使用 LLaMA-Factory 微调 Qwen3 小参数模型
使用 LLaMA-Factory 微调 Qwen3 小参数模型
环境搭建
wsl + torch
详见 使用 WSL2 + WSLg 在 Windows 上跑带图形界面的 AI 应用
LLaMA-Factory
参考本文进行安装
1
2
3
git clone --depth 1 https://github.com/hiyouga/LLaMA-Factory.git
cd LLaMA-Factory
pip install -e ".[torch,metrics]" --no-build-isolation
下载 Qwen3 模型
这里使用最小的 0.6B 模型,虽然参数量少,但功能依然强大
可以选择 hugging face 或魔搭社区下载
1
huggingface-cli download Qwen/Qwen3-0.6B --local-dir ./model
或是:
1
modelscope download Qwen/Qwen3-0.6B --cache-dir ./model
注意下载的是 instruct 模型,而不是 base 模型(Qwen/Qwen3-0.6B-Base)。
准备数据集
可以下载预设的数据集,比如这个新闻分类数据集
对于自己的数据,可以参考该格式编写,也可以使用 easy-dataset 项目从文档中自动提取数据集,参考这个教程
easy-dataset
使用 easy-dataset 时,需要一个强大的 LLM 模型用来做问题提取,可以使用付费的 api,比如 OpenAI、Qwen 等。
当然也可以自行本地搭建,DeepSeek 最新发布的 DeepSeek-R1-0528-Qwen3-8B 模型已经非常强悍,完全可以胜任这个工作,可以使用 llama.cpp 运行量化的版本,在低显存的电脑上也能流畅运行:
- 下载 llama.cpp,选择合适的版本,非 NVIDIA 显卡可以选择 windows vulkan 版本
- 下载 GGUF 格式的量化版 DeepSeek-R1-0528-Qwen3-8B 模型,根据需要下载合适的量化版,我这边使用的是 4bit 的
