Linux内核学习笔记之进程管理和调度
进程生命周期
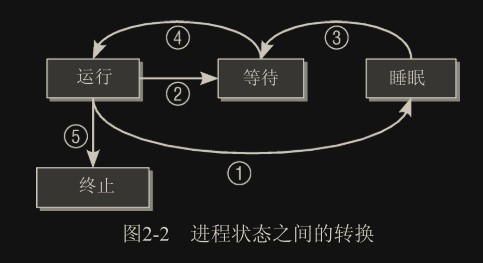
僵尸进程
进程正常结束需要两步:
- 程序终止:程序必须由另一个进程或一个用户杀死(通常是通过发送 SIGTERM 或 SIGKILL 信号来完成,这等价于正常地终止进程);
- 父进程确认:进程的父进程在子进程终止时必须调用或已经调用
wait4(读做 wait for)系统调用。这相当于向内核证实父进程已经确认子进程的终结。该系统调用使得内核可以释放为子进程保留的资源。
只有在第一步发生(程序终止)而第二步不成立的情况下(wait4),才会出现“僵尸”状态。在进程终止之后,其数据尚未从进程表删除之前,进程总是暂时处于“僵尸”状态。
抢占式多任务处理
抢占优先级:中断 > 系统调用(内核态) > 普通进程(用户态)
- 普通进程总是可能被抢占,甚至是由其他进程抢占。对于实现良好的交互行为和低系统延迟,这种抢占起到了重要作用。
- 如果系统处于内核态并正在处理系统调用,那么系统中的其他进程是无法夺取其 CPU 时间的。调度器必须等到系统调用执行结束,才能选择另一个进程执行,但中断可以中止系统调用。(一些关键内核操作可以选择关中断避免被中断强占)
- 中断可以暂停处于用户状态和内核态的进程。中断具有最高优先级,因为在中断触发后需要尽快处理。
进程表示
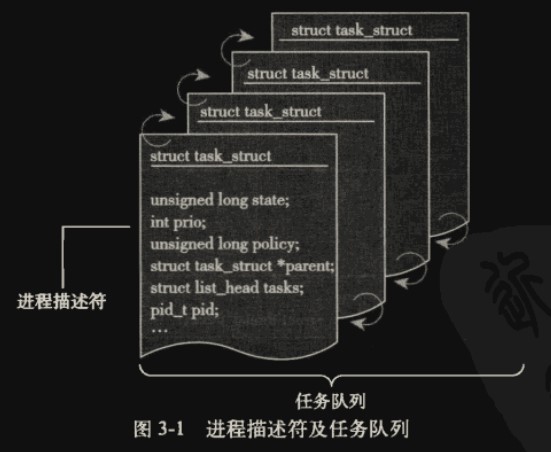
Linux 内核涉及进程和程序的所有算法都围绕一个名为 task_struct 的数据结构(称为进程描述符(process descriptor))建立,该结构定义在 include/sched.h 中。
内核把进程的列表存放在叫做任务队列(tasklist)的双向循环链表中。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
struct task_struct
{
volatile long state; /* -1表示不可运行,0表示可运行,>0表示停止 */
void *stack;
atomic_t usage;
unsigned long flags; /* 每进程标志,下文定义 */
unsigned long ptrace;
int lock_depth; /* 大内核锁深度 */
int prio, static_prio, normal_prio; //优先级
unsigned int rt_priority;
struct list_head run_list; // list_head 在上篇文章有提到
const struct sched_class *sched_class;
struct sched_entity se;
unsigned short ioprio;
unsigned long policy;
cpumask_t cpus_allowed;
unsigned int time_slice;
#if defined(CONFIG_SCHEDSTATS) || defined(CONFIG_TASK_DELAY_ACCT)
struct sched_info sched_info;
#endif
struct list_head tasks;
/*
* ptrace_list/ptrace_children链表是ptrace能够看到的当前进程的子进程列表。
*/
struct list_head ptrace_children;
struct list_head ptrace_list;
// 两者含义见https://blog.csdn.net/weixin_48101150/article/details/116207139
// mm为真实地址空间,active_mm为匿名地址空间
struct mm_struct *mm, *active_mm;
/* 进程状态 */
struct linux_binfmt *binfmt;
long exit_state;
int exit_code, exit_signal;
int pdeath_signal; /* 在父进程终止时发送的信号 */
unsigned int personality;
unsigned did_exec : 1;
pid_t pid;
pid_t tgid;
/*
* 分别是指向(原)父进程、最年轻的子进程、年幼的兄弟进程、年长的兄弟进程的指针。
*(p->father可以替换为p->parent->pid)
*/
struct task_struct *real_parent; /* 真正的父进程(在被调试的情况下) */
struct task_struct *parent; /* 父进程 */
/*
* children/sibling链表外加当前调试的进程,构成了当前进程的所有子进程
*/
struct list_head children; /* 子进程链表 */
