DeepSeek-OCR 笔记
简介
使用了 Encoder-Decoder transformer 架构:
- Encoder: DeepEncoder,核心部分,可以将带文字的图片转换成 vision token,对比将这些文字转为通常的 text token,其数量可以减少至 1/10 以下。
- Decoder: DeepSeek3B-MoE-A570M
光学压缩的可行性
假设有一篇 1000 字的文章,用 txt(utf-8 编码纯文本) 保存比 png(排版后渲染为图片) 更省空间吗?
我们一般认为用图片保存文章的所需空间比纯文本更多:
- 对单个文字来说,要让其在图片中显示,需要使用一种字体进行渲染。渲染后所得到信息,要比纯文本使用 utf-8 编码(中文只需3字节)表示文字要多
- 用图片显示文字需要将文字进行排版,比如分段落、分双列等,纯文本并不需要这些结构化的信息
根据信息论,这篇文章的信息量是确定的,那无论用什么方式保存,只要没有信息冗余,占用的计算机内存空间是一样的。只是图片信息的冗余导致了占用空间的增大。
那么我们能不能通过一种方式去减少这种冗余,让其占用空间更小,甚至小于纯文本?
DeepSeek-OCR 的工作就是对视觉-文本压缩边界的初步探索,研究解码 N 个文本 token 需要多少个视觉 token。
OCR 和 VLM
VLM 是用于理解图像的大模型,相比于 LLM,其输入变为了图片。其可处理的种类多种多样:比如风景照片、屏幕截图、电子版说明书、图画等
OCR 是 VLM 的一种应用,专用于理解文本内容较多的图片,比如电子版说明书。
OCR 并不仅仅只有把图片中的文字提取出来的能力,这里的 OCR 指的是理解文字类图片的能力,包括提取文字、分割文档结构、描述图片中几何图形的结构等。
架构
Encoder-Decoder