DeepSeek-R1-0528-Qwen3-8B-UD-Q4_K_XL.gguf - 启动服务端:
.\llama-server -m model/DeepSeek-R1-0528-Qwen3-8B-UD-Q4_K_XL.gguf --host 0.0.0.0 -ngl 99,然后可以打开网页 http://127.0.0.1:8080 进行测试,同时该工具也会提供 openai 风格的 api(http://127.0.0.1:8080/v1/chat/completions)。
如果想去掉 DeepSeek-R1-0528-Qwen3-8B 模型的 <think> 标签:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
from flask import Flask, request, jsonify
import requests
import re
app = Flask(__name__)
# llama.cpp 的 API 地址
LLAMA_CPP_API_URL = 'http://localhost:8080/chat/completions' # 默认端口
# 正则用于去除 <think> 标签内容
def remove_think_blocks(text):
return re.sub(r"<think>(.*?)</think>", "", text, flags=re.DOTALL)
@app.route('/chat/completions', methods=['POST'])
def proxy_completion():
# 客户端发来的数据
payload = request.get_json()
# 转发到 llama.cpp 的 /completion 接口
response = requests.post(LLAMA_CPP_API_URL, json=payload)
llama_response = response.json()
print(llama_response)
# 过滤 <think> 标签内容
llama_response['choices'][0]['message']['content'] = remove_think_blocks(llama_response['choices'][0]['message']['content'])
print(llama_response)
return jsonify(llama_response)
if __name__ == '__main__':
app.run(host='0.0.0.0', port=5000)
启动微调
进入 wsl,进入 LLaMA-Factory 的目录
1 2 3
dev@DESKTOP-MVN3D3J:/mnt/h/repo/LLaMA-Factory$ ls CITATION.cff MANIFEST.in README.md assets config datasets evaluation models pyproject.toml