struct list_head sibling; /* 连接到父进程的子进程链表 */
struct task_struct *group_leader; /* 线程组组长 */
/* PID与PID散列表的联系。 */
struct pid_link pids[PIDTYPE_MAX];
struct list_head thread_group;
struct completion *vfork_done; /* 用于vfork() */
int __user *set_child_tid; /* CLONE_CHILD_SETTID */
int __user *clear_child_tid; /* CLONE_CHILD_CLEARTID */
unsigned long rt_priority;
cputime_t utime, stime, utimescaled, stimescaled;
unsigned long nvcsw, nivcsw; /* 上下文切换计数 */
struct timespec start_time; /* 单调时间 */
struct timespec real_start_time; /* 启动以来的时间 */
/* 内存管理器失效和页交换信息,这个有一点争论。它既可以看作是特定于内存管理器的,
也可以看作是特定于线程的 */
unsigned long min_flt, maj_flt;
cputime_t it_prof_expires, it_virt_expires;
unsigned long long it_sched_expires;
struct list_head cpu_timers[3];
/* 进程身份凭据 */
uid_t uid, euid, suid, fsuid;
gid_t gid, egid, sgid, fsgid;
struct group_info *group_info;
kernel_cap_t cap_effective, cap_inheritable, cap_permitted;
unsigned keep_capabilities : 1;
struct user_struct *user;
char comm[TASK_COMM_LEN]; /* 除去路径后的可执行文件名称
-用[gs]et_task_comm访问(其中用task_lock()锁定它)
-通常由flush_old_exec初始化 */
/* 文件系统信息 */
int link_count, total_link_count;
/* ipc相关 */
struct sysv_sem sysvsem;
/* 当前进程特定于CPU的状态信息 */
struct thread_struct thread;
/* 文件系统信息 */
struct fs_struct *fs;
/* 打开文件信息 */
struct files_struct *files;
/* 命名空间 */
struct nsproxy *nsproxy;
/* 信号处理程序 */
struct signal_struct *signal;
struct sighand_struct *sighand;
sigset_t blocked, real_blocked;
sigset_t saved_sigmask; /* 用TIF_RESTORE_SIGMASK恢复 */
struct sigpending pending;
unsigned long sas_ss_sp;
size_t sas_ss_size;
int (*notifier)(void *priv);
void *notifier_data;
sigset_t *notifier_mask;
#ifdef CONFIG_SECURITY
void *security;
#endif
/* 线程组跟踪 */
u32 parent_exec_id;
u32 self_exec_id;
/* 日志文件系统信息 */
void *journal_info;
/* 虚拟内存状态 */
struct reclaim_state *reclaim_state;
struct backing_dev_info *backing_dev_info;
struct io_context *io_context;
unsigned long ptrace_message;
siginfo_t *last_siginfo; /* 由ptrace使用。*/
...
};
成员变量详解
state
指定了进程的当前状态,可使用下列值:
- TASK_RUNNING:就绪态或运行态,意味着可被调度器调度运行,但不一定占用着 CPU
- TASK_INTERRUPTIBLE:阻塞态,等待外部信号而转向就绪态
- TASK_UNINTERRUPTIBLE:类似 TASK_INTERRUPTIBLE,但忽略信号,只能由内核亲自唤醒。用于因内核指示而停用的睡眠进程。
