triton 学习

triton 学习
🧾 问题场景
- 输入数组(即一维 Tensor) A:
A = [100, 99, 98, ..., 1](长度 N = 100) - 我们希望 把所有元素乘 2
- 我们设定:
BLOCK_SIZE = 32(每个线程处理 32 个元素)
🧠 核心代码
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
import torch
import triton
import triton.language as tl
@triton.jit
def multiply_kernel(A_ptr, N, BLOCK_SIZE: tl.constexpr):
# 获取当前程序实例(Program)的 ID,等价于线程编号
# 类似于 POSIX 中的:pthread_t tid = pthread_self();
pid = tl.program_id(0)
# 计算当前程序负责处理的数据索引范围
# tl.arange(0, BLOCK_SIZE) 返回一个向量 [0, 1, ..., BLOCK_SIZE-1]
# 每个 program 处理 BLOCK_SIZE 个元素,偏移量取决于 pid
# 例如:pid=1 → offsets = [32, 33, ..., 63]
offsets = pid * BLOCK_SIZE + tl.arange(0, BLOCK_SIZE)
# 创建掩码(mask),用于屏蔽越界访问
# 只处理 offsets 中小于 N 的合法索引(N 是数组总长度)
mask = offsets < N
# 从全局内存中加载对应索引位置的数据
# A_ptr 是数组 A 的指针,offsets 是该 program 负责的偏移
# 加上 mask 是为了避免访问越界位置
# a 变量所在的位置是program自己的私有sram
a = tl.load(A_ptr + offsets, mask=mask)
# 对数据进行逐元素乘以 2 的操作
a *= 2
# 将结果写回原始位置,仍使用 mask 避免越界写入
tl.store(A_ptr + offsets, a, mask=mask)
🧮 执行
- 计算所需 grid 数量
- 调用 triton 框架开始运行
1
2
3
4
5
6
7
8
9
10
11
12
13
14
# 🔢 准备输入数据:逆序 [100, 99, ..., 1]
x = torch.arange(100, 0, -1, dtype=torch.float32, device='cuda')
N = x.numel()
MY_BLOCK_SIZE = 32
# 🧮 计算启动多少个 program(每个处理 MY_BLOCK_SIZE 个元素)
# Triton 启动网格必须是元组格式 (1D, ),哪怕是一维也不能省略逗号
grid = (triton.cdiv(N, MY_BLOCK_SIZE),)
# 解释:grid = ((N + MY_BLOCK_SIZE - 1) // MY_BLOCK_SIZE,)
# 对于 N = 100,BLOCK_SIZE = 32,结果是 4,最后一个 program 只处理 4 个元素
# 🧠 可选写法:使用 lambda 动态计算(推荐用于自动调优)
# grid = lambda meta: (triton.cdiv(N, meta['BLOCK_SIZE']),)
1
2
3
4
5
6
# 🚀 启动 Triton kernel
multiply_kernel[grid](
x, # A_ptr:PyTorch Tensor 会自动转换为设备指针传入 GPU
N, # N:待处理元素数量
MY_BLOCK_SIZE
)
multiply_kernel[grid]() 这句话是 triton 自定义语法,实际就是重载了 python __getitem__ 方法
python 中的 obj[key] ⇨ 实际调用的是:obj.__getitem__(key),默认功能为下标访问
通过重载让[]的含义从下标访问变为创建一个带 grid 的 kernel 实例对象,这里的 grid 的类型可以是一个 Tuple[int],也可以是一个 lambda(这个 lambda 本质也是返回一个Tuple[int],结果是一样的)。当使用 lambda 类型时,triton 框架会将后面的方法的最后一个参数转换为 dict 格式传递给这个 lambda 的捕获参数(即示例中的meta),lambda 内部就能通过 meta['BLOCK_SIZE'] 访问到(这里用到了反射特性,将 BLOCK_SIZE 这个参数名反射成了 meta 的 key 值,变成了字符串)。
后面的 () 符号就是调用这个对象的 __call__ 方法,这个方法内部就会调用上面定义的用 @triton.jit 修饰的 multiply_kernel 方法,参数个数和定义和 multiply_kernel 方法相同
然后 Triton 会并发启动 4 个 program(线程实例):
pid = 0pid = 1pid = 2pid = 3