saves setup.py start.sh LICENSE Makefile README_zh.md cache data docker examples offload requirements.txt scripts src tests
- (激活虚拟 python 环境),运行命令
llamafactory-cli webui,默认运行在 7860 端口 - 打开 http://127.0.0.1:7860,选择正确的模型类型 Qwen3-0.6B-Instruct,填写正确的本地已经下载的模型地址
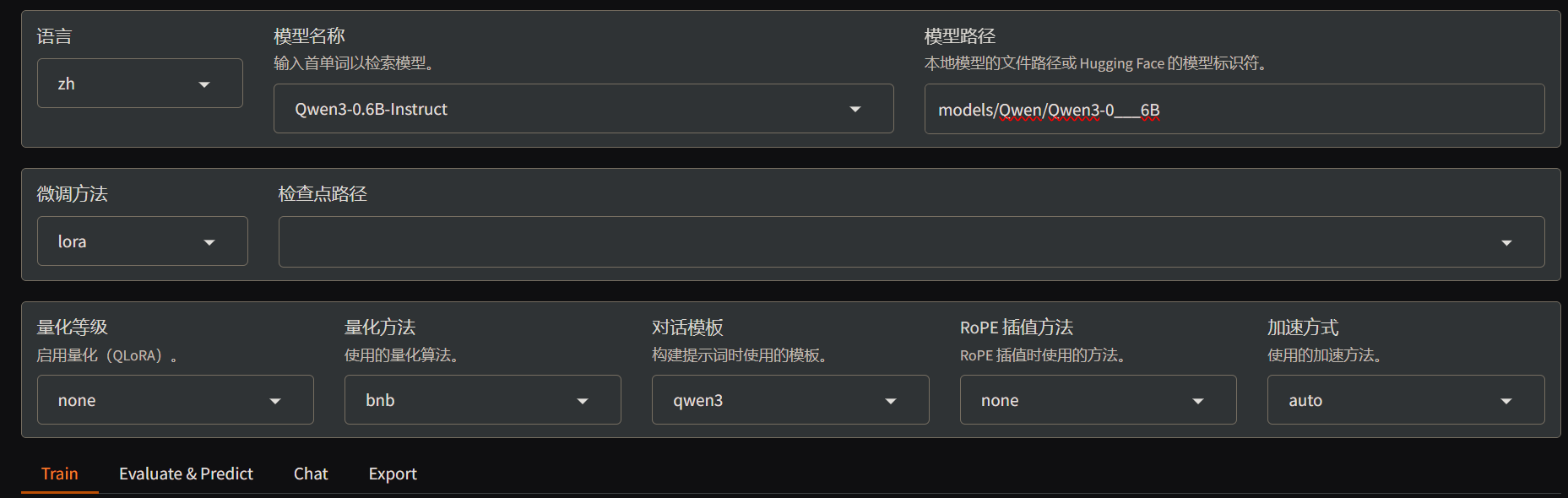
- 填写准备好的数据集的本地目录,选择数据集类型,这里选
train
- 配置训练参数,这里把学习率配置为
5e-6,梯度累积配置为2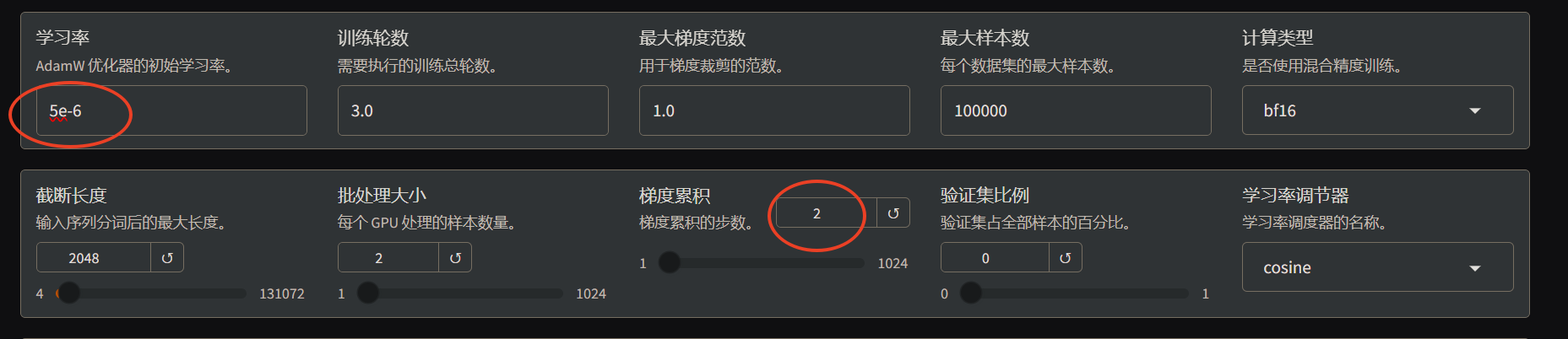
- 配置 LoRA 参数,这里开启了 LoRA+ ,同时作用模块配置为 all