- Encoder(DeepEncoder): 将图片转为压缩后的 vision tokens,让其可以被 Decoder 识别
- Decoder(DeepSeek3B-MoE-A570M): 根据 Encoder 产生的 vision tokens 生成结果。
Encoder 需要具备如下特性:
- 能够处理高分辨率
- 高分辨率下较低的激活内存(反向传播占用内存小)
- vision tokens 少
- 支持多种分辨率输入
- 参数数量适中
DeepEncoder
过往的工作
dual-tower 架构
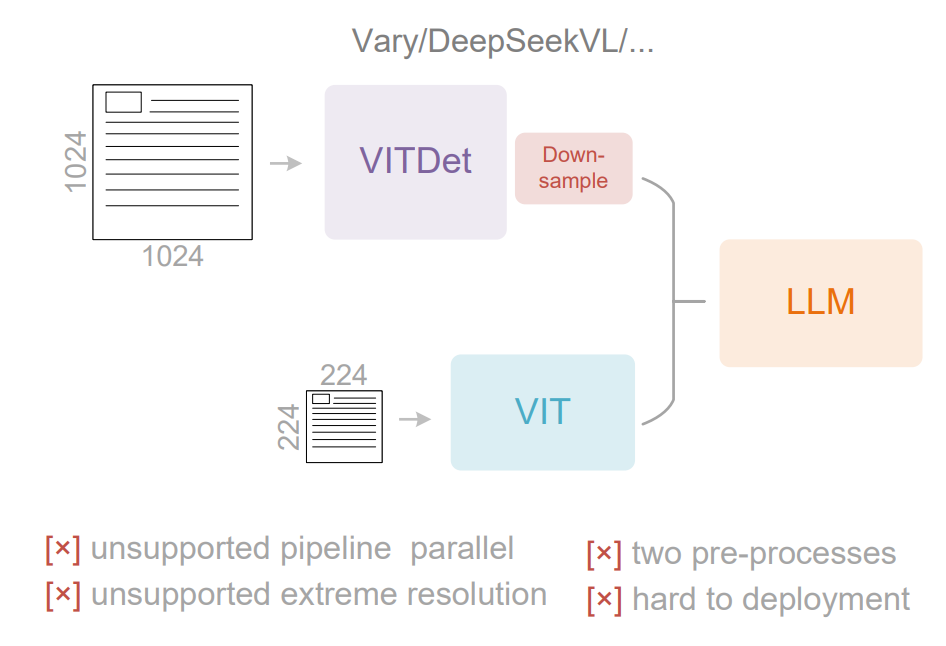
将图像分为高分辨率和低分辨率两份,训练时需要处理双图像并行,复杂度高,难部署
ViT(Vision Transformer): 图像就像一段文字,我们可以把它分成小块(patch),让 Transformer 来理解。
ViTDet 是一种用纯 Vision Transformer 构建的目标检测骨干(backbone)和特征提取网络。
SAM(Segment Anything Model): 基于 ViTDet 实现的图像分割模型
tile-based 架构
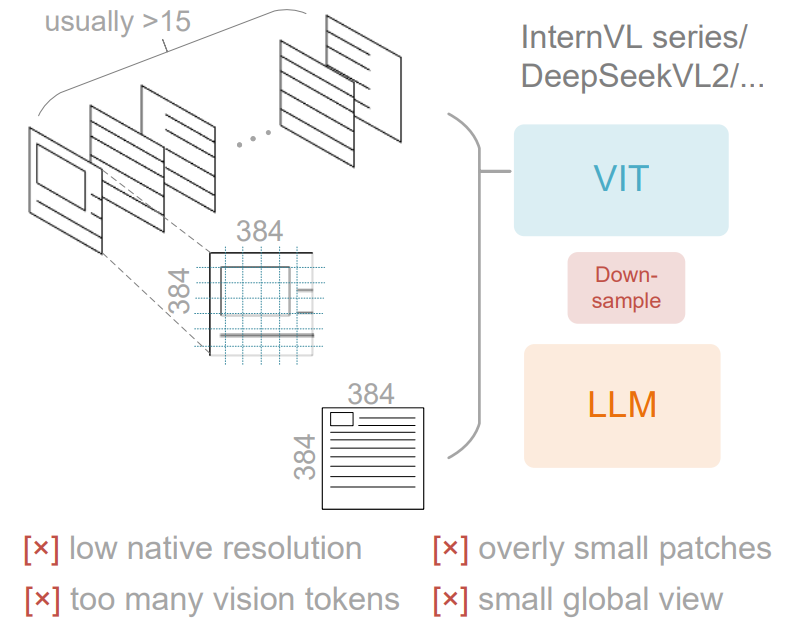
将图像分为高分辨率和低分辨率两份,高分辨率的拆分为小的 tile,在和低分辨率的混合起来处理
缺点是碎片化严重,需要的 vision token 较多
adaptive resolution encoding 架构
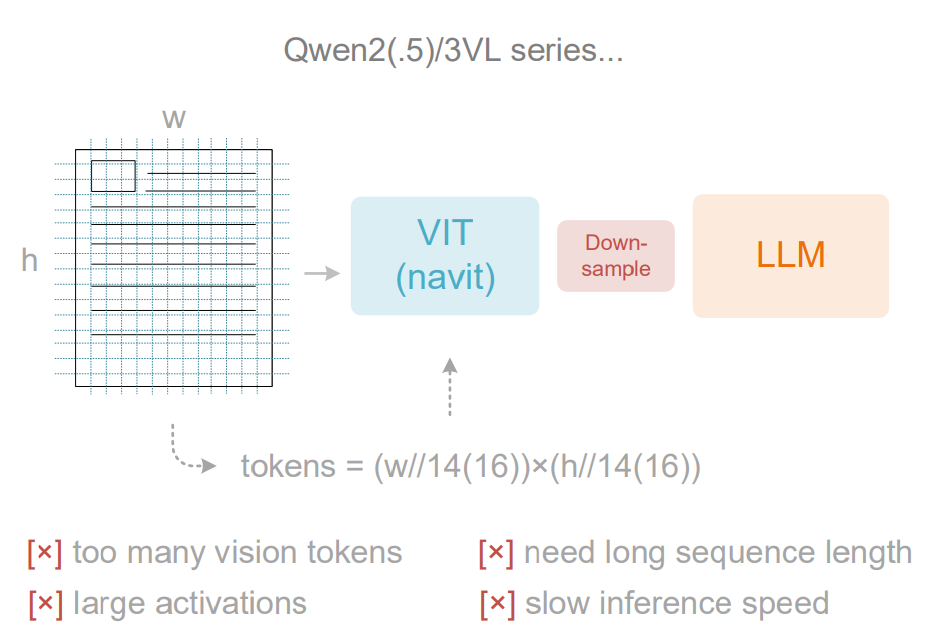
上下文太长,激活内存消耗大,训练和推理效率低
DeepSeek-OCR 的改进
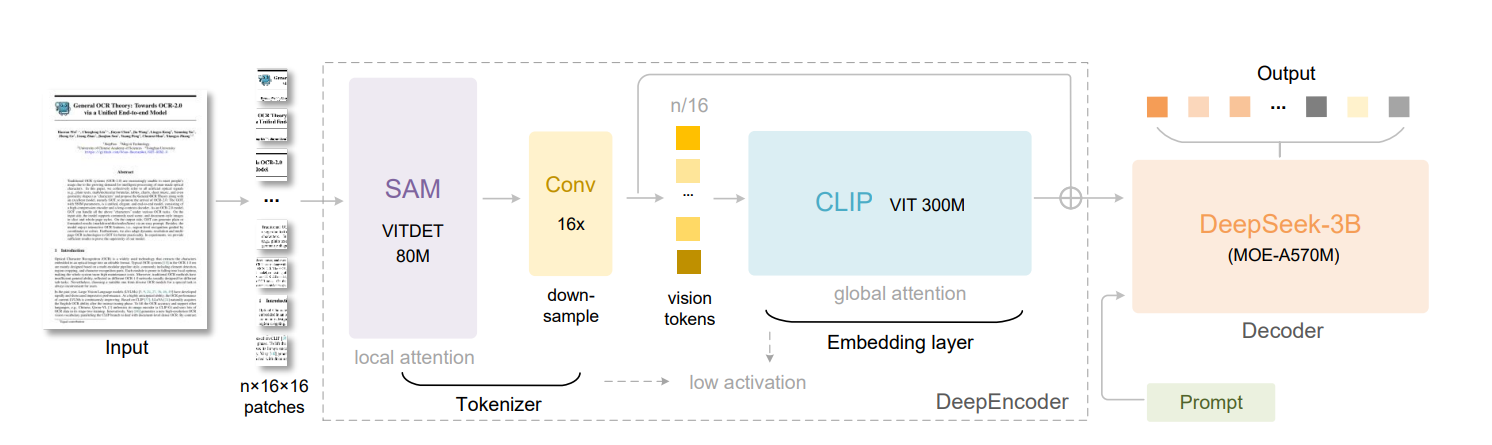
DeepEncoder 分为 SAM-base(块大小 16)和 CLIP-large 两部分
