被认为是“坏的”,例如,它的地址指向大于分区大小的块。在这种情况下,fsck 不能做任何太聪明的事情。它只是从 inode 或间接块中删除(清除)该指针。
- 目录检查:fsck 不了解用户文件的内容。但是,目录包含由文件系统本身创建的特定格式的信息。因此,fsck 对每个目录的内容执行额外的完整性检查,确保“.”和“..”是前面的条目,目录条目中引用的每个 inode 都已分配,并确保整个层次结构中没有目录的引用超过一次。
解决方案 2:日志(或预写日志)
对于一致更新问题,最流行的解决方案可能是从数据库管理系统的世界中借鉴的一个想法(应该就是数据库中的事务)。这种名为预写日志(write-ahead logging)的想法,是为了解决这类问题而发明的。
我们通常将预写日志称为日志(journaling)。
基本思路如下。更新磁盘时,在覆写结构之前,首先写下一点小注记(在磁盘上的其他地方,在一个众所周知的位置),描述你将要做的事情。写下这个注记就是“预写”部分, 我们把它写入一个结构,并组织成“日志”。因此,就有了预写日志。
通过将注释写入磁盘,可以保证在更新(覆写)正在更新的结构期间发生崩溃时,能够返回并查看你所做的注记,然后重试。因此,你会在崩溃后准确知道要修复的内容(以及如何修复它),而不必扫描整个磁盘。
ext2 文件系统(没有日志):

ext3 文件系统:

日志写入:将事务(包括事务开始块,所有即将写入的数据和元数据更新以及事务 结束块)写入日志,等待这些写入完成。加检查点:将待处理的元数据和数据更新写入文件系统中的最终位置
写入日志期间发生崩溃
在写入日志期间发生崩溃时,事情变得有点棘手。在这里,我们试图将事务中的这些块(即 TxB、I[v2]、B[v2]、Db、TxE)写入磁盘。
一种简单的方法是一次发出 1 个块写入,等待每个完成,然后发出下一个。但是,这很慢。
我们希望一次发出所有 5 个块写入,因为这会将 5 个写入转换为单个顺序写入(连续写入),因此更快。然而,由于以下原因,这是不安全的:给定如此大的写入,磁盘内部可以执行调度并以任何顺序完成大批写入的小块(无法预知写入顺序)。
比如,事务开始结束块TxB/TxE都已经写入,但中间的TxB却没写入:

为避免该问题,文件系统分两步发出事务写入。首先,它将除 TxE 块之外的所有块写入日志,同时发出这些写入。当这些写入完成时,日志将看起来像这样(假设又是文件追加的工作负载):

当这些写入完成时,文件系统会发出 TxE 块的写入,从而使日志处于最终的安全状态:

此过程的一个重要方面是磁盘提供的原子性保证。事实证明,磁盘保证任何 512 字节写入都会发生或不发生(永远不会半写)。因此,为了确保 TxE 的写入是原子的,应该使它成为一个 512 字节的块。因此,我们当前更新文件系统的协议如下,3 个阶段中的每一个都标上了名称。
优化后的写入步骤
日志写入:将事务的内容(包括TxB、元数据和数据)写入日志,等待这些写入完成。日志提交:将事务提交块(包括TxE)写入日志,等待写完成,事务被认为已提交(committed)。加检查点:将更新内容(元数据和数据)写入其最终的磁盘位置。
恢复
利用日志内容从崩溃中恢复(recover)
如果崩溃发生在事务被安全地写入日志之前(在上面的步骤 2 完成之前),那么我们的工作很简单:简单地跳过待执行的更新。
如果在事务已提交到日志之后但在加检查点完成之前发生崩溃,则文件系统可以按如下方式恢复(recover)更新: 系统引导时,文件系统恢复过程将扫描日志,并查找已提交到磁盘的事务。然后,这些事务被重放(replayed,按顺序),文件系统再次尝试将事务中的块写入它们最终的磁盘位置。称为重做日志(redo logging)
批处理日志更新
基本协议可能会增加大量额外的磁盘流量。
例如,假设我们在同一目录中连续创建两个文件,称为 file1 和 file2。要创建一个文件,必须更新许多磁盘上的结构,至少包括:inode 位图(分配新的 inode),新创建的文件 inode,包含新文件目录条目的父目录的数据块,以及父目录的 inode(现在有一个新的修改时间)。通过日志,我们将所有这些信息逻辑地提交给我们的两个文件创建的日志。因为文件在同一个目录中,我们假设在同一个 inode 块中都有 inode,这意味着如果不小心,我们最终会反复写入这些相同的块。(多个事务要写入相同的块,就会重复)
为了解决这个问题,一些文件系统不会一次一个地向磁盘提交每个更新(例如,Linuxext3)。与此不同,可以将所有更新缓冲到全局事务中。在上面的示例中,当创建两个文件时,文件系统只将内存中的 inode 位图、文件的 inode、目录数据和目录 inode 标记为脏,并将它们添加到块列表中,形成当前的事务。当最后应该将这些块写入磁盘时(例如,在超时 5s 之后),会提交包含上述所有更新的单个全局事务。因此,通过缓冲更新,文件系统在许多情况下可以避免对磁盘的过多的写入流量。
使日志有限
日志的大小有限。如果不断向它添加事务(如下所示),它将很快填满。