- TASK_STOPPED:表示进程特意停止运行,例如,由调试器暂停。
- TASK_TRACED:本来不是进程状态,用于从停止的进程中,将当前被调试的那些(使用 ptrace 机制)与常规的进程区分开来。
以下部分也可用于 exit_state 变量:
- EXIT_ZOMBIE:如上篇文章所述的僵尸状态。
- EXIT_DEAD:已死亡状态,指 wait 系统调用已经发出,而进程完全从系统移除之前的状态。只有多个线程对同一个进程发出 wait 调用时,该状态才有意义
rlim
不知道为什么书中的示例代码里没有这个变量,看了源码应该是在
signal_struct结构体里
Linux 提供资源限制(resource limit,rlimit)机制,对进程使用系统资源施加某些限制。该机制利用了 task_struct 中的 rlim 数组,数组项类型为 struct rlimit。
1
2
3
4
struct rlimit {
unsigned long rlim_cur;
unsigned long rlim_max;
}
- rlim_cur 是进程当前的资源限制,也称之为软限制(soft limit)。
- rlim_max 是该限制的最大容许值,因此也称之为硬限制(hard limit)。
系统调用 setrlimit 来增减当前限制,但不能超出 rlim_max 指定的值。getrlimits 用于检查当前限制。
task_struct 中包含一个 rlim 数组,数组中的每一项表示一种资源类型:
| 常数 | 语义 |
|---|---|
| RLIMIT_CPU | Maximum CPU time in milliseconds. |
| RLIMIT_FSIZE | Maximum file size allowed. |
| RLIMIT_DATA | Maximum size of the data segment. |
| RLIMIT_STACK | Maximum size of the (user mode) stack. |
| RLIMIT_CORE | Maximum size for core dump files. |
| RLIMIT_RSS | Maximum size of the resident size set; in other words, the maximum number of page frames that a process uses. Not used at the moment. |
| RLIMIT_NPROC | Maximum number of processes that the user associated with the real UID of a process may own. |
| RLIMIT_NOFILE | Maximum number of open files. |
| RLIMIT_MEMLOCK | Maximum number of non-swappable pages. |
| RLIMIT_AS | Maximum size of virtual address space that may be occupied by a process. |
| RLIMIT_LOCKS | Maximum number of file locks. |
| RLIMIT_SIGPENDING | Maximum number of pending signals. |
| RLIMIT_MSGQUEUE | Maximum number of message queues. |
| RLIMIT_NICE | Maximum nice level for non-real-time processes. |
| RLIMIT_RTPRIO | Maximum real-time priority |
通过命令查看当前进程(shell 进程)的资源限制,每个进程都有对应的限制,存于单独的文件,self 就是当前正在 CPU 上运行的进程,也就是 shell 进程本身:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
root@racknerd-ae2d96:~# cat /proc/self/limits
Limit Soft Limit Hard Limit Units
Max cpu time unlimited unlimited seconds
Max file size unlimited unlimited bytes
Max data size unlimited unlimited bytes
Max stack size 8388608 unlimited bytes
Max core file size 0 unlimited bytes