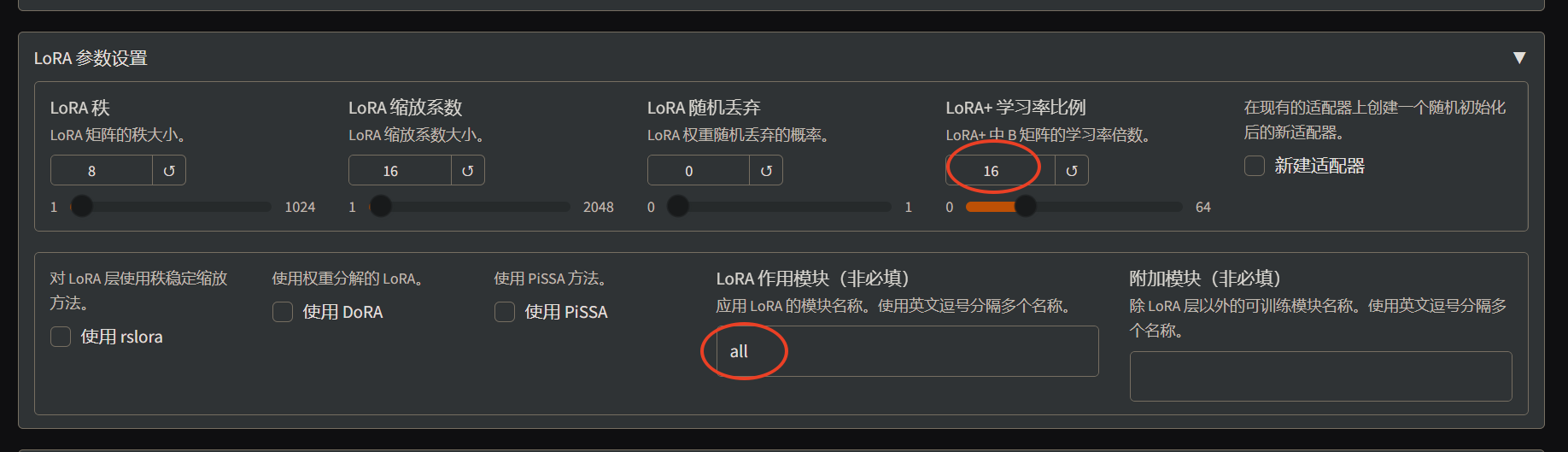
- 点击
开始按钮开始训练,同时会显示进度和损失曲线,等待训练完成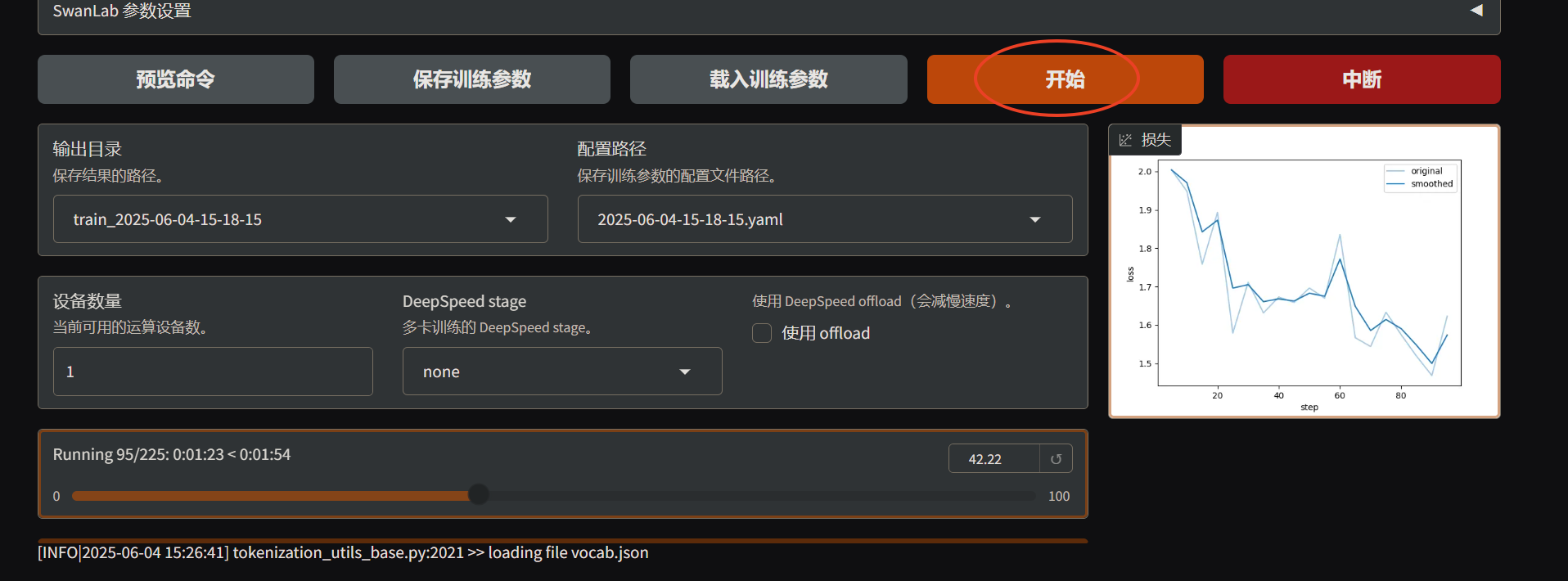
- 训练完成后可以进行测试,填写
检查点路径并切换到chat页面,再点击加载模型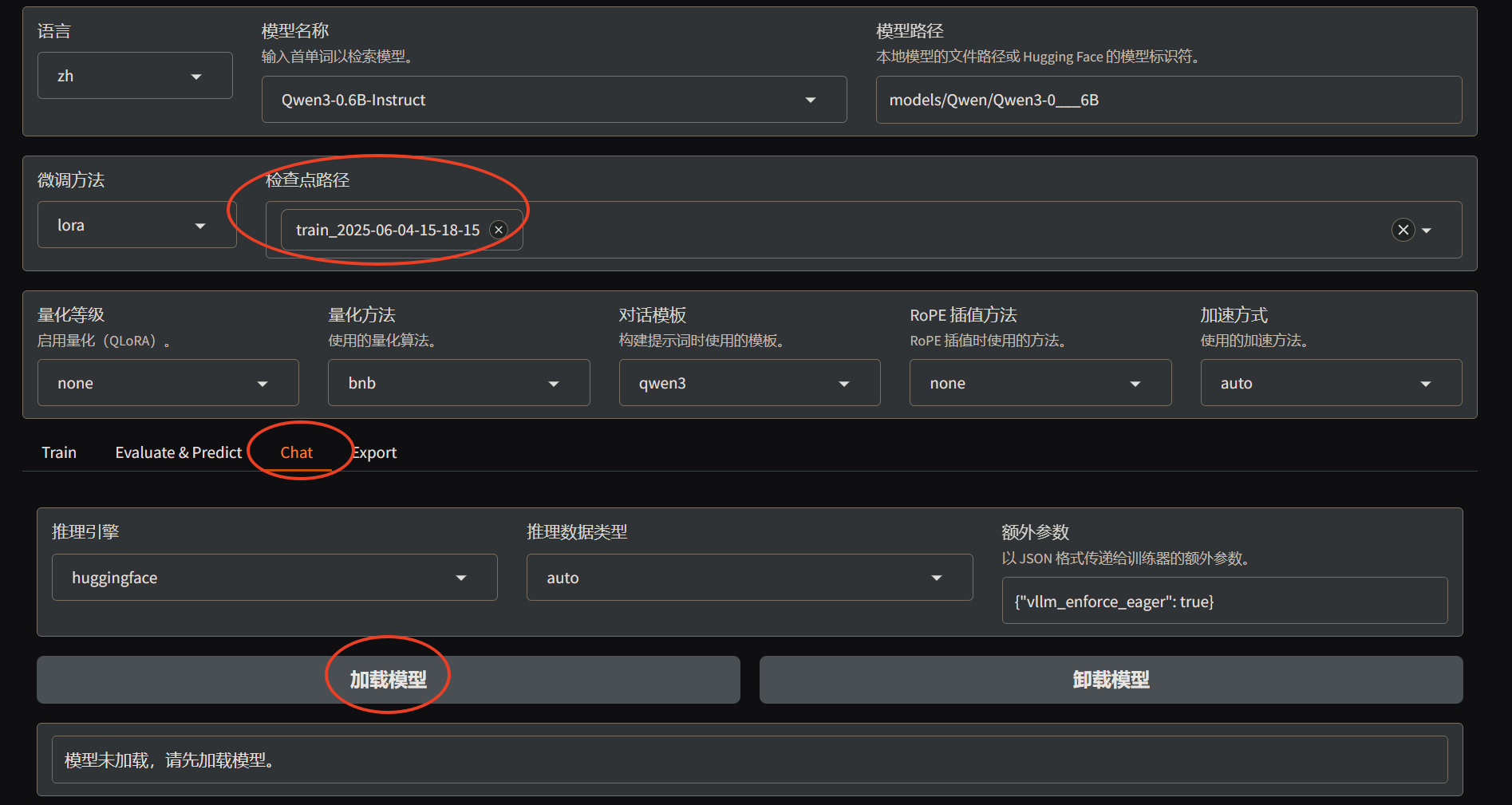
可以在验证集中找一个数据进行测试,因为验证集并没有参与训练,可以检验出训练的效果
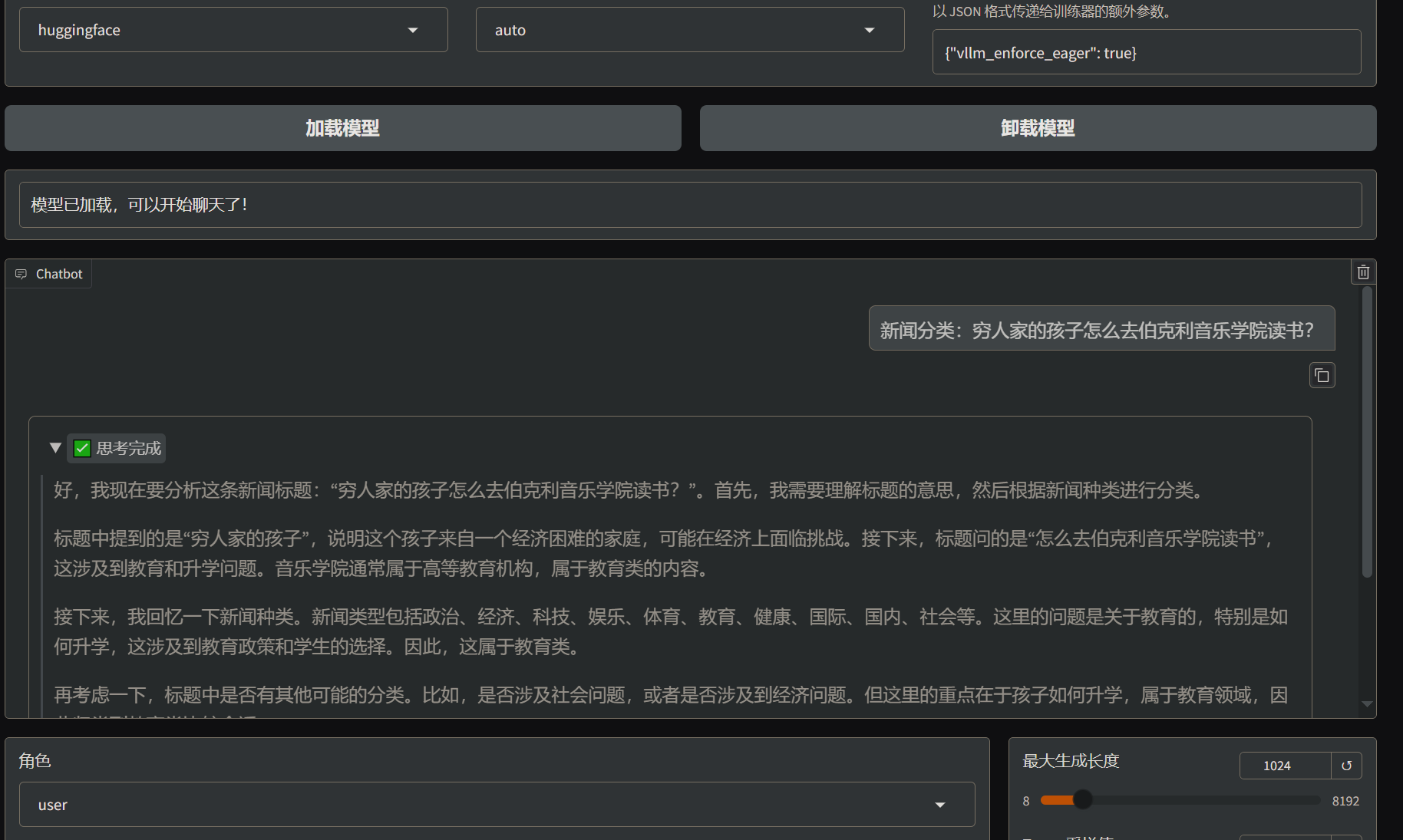
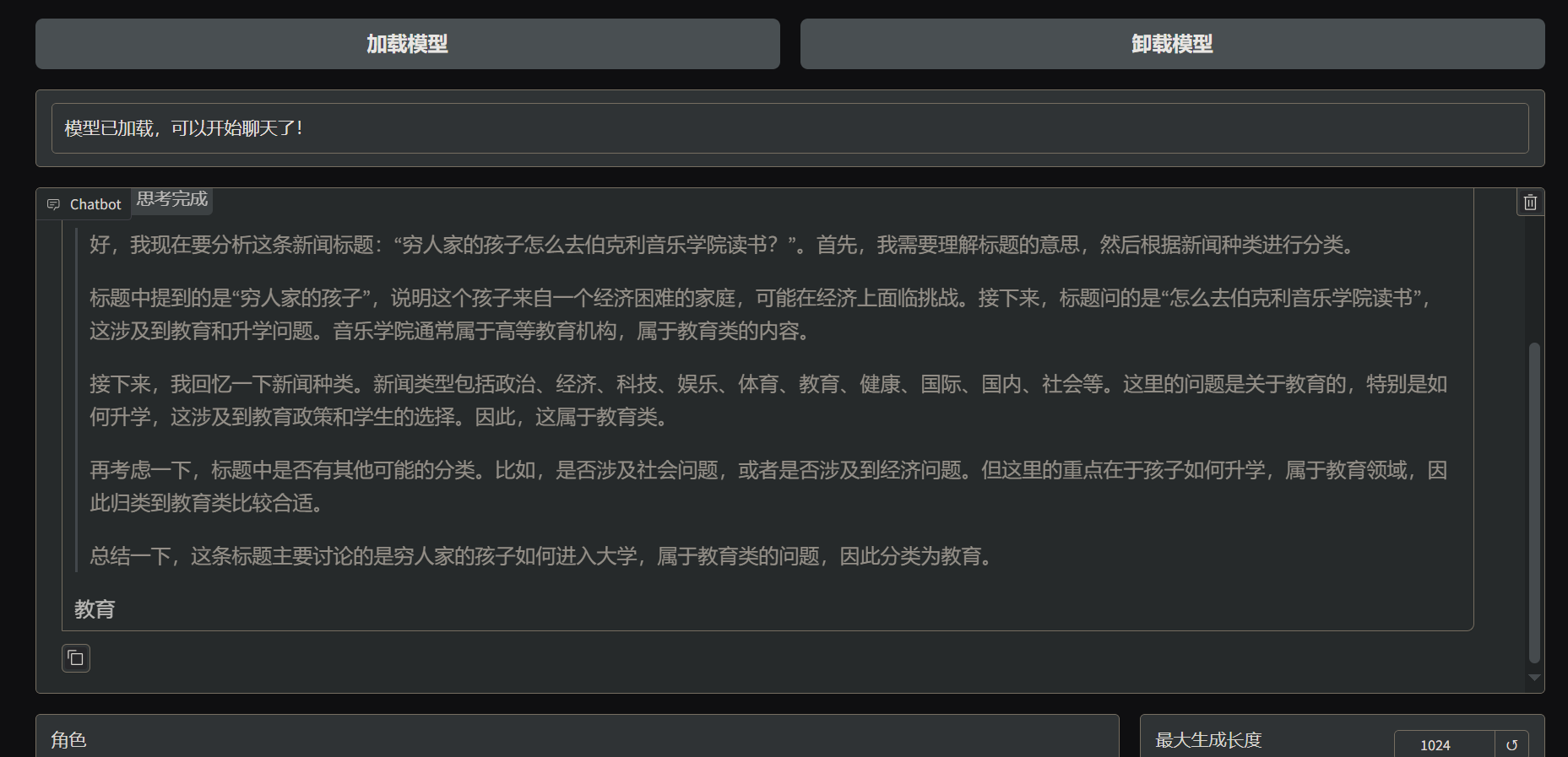
- 微调后的模型成功理解了
新闻分类指令并给出预期的结果,训练成功。
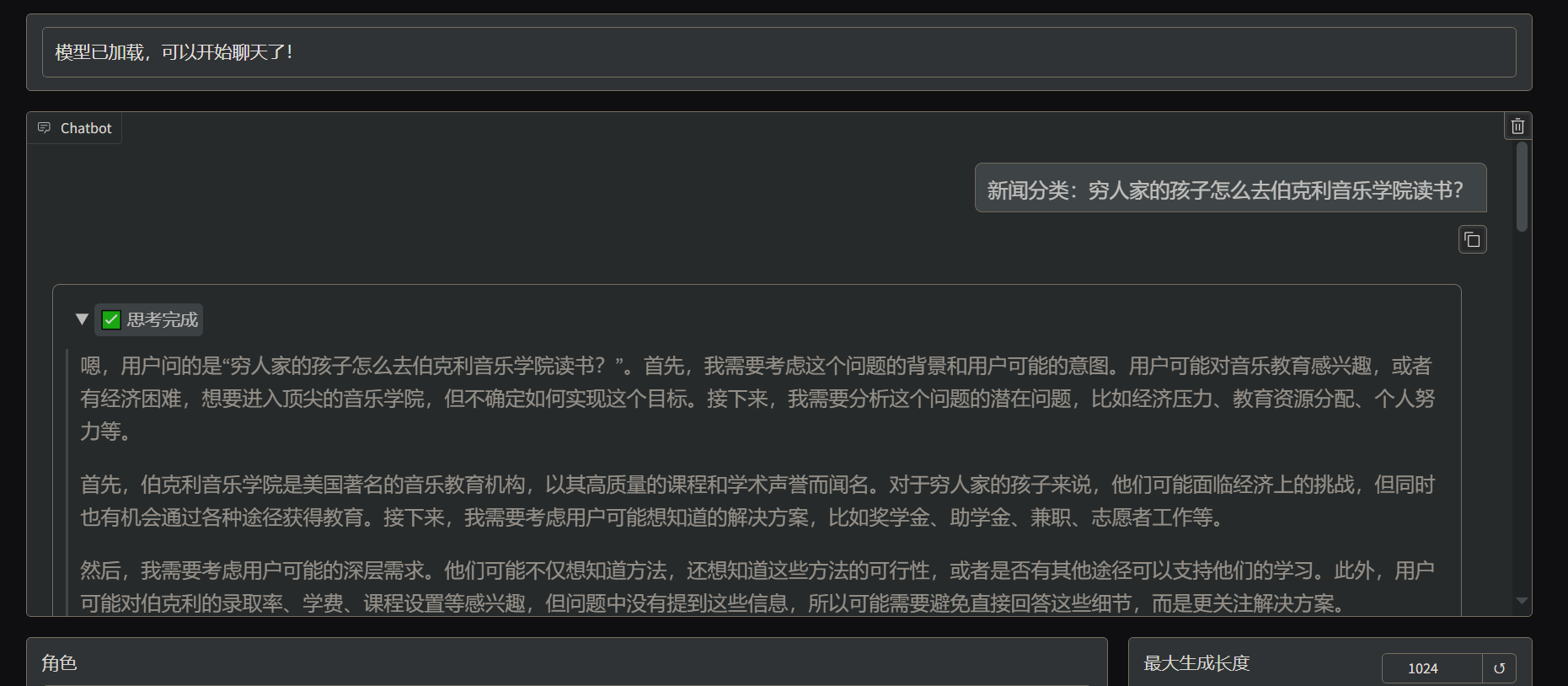
训练前的效果:
QLoRA
如果想在训练过程中节省 VRAM 的占用,可以启用 QLoRA 功能