SAM-base
这是一个以 window attention 为主导的可视感知特征提取组件
作为 SAM 模型的输入,需要将图片拆为 16x16 的 patch,这是 ViTDET 架构所要求的
经过 SAM 处理后得到输出
CLIP-large
这是一个以 global attention 为主导的可视感知特征提取组件
CLIP(Contrastive Language-Image Pretraining): CLIP 能够把图像和文本映射到同一个向量空间里,使语义相似的图像和文字向量距离更近。
参考 Vary 的做法,先使用卷积(Conv)对 SAM 的输出进行 16x 的 down-sample,再通过 CLIP 模型处理
兼容各种分辨率

将图像依据分辨率分类,每一类的分辨率固定,分为 Tiny(512 x 512, 压缩后 $\frac{\frac{512}{16} \times \frac{512}{16}}{16} = 64$ Tokens)、Small(100)、Base(256)、Large(400) 类型,如果图像分辨率和所属类的固定分辨率不同,需要进行 resize 或 padding 调整。
对于 Tiny 和 Small 类型,本身分辨率就低,对图像的调整不敏感,就是直接用 resize 的方法改变形状强制调整为 1:1。对于 Base 和 Large,就用 padding 方法填充到 1:1,就像电影用 16:9 屏幕播放产生黑边一样,虽然浪费了部分 token 但保持了原图的形状。
MoE Decoder
DeepEncoder 带来了非常可观的 token 压缩率,但如何去读懂这些压缩后的信息也是非常关键的,压缩和解压的过程是相辅相成的,Decoder 所要做的就是解压操作。
使用了 DeepSeek V3 提出的 DeepSeekMoE
训练数据
OCR 1.0