Max resident set unlimited unlimited bytes
Max processes 3615 3615 processes
Max open files 1024 1048576 files
Max locked memory 127291392 127291392 bytes
Max address space unlimited unlimited bytes
Max file locks unlimited unlimited locks
Max pending signals 3615 3615 signals
Max msgqueue size 819200 819200 bytes
Max nice priority 0 0
Max realtime priority 0 0
Max realtime timeout unlimited unlimited us
进程创建
- fork:生成当前进程的一个相同副本,该副本称之为子进程。原进程的所有资源都以适当的方式复制到子进程,因此该系统调用之后,原来的进程就有了两个独立的实例。这两个实例的联系包括:同一组打开文件、同样的工作目录、内存中同样的数据(两个进程各有一份副本,得益于写时复制技术,实际上未被修改的内存都是被重用的),等等。此外二者别无关联。
- exec:从一个可执行的二进制文件加载另一个应用程序,来代替当前运行的进程。
命名空间
另可见容器,边缘计算与云原生这篇文章
概念
该功能目前最大的用处就是为容器服务。
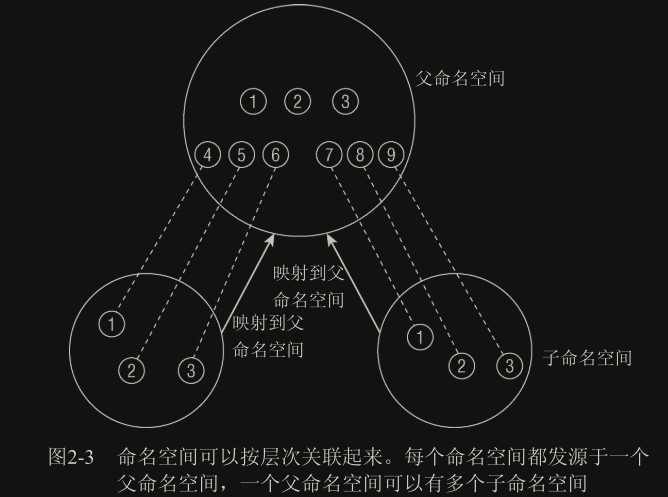
每个子命名空间内都有一个 init 进程,pid 为 0(虚拟 pid),但在父命名空间中有这个 init 进程的真实 pid(当然也有可能还有父父命名空间,这个也是虚拟的),构成映射。在子命名空间内可以随意使用这些虚拟的 pid,无需担心和其他命名空间冲突。
命名空间包含很多子系统,如 pid 子系统,uts 子系统等
实现
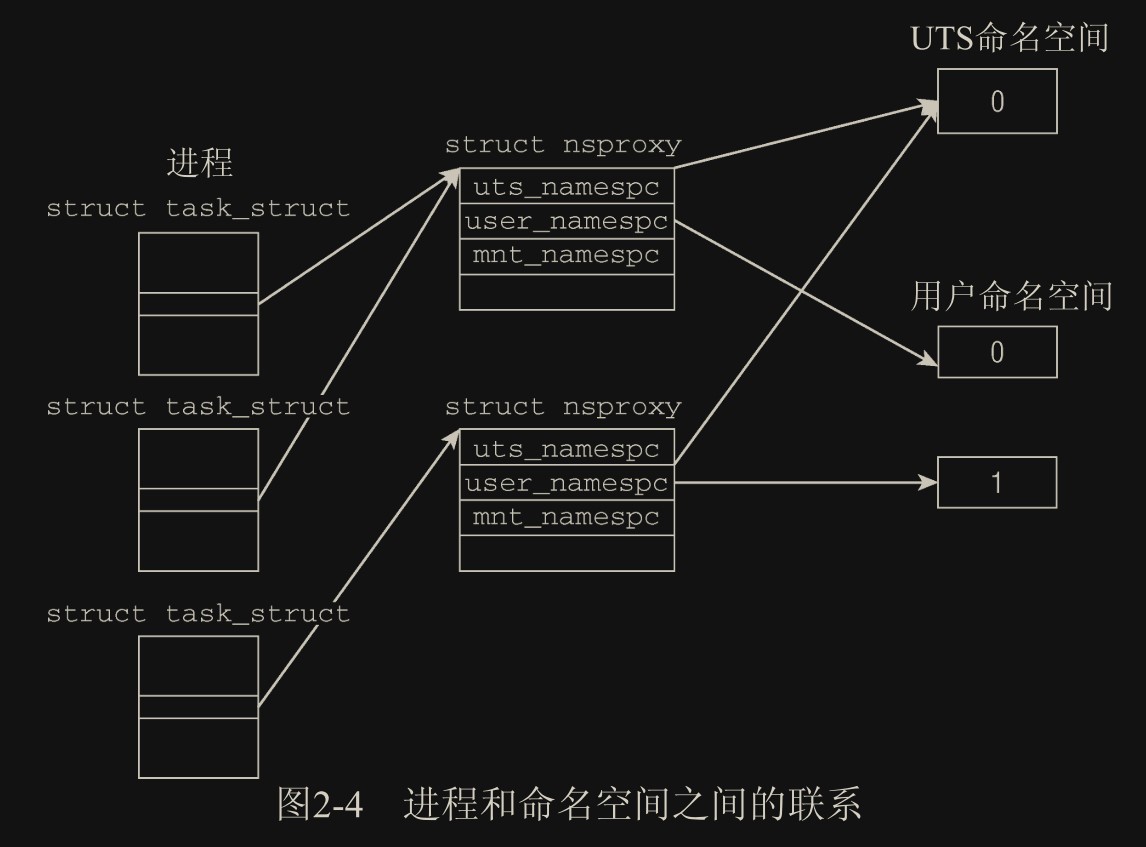
每个命名空间都由一个 nsproxy 结构维护,每个进程都关联到一个命名空间。两个不同的 nsproxy 可以关联同一个子系统命名空间结构,比如图中两个 nsproxy 都指向同一个 UTS 子系统命名空间对象,也就是这两个命名空间的 host 名都相同
1
2
3
4
5
6
7
8
9
10
// <nsproxy.h>
struct nsproxy {
atomic_t count;
struct uts_namespace *uts_ns;
struct ipc_namespace *ipc_ns;
struct mnt_namespace *mnt_ns;
struct pid_namespace *pid_ns;
struct user_namespace *user_ns;
struct net *net_ns;
};
为什么这个命名空间结构要叫
proxy,我猜是因为它里面的内容也是执行子系统对象的指针,而不是把对象直接放在里面,所以叫代理 proxy
各个变量含义:
uts_namespace包含了运行内核的名称、版本、底层体系结构类型等信息。UTS 是 UNIX Timesharing System 的简称。ipc_namespace保存在 struct ipc_namespace 中的所有与进程间通信(IPC)有关的信息。mnt_namespace已经装载的文件系统的视图,在 struct mnt_namespace 中给出。pid_namespace有关进程 ID 的信息,由 struct pid_namespace 提供。user_namespace保存的用于限制每个用户资源使用的信息。net_ns包含所有网络相关的命名空间参数。读者在第 12 章中会看到,为使网络相关的内核代码能够完全感知命名空间,还有许多工作需要完成。
在创建新进程时可使用 fork 建立一个新的命名空间,因此必须提供控制该行为的适当的标志作为参数(新版本里好像没了,是作为 clone 函数的参数实现的),每一位:
1
2
3
4
5
6
// <sched.h>
#define CLONE_NEWUTS 0x04000000 /* 创建新的utsname组 */
#define CLONE_NEWIPC 0x08000000 /* 创建新的IPC命名空间 */
#define CLONE_NEWUSER 0x10000000 /* 创建新的用户命名空间 */
#define CLONE_NEWPID 0x20000000 /* 创建新的PID命名空间 */
#define CLONE_NEWNET 0x40000000 /* 创建新的网络命名空间 */
每个进程都关联到自身的命名空间视图,通过指针变量方式:
1
2
3
4
5
6
7
// <sched.h>
struct task_struct {
...