🔁 运行时过程
这 4 个 Program 可以理解为操作系统层面的 4 个并发线程,每个处理数组的一块元素。
🎯 Program 0(pid = 0)
offsets = 0 * 32 + [0..31] = [0, 1, ..., 31]mask = [True, True, ..., True](全部在范围内)a = A[0..31] = [100, 99, 98, ..., 69](数组开头的 32 个元素)a *= 2→[200, 198, 196, ..., 138]- 写回到
A[0..31]
🎯 Program 1(pid = 1)
offsets = 1 * 32 + [0..31] = [32, 33, ..., 63]mask = [True, ..., True](全部合法)a = A[32..63] = [68, 67, ..., 37]a *= 2- 写回
A[32..63]
🎯 Program 2(pid = 2)
offsets = 2 * 32 + [0..31] = [64, ..., 95]mask = [True, ..., True]a = A[64..95] = [36, 35, ..., 5]a *= 2- 写回
A[64..95]
🎯 Program 3(pid = 3)
offsets = 3 * 32 + [0..31] = [96, ..., 127]mask = [True, True, True, True, False, ..., False]只有前 4 个元素[96, 97, 98, 99]是合法的a = A[96..99] = [4, 3, 2, 1]a *= 2- 写回
A[96..99],其余跳过
🖼️ 最终结果
1
2
3
4
5
6
7
8
9
10
11
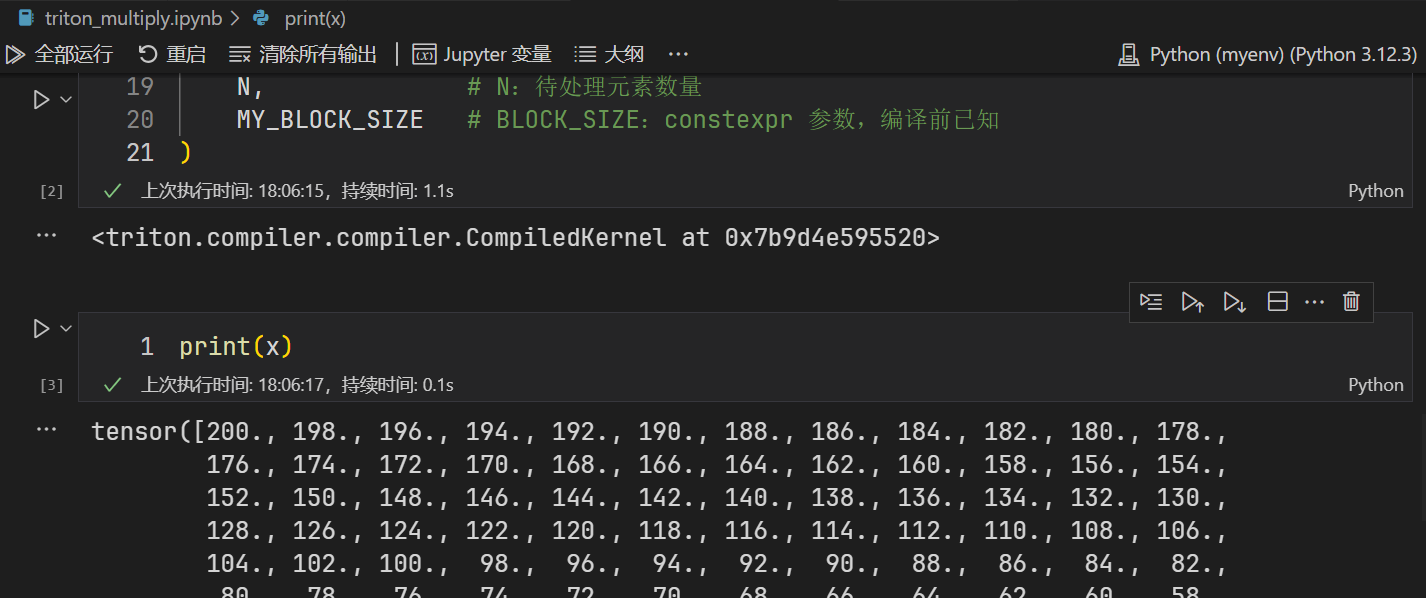
print(x)
tensor([200., 198., 196., 194., 192., 190., 188., 186., 184., 182., 180., 178.,
176., 174., 172., 170., 168., 166., 164., 162., 160., 158., 156., 154.,
152., 150., 148., 146., 144., 142., 140., 138., 136., 134., 132., 130.,
128., 126., 124., 122., 120., 118., 116., 114., 112., 110., 108., 106.,
104., 102., 100., 98., 96., 94., 92., 90., 88., 86., 84., 82.,
80., 78., 76., 74., 72., 70., 68., 66., 64., 62., 60., 58.,
56., 54., 52., 50., 48., 46., 44., 42., 40., 38., 36., 34.,
32., 30., 28., 26., 24., 22., 20., 18., 16., 14., 12., 10.,
8., 6., 4., 2.], device='cuda:0')
数组 A 被 并发分成 4 块处理,每块最多 32 个元素(最后一块不足补齐):
1
2
原始 A: [100, 99, 98, ..., 1]
处理后 A: [200, 198, 196, ..., 2]
🎯 图示结构
| program 1 | program 2 | program 3 | program 4 |
|---|---|---|---|
| pid = 0 | pid = 1 | pid = 2 | pid = 3 |
| A[0..31] | A[32..63] | A[64..95] | A[96..99] |
| 32 个元素 | 32 个元素 | 32 个元素 | 4 个元素 |
- 每个
pid是一个 独立并发的 program 实例 offsets是该程序负责的 数组元素索引mask保证 不会访问越界元素
✅ 总结
| Triton 行为 | C++/并发类比 |
|---|---|
| 并发程序数 | (N + BLOCK_SIZE - 1) / BLOCK_SIZE 个 |
| 每个程序处理 | BLOCK_SIZE 个元素 |
| offsets | 当前程序负责处理的索引区间 |
| mask | 越界保护(类似边界检查) |
| 整体执行 | 类似用线程池并发执行分片任务 |
环境搭建
- vscode 安装 jupyter 插件
- 配置 venv,安装 torch 和 triton。如果自己已经在别的目录创建了 venv,需要在那里安装
pip install jupyter,然后执行python -m ipykernel install --user --name=myenv --display-name "Python (myenv)"进行注册 - 新建文件
triton_multiply.ipynb,在编辑器的左上角右键->插入单元格,然后插入代码运行
本文由作者按照 CC BY-SA 4.0 进行授权