第一个问题比较简单:日志越大,恢复时间越长,因为恢复过程必须重放日志中的所有事务(按顺序)才能恢复。
第二个问题更重要:当日志已满(或接近满)时,不能向磁盘提交进一步的事务,从而使文件系统“不太有用” (即无用)。
日志文件系统将日志视为循环数据结构,一遍又一遍地重复使用。 这就是为什么日志有时被称为循环日志(circular log)。一旦事务被加检查点,文件系统应释放它在日志中占用的空间,允许重用日志空间。
在日志超级块(journal superblock)中标记日志中最旧和最新的事务:

在日志超级块中(不要与主文件系统的超级块混淆),日志系统记录了足够的信息,以了解哪些事务尚未加检查点,从而减少了恢复时间,并允许以循环的方式重新使用日志。 因此,我们在基本协议中添加了另一个步骤:
日志写入:将事务的内容(包括 TxB 和更新内容)写入日志,等待这些写入完成。日志提交:将事务提交块(包括 TxE)写入日志,等待写完成,事务被认为已提交(committed)。加检查点:将更新内容写入其最终的磁盘位置。释放:一段时间后,通过更新日志超级块,在日志中标记该事务为空闲。
元数据日志
对于每次写入磁盘,我们现在也要先写入日志,从而使写入流量加倍。
在写入日志和写入主文件系统之间,存在代价高昂的寻道,这为某些工作负载增加了显著的开销。
我们上面描述的日志模式通常称为数据日志(data journaling,如在 Linux ext3 中),因为它记录了所有用户数据(除了文件系统的元数据之外)。一种更简单(也更常见)的日志形式有时称为有序日志(ordered journaling,或称为元数据日志,metadata journaling):

先前写入日志的数据块 Db 将改为直接写入文件系统,避免额外写入。
修改确实提出了一个有趣的问题:我们何时应该将数据块写入磁盘?
在将相关元数据写入磁盘之前,一些文件系统(例如,Linux ext3)先将数据块(常规文件)写入磁盘。(先写磁盘再写日志,防止元数据指向空数据)
数据写入:将数据写入最终位置,等待完成(等待是可选的,详见下文)。日志元数据写入:将开始块和元数据写入日志,等待写入完成。日志提交:将事务提交块(包括 TxE)写入日志,等待写完成,现在认为事务(包括数据)已提交(committed)。加检查点元数据:将元数据更新的内容写入文件系统中的最终位置。释放:稍后,在日志超级块中将事务标记为空闲。
棘手的情况:块复用
块被删除然后重新分配会有问题
假设你有一个名为 foo 的目录。用户向 foo 添加一个条目(一个条目,不是添加一个文件,类似一个文件名的字符串加上 inode 号),因此 foo 的内容(因为目录被认为是元数据,所以 D[foo]这个数据也写入日志区的元数据了)被写入日志。假设 foo 目录数据的位置是块 1000。因此日志包含如下内容
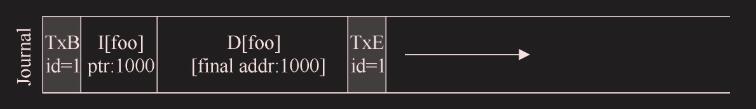
此时,用户删除目录中的所有内容以及目录本身,从而释放块 1000 以供复用。最后,用户创建了一个新文件(比如 foobar),结果复用了过去属于 foo 的相同块(1000)。foobar 的 inode 提交给磁盘,其数据也是如此。但是,请注意,因为正在使用元数据日志,所以只有 foobar 的 inode 被提交给日志,文件 foobar 中块 1000 中新写入的数据没有写入日志:

现在假设发生了崩溃,所有这些信息仍然在日志中。在重放期间,恢复过程简单地重放日志中的所有内容,包括在块 1000 中写入目录数据。因此,重放会用旧目录内容覆盖当前文件 foobar 的用户数据
这个问题有一些解决方案。例如,可以永远不再重复使用块,直到所述块的删除加上检查点,从日志中清除。Linux ext3 的做法是将新类型的记录添加到日志中,称为撤销(revoke) 记录。在上面的情况中,删除目录将导致撤销记录被写入日志。在重放日志时,系统首先扫描这样的重新记录。任何此类被撤销的数据都不会被重放,从而避免了上述问题。
总结日志:时间线
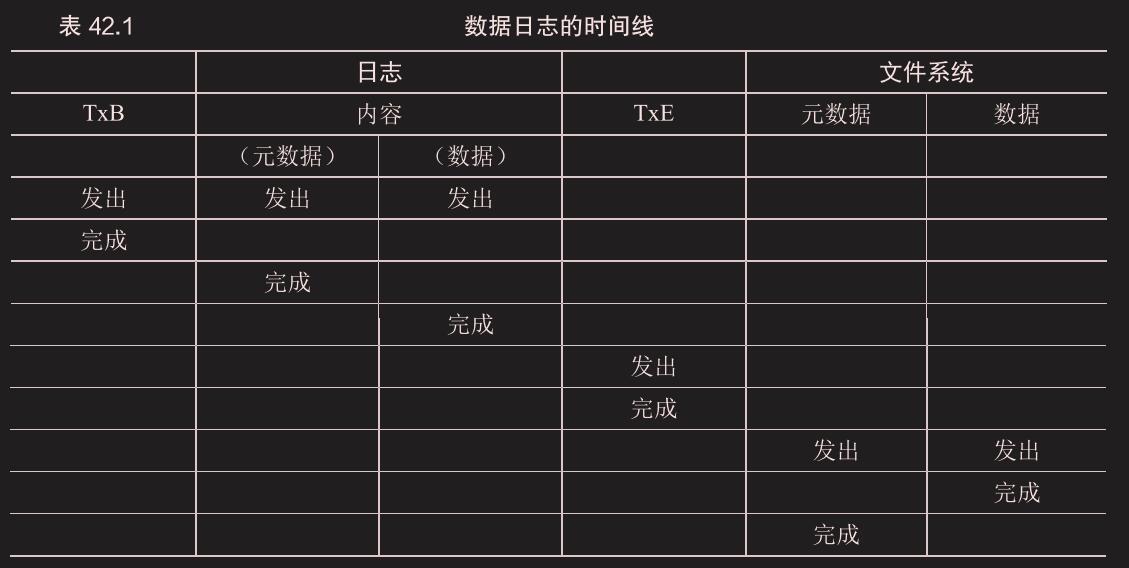
数据日志,就是先写日志区的元数据和数据,写完写 TxE 表示日志写完,再写入文件系统区的元数据和数据
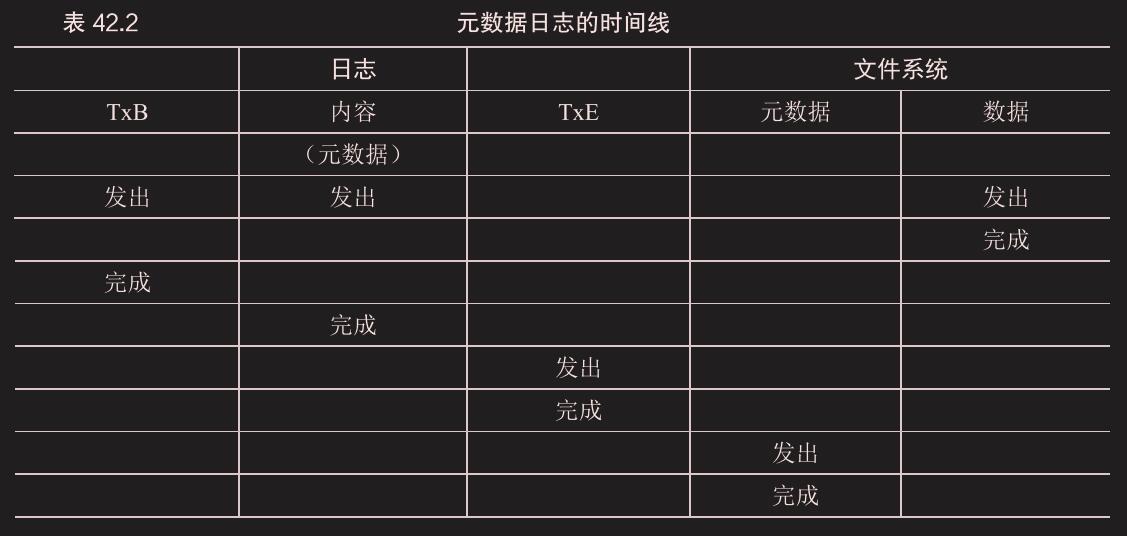
元数据日志就是同步写日志区的元数据和文件系统区的数据,都完成后写 TxE 表示日志写入结束,再写文件系统元数据,不用再写数据了
解决方案 3:其他方法
软更新
仔细地对文件系统的所有写入排序,以确保磁盘上的结构永远不会处于不一致的状态。例如,通过先写入指向的数据块,再写入指向它的 inode,可以确保 inode 永远不会指向垃圾。
写时复制(Copy-On-Write,COW)
这种技术永远不会覆写文件或目录。相反,它会对磁盘上以前未使用的位置进行新的更新。在完成许多更新后,COW 文件系统会翻转文件系统的根结构,以包含指向刚更新结构的指针。
这种技术名为基于反向指针的一致性(Backpointer-Based Consistency,BBC)
为了实现一致性,系统中的每个块都会添加一个额外的反向指针。例如,每个数据块都引用它所属的 inode。访问文件时,文件系统可以检查正向指针(inode 或直接块中的地址)是否指向引用它的块,从而确定文件是否一致。
两个指针双向校验
乐观崩溃一致性(optimistic crash consistency)
尽可能多地向磁盘发出写入,并利用事务校验和(transaction checksum)的一般形式,以及其他一些技术来检测不一致。
对于某些工作负载,这些乐观技术可以将性能提高一个数量级。
小结
我们介绍了崩溃一致性的问题,并讨论了处理这个问题的各种方法。