/* 命名空间 */
struct nsproxy *nsproxy;
...
}
除非指定不同的选项,否则每个进程都会关联到一个默认命名空间,也就是 nsproxy 默认指向的命名空间结构。默认命名空间的作用则类似于不启用命名空间,所有的属性都相当于全局的。
init_nsproxy 定义了初始的全局命名空间,其中维护了指向各子系统初始的命名空间对象的指针:
1
2
3
4
5
6
7
8
9
10
11
12
13
// <kernel/nsproxy.c>
struct nsproxy init_nsproxy = INIT_NSPROXY(init_nsproxy);
// <init_task.h>
#define INIT_NSPROXY(nsproxy) { \
.pid_ns = &init_pid_ns, \
.count = ATOMIC_INIT(1), \
.uts_ns = &init_uts_ns, \
.mnt_ns = NULL, \
INIT_NET_NS(net_ns) \
INIT_IPC_NS(ipc_ns) \
.user_ns = &init_user_ns, \
}
uts_namespace
引用的所有的 uts namespace 的信息,uts 包含的信息上面也提到了
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
// <utsname.h>
struct uts_namespace
{
struct kref kref;
struct new_utsname name;
};
// <utsname.h>
struct new_utsname
{
char sysname[65];
char nodename[65];
char release[65];
char version[65];
char machine[65];
char domainname[65];
};
kref 是一个嵌入的引用计数器,可用于跟踪内核中有多少地方使用了 struct uts_namespace 的实例
各个字符串分别存储了系统的名称(Linux…)、内核发布版本、机器名,等等。使用 uname 工具可以取得这些属性的当前值,也可以在/proc/sys/kernel/中看到
内核如何创建一个新的 UTS 命名空间呢?这属于 copy_utsname 函数的职责。在某个进程调用 fork 并通过 CLONE_NEWUTS 标志指定创建新的 UTS 命名空间时(不指定就直接继承父进程的命名空间),则调用该函数。在这种情况下,会生成先前的 uts_namespace 实例的一份副本,当前进程(也就是子进程)的 nsproxy 实例内部的指针会指向新的副本。由于在读取或设置 UTS 属性值时,内核会保证总是操作特定于当前进程的 uts_namespace 实例,在当前进程修改 UTS 属性不会反映到父进程,而父进程的修改也不会传播到子进程(命名空间的隔离性)。
user_namespace
用户命名空间在数据结构管理方面类似于 UTS:在要求创建新的用户命名空间时,则生成当前用户命名空间的一份副本,并关联到当前进程的 nsproxy 实例。
1
2
3
4
5
6
7
// <user_namespace.h>
struct user_namespace
{
struct kref kref;
struct hlist_head uidhash_table[UIDHASH_SZ];
struct user_struct *root_user;
};
- kref 是一个引用计数器,用于跟踪多少地方需要使用 user_namespace 实例
- uidhash_table hlist_head 是一个内核的标准数据结构,用于建立双链散列表,见Linux 内核学习笔记之内核数据结构。散列表的每个 hlist_node 节点都是对应命名空间内的一个用户,可以分用户统计资源消耗情况。这里的
root 用户没有放在散列表里,而是有个单独的root_user指针指向。 - user_struct 结构维护了一些统计数据(如进程和打开文件的数目)。每个用户命名空间对其用户资源使用的统计,与其他命名空间完全无关(命名空间的隔离性),对 root 用户的统计也是如此。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
// kernel/user_namespace.c
static struct user_namespace *clone_user_ns(struct user_namespace *old_ns)
{
struct user_namespace *ns;
struct user_struct *new_user;
...
// 分配堆空间,类似malloc
ns = kmalloc(sizeof(struct user_namespace), GFP_KERNEL);
...