使用 pip 安装 bitsandbytes,对于 AMD 用户需要使用 ROCm/bitsandbytes 进行手动编译:
1 2 3 4 5 6 7
git clone --recurse https://github.com/ROCm/bitsandbytes cd bitsandbytes git checkout rocm_enabled_multi_backend pip install -r requirements-dev.txt cmake -DCOMPUTE_BACKEND=hip -S . #Use -DBNB_ROCM_ARCH="gfx90a;gfx942" to target specific gpu arch make pip install .
启用 LLaMA-Factory 相关功能,一般将量化等级配置为 4 来减少 VRAM 占用
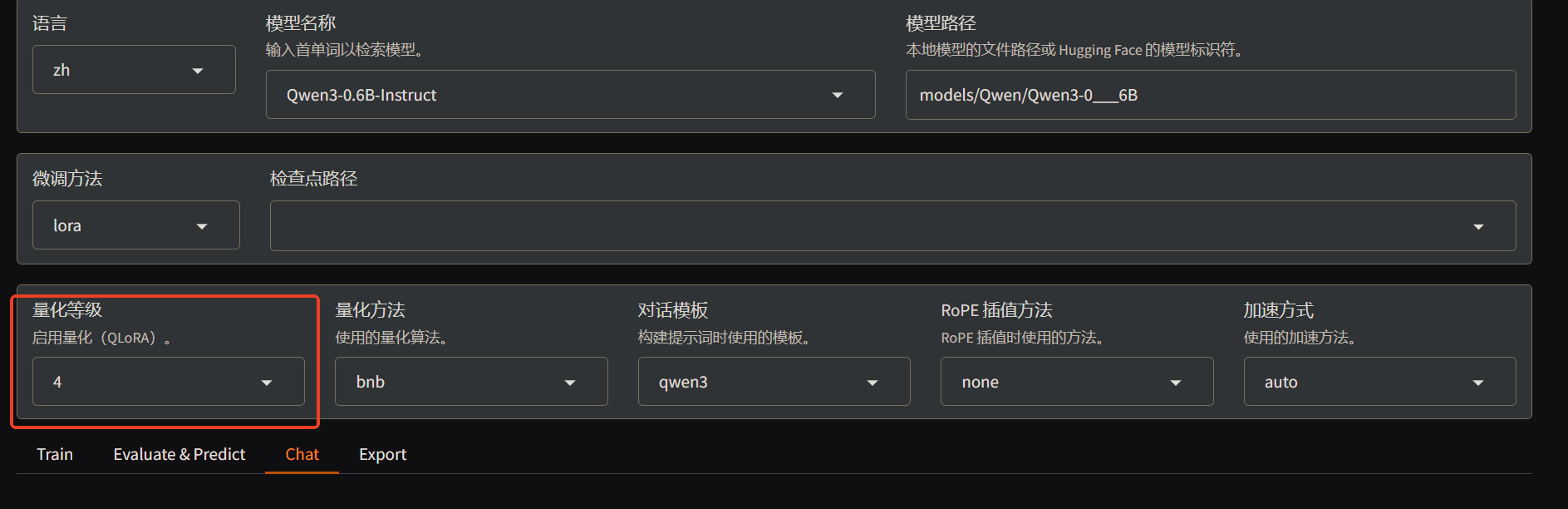
之后的训练过程和上面介绍的相同
参考
本文由作者按照 CC BY-SA 4.0 进行授权