标注信息包含图片和段落的位置信息(坐标),以及文字内容。对坐标进行了以 1000 为范围的归一化,统一不同文档间的坐标差异。
OCR 2.0
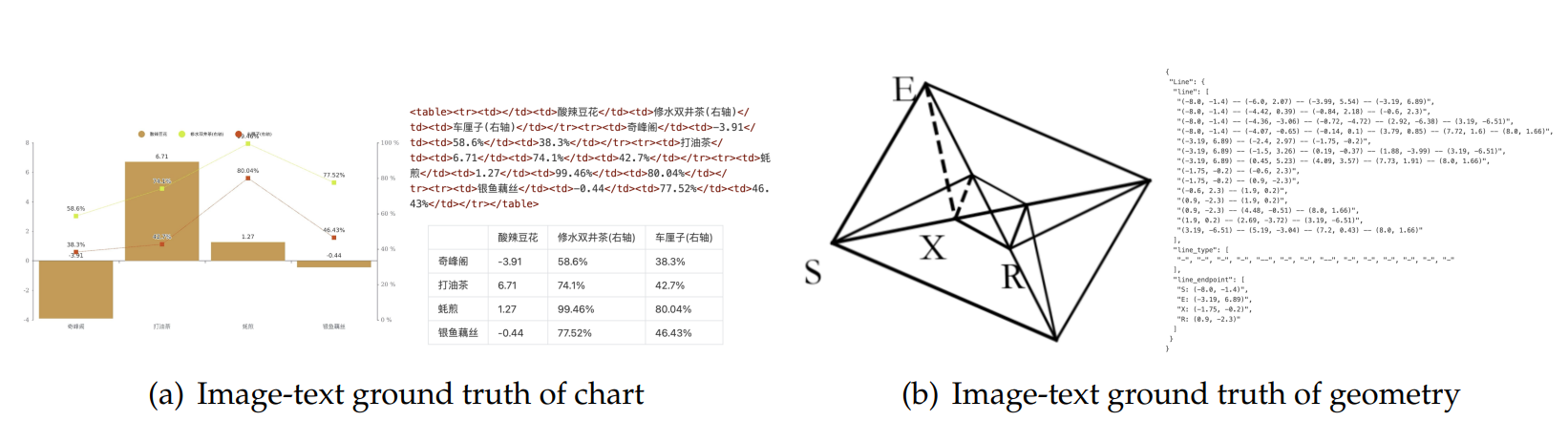
包含了图表、化学公式和平面几何解析数据
图表标注使用了 html 标签,化学公式用 SMILES 格式,平面几何图像遵循 Slow Perception
通用视觉数据
通用视觉数据处理不是 DeepSeek-OCR 的主要目的,这部分的训练数据仅有总数据的 20%
纯文本数据
为确保模型的语言能力(指令),纯文本训练数据还是需要的,仅占用 10%
训练过程
分为两步:
- 独立训练 DeepEncoder
- 训练 DeepSeek-OCR
训练 DeepEncoder
遵循 Vary
训练 DeepSeek-OCR
训练中 SAM 部分参数冻结,CLIP 部分不冻结
训练结果
对于 tiny 和 small 类型的图像:
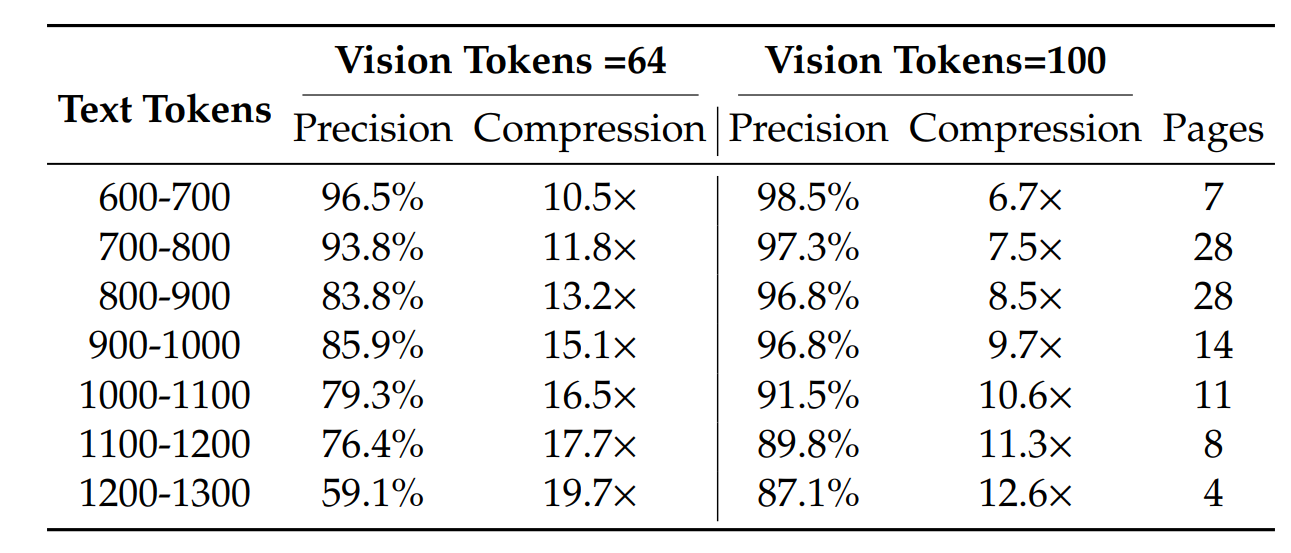
当压缩比为 10 左右时,能达到 96% 的准确度。
结果
某些类别的文档只需很少的 token 就能达到令人满意的性能,例如幻灯片,只需 64 个视觉 token。对于书籍和报告文档,DeepSeek-OCR 只需 100 个视觉 token 就能实现良好的性能。
当我们将近 20 倍地压缩标记时,我们发现精确度仍然可以接近 60%。这些结果表明,光学上下文压缩是一个非常具有前景且值得研究的研究方向。
讨论:遗忘机制

人类的遗忘机制是: 对事物的记忆会随着时间的推移越来越模糊(时间);对观看的内容的记忆会越随着的内容的远离越模糊(空间)。
是否可以为 vision 模型也添加这种遗忘特性,对于较旧的 context,用较小的 token 去表示,也就是使用更高的压缩率来模拟对事物的遗忘。