// 第二个参数uid为0表示root,分配新的root用户user_struct
ns->root_user = alloc_uid(ns, 0);
// 除了root用户,当前用户也分配个新的实例,放到新的命名空间 ns
/* 将current->user替换为新的 */
new_user = alloc_uid(ns, current->uid);
// 将struct task_struct的user成员指向新的user_struct实例
switch_uid(new_user);
return ns;
}
进程 ID 号(PID)
UNIX 进程总是会分配一个号码用于在其命名空间中唯一地标识它们。该号码被称作进程 ID 号,简称 PID。用 fork 或 clone 产生的每个进程都由内核自动地分配了一个新的唯一的 PID 值。
进程 ID
- PID: 全局 ID
- PGID: 进程组 ID
- TGID: 线程组 ID
- TID: 线程 ID
- SID: 会话 ID
Linux 中的线程其实也是进程,同样使用 task_struct 管理。处于某个线程组中的所有进程都有统一的线程组 ID(TGID),如果进程没有使用线程,则其 PID 和 TGID 相同。
线程组中的主进程被称作组长(group leader)。通过 clone 创建的所有线程的 task_struct 的 group_leader 成员,会指向组长的 task_struct 实例。
task_struct 中直接包含了 pid 和 tgid:
1
2
3
4
5
6
7
8
// <sched.h>
struct task_struct
{
...
pid_t pid;
pid_t tgid;
...
}
进程组:
独立进程可以合并成进程组(使用 setpgrp 系统调用),进程组成员的 task_struct 的 pgrp 属性值都是相同的,即进程组组长的 PID。
会话:
几个进程组可以合并成一个会话。会话中的所有进程都有同样的会话 ID,保存在 task_struct 的 session 成员中。SID 可以使用 setsid 系统调用设置。
进程组和会话一般用于信号控制,比如可以使用 kill 系统调用发送信号同时杀死一整个进程组。
因为命名空间存在,每个进程除了有全局 PID,还可能有局部 PID:
- 全局 ID 是在内核本身和初始命名空间中的唯一 ID 号(在系统启动期间开始的 init 进程即属于初始命名空间),整个系统唯一
- 局部 ID 属于某个特定的命名空间,不具备全局有效性。不同命名空间内可能有重复
会话和进程组 ID 不是直接包含在 task_struct 本身中,但保存在用于信号处理的结构(task_struct->signal)中
管理 PID
一个小型的子系统称之为PID分配器(pid allocator)用于加速新 ID 的分配。
内核需要提供辅助函数:
- 查找:通过 ID 及其类型查找进程的 task_struct 的功能,
- 转换:将 ID 的内核表示形式和用户空间可见的数值进行转换的功能。
数据结构
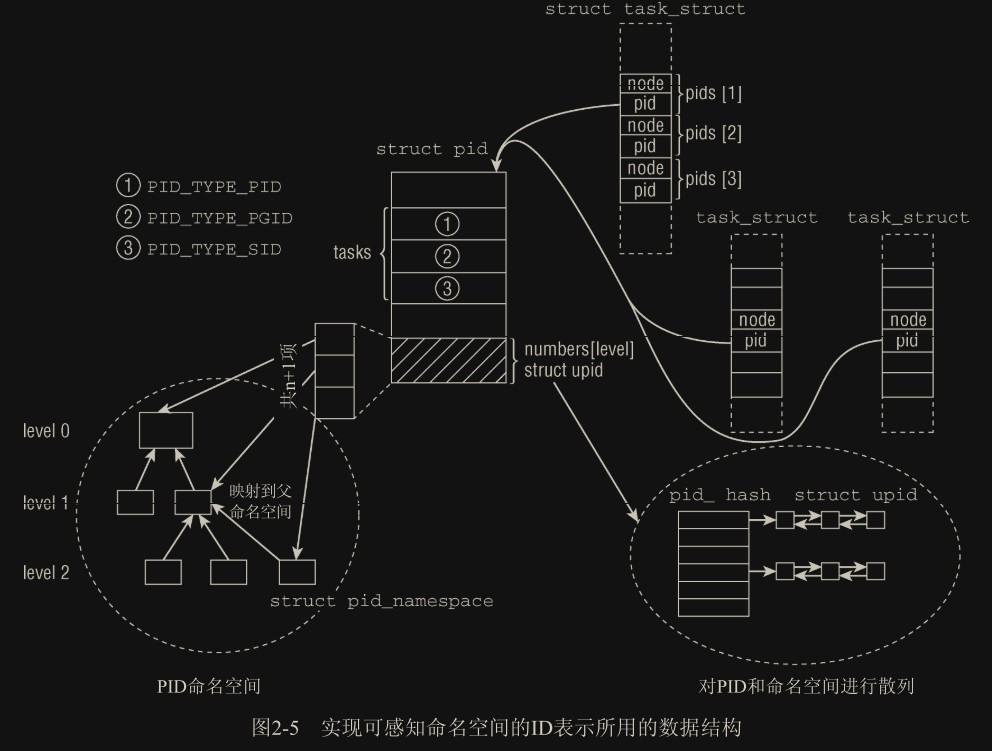
struct pid_namespace:
1
2
3
4
5
6
7
8
// <pid_namespace.h>
struct pid_namespace {
...
struct task_struct *child_reaper;
...
int level;
struct pid_namespace *parent;
};
- child_reaper:对应全局或局部的 init 进程,这个进程用于管理当前命名空间(PID 子系统)内的所有进程,如果有进程成了孤儿进程,由该 init 进程负责调用 wait 回收
- parent:指向父命名空间的指针
- level:当前命名空间在命名空间层次结构中的深度。初始命名空间的 level 为 0,初始命名空间的子空间 level 为 1,下一层的子空间 level 为 2,依次递推。level 的计算比较重要,因为 level 较高的命名空间中的 ID,对 level 较低的命名空间来说是可见的。从给定的 level 设置,内核即可推断进程会关联到多少个 ID。
sturct pid:
内核管理 pid 的结构,一个 pid号 对应一个 struct pid 结构,一个 struct pid 可以同时关联多种类型(进程、进程组、会话)的 pid号(通过 tasks 散列表成员):
- 进程 ID:该 struct pid 关联对应该 pid 号的单个进程
- 进程组 ID:该 struct pid 关联该 pid 号进程组下的所有进程
- 会话 ID:该 struct pid 关联该 pid 号会话对应的会话中所有进程
pid_type 用于区分这些类型
1
2
3
4
5
6
7
8
9
10
11
12
13
14
struct pid
{
atomic_t count;
struct hlist_head tasks[PIDTYPE_MAX];
int level;
struct upid numbers[1];
};
enum pid_type {
PIDTYPE_PID,
PIDTYPE_PGID,
PIDTYPE_SID,
PIDTYPE_MAX
};
- count: 引用计数器,表示被几个进程引用(比如如果关联了进程组,则会被该进程组中所有进程引用一次)
- tasks:散列表,保存了关联的进程、进程组和会话(每种类型单独一条链)。如果 type 为 PIDTYPE_PID,对应的链上应该只有一个对象,因为 pid 只能对应唯一的进程;如果 type 为 PIDTYPE_PGID 或 PIDTYPE_SID,则对应链上可能有好几个对象。我们知道进程是使用 task_struct 表述的,所以链上的就是 task_struct
- level:表示可以看到该进程(进程组、会话)的命名空间的数目(因为父级命名空间可以看到这个进程的命名空间,所以换言之,即该进程关联的 pid_namespace 命名空间在命名空间层次结构中的深度),代码层面上用于表示 numbers 数组的容量
- numbers:一个动态数组,表示本 pid 结构对应的进程所关联的 pid_namespace 以及对应的局部 pid。每个数组项都是一个 upid 结构,对应于一个(层) pid_namespace。如果进程关联的是全局 pid_namespace 命名空间,那么数组中就只有一个元素
动态数组
numbers 数组形式上只有一个数组项,但由于该数组位于结构的末尾,因此只要分配更多的内存空间,即可向数组添加附加的项,然后
level就相当于是 max_index,表示该数组的大小。(挺巧妙的方法,通过为该结构体分配更多空间来扩展最后一个元素的大小)
struct upid:
1
2
3
4
5
6
7
8
9
struct upid
{
// 局部pid值
int nr;
// 对应的pid命名空间
struct pid_namespace *ns;
// 链表节点,这里是被散列表管理的
struct hlist_node pid_chain;
};
结合上图,就是说如果 struct pid 中的 level 为 3,说明该进程关联的 pid_namespace 处于层级 2,numbers 列出该进程关联的 0,1,2 共三层 pid_namespace 以及对应在每个 pid_namespace 中的局部 pid(upid->nr)。
因为在 pid 结构中的 tasks 要存放 task_struct 类型散列表,所以要在 task_struct 添加 hlist_node,这里选择把 hlist_node 再封装了一层,同时使用数组的的方式关联到 PIDTYPE_MAX(一般为 3) 条链上:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
// <sched.h>
struct task_struct {
...
/* PID与PID散列表的联系。 */
struct pid_link pids[PIDTYPE_MAX];
...
};
// <pid.h>
struct pid_link
{
// 构成链表节点
struct hlist_node node;
// 指向 pid 结构,pid 结构中的 tasks 就是存放 node 的散列表,形成了双向关联
struct pid *pid;
};
双向关联 pid 结构和 task_struct 结构体的方法:
1
2
3
4
5
6
7
8
9
10
11
// kernel/pid.c
int fastcall attach_pid(struct task_struct *task, enum pid_type type, struct pid *pid)
{
struct pid_link *link;
link = &task->pids[type];
// 关联对应的pid结构
link->pid = pid;
// 往hash表对应的链表中插入一个该节点
hlist_add_head_rcu(&link->node, &pid->tasks[type]);
return 0;
}
至此,通过 task_struct 结构的 pid_link 就能访问 pid 结构,同时通过 pid 结构也可以通过遍历 tasks 访问到对应的 task_struct,也就是双向访问
现在需要方法通过 PID 数值查找到对应的 task_struct,这里使用了 hash 查找算法,将同一个 hash 的 PID 分为一组,组内成员用链表链接,正好用到了 hlist。想要查找的话,就是用 PID 值计算一个 hash 值(如果哈希表数组有 10 个元素,就是在 0-9 间散列),这个 hash 值就是哈希表数组的索引
1
2
3
// kernel/pid.c
// 定义哈希查找表的位置
static struct hlist_head *pid_hash;
辅助函数
内核提供了若干辅助函数,用于操作和扫描上面描述的数据结构。本质上内核必须完成下面两个 不同的任务:
- (1) 给出局部数字 ID 和对应的命名空间,查找此二元组描述的 task_struct。
- (2) 给出 task_struct、ID 类型、命名空间,取得命名空间局部的数字 ID。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
// <sched.h>
// 获取PID实例
static inline struct pid *task_pid(struct task_struct *task)
{
return task->pids[PIDTYPE_PID].pid;
}
// 获取进程组PGID实例
static inline struct pid *task_pgrp(struct task_struct *task)
{
return task->group_leader->pids[PIDTYPE_PGID].pid;
}
// 获取对应命名空间下的 pid 值
pid_t pid_nr_ns(struct pid *pid, struct pid_namespace *ns)
{
struct upid *upid;
pid_t nr = 0;
// 下级命名空间不能看到上级命名空间进程,ns->level必须小于等于pid->level,
// 也就是想要获取的命名空间比进程实际所在层级高(值越小越高)
if (pid && ns->level <= pid->level)
{
// 想要获取的命名空间层级
upid = &pid->numbers[ns->level];
// 再次判断确认下
if (upid->ns == ns)
nr = upid->nr;
}
return nr;
}
同理,可以通过 PID 查找对应的 pid 结构以及 task_struct,上一小节最后也提到了
生成唯一的 PID
为跟踪已经分配和仍然可用的 PID,内核使用一个大的位图,其中每个 PID 由一个比特标识。PID 的值可通过对应比特在位图中的位置计算而来。每个命名空间内都有这样一个位图,所以可以保证一个命名空间内不会有 PID 重复
1
2
3
4
5
// kernel/pid.c
// 分配一个(局部)PID,需要指定命名空间
static int alloc_pidmap(struct pid_namespace *pid_ns)
// 释放一个PID
static fastcall void free_pidmap(struct pid_namespace *pid_ns, int pid)
生成新进程时,需要在其所在的命名空间及父空间上都分配一个 PID:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
// kernel/pid.c
struct pid *alloc_pid(struct pid_namespace *ns)
{
struct pid *pid;
enum pid_type type;
int i, nr;
struct pid_namespace *tmp;
struct upid *upid;
...
tmp = ns;
// 遍历所有祖先命名空间
for (i = ns->level; i >= 0; i--)
{
// 每个命名空间上分配一个PID
nr = alloc_pidmap(tmp);
...
pid->numbers[i].nr = nr;
pid->numbers[i].ns = tmp;
tmp = tmp->parent;
}
pid->level = ns->level;
...
}
进程关系
- 如果进程 A 分支形成进程 B,进程 A 称之为父进程而进程 B 则是子进程。
- 如果进程 B 再次分支建立另一个进程 C,进程 A 和进程 C 之间有时称之为祖孙关系。
- 如果进程 A 分支若干次形成几个子进程 B1,B2,…,Bn,各个 Bi 进程之间的关系称之为兄弟关系。
task_struct 数据结构提供了两个链表表头,用于实现这些关系:
1
2
3
4
5
6
7
8
9
// <sched.h>
struct task_struct {
...
// children是链表表头,该链表中保存了进程的所有子进程
struct list_head children;
// sibling用于将兄弟进程彼此连接起来
struct list_head sibling;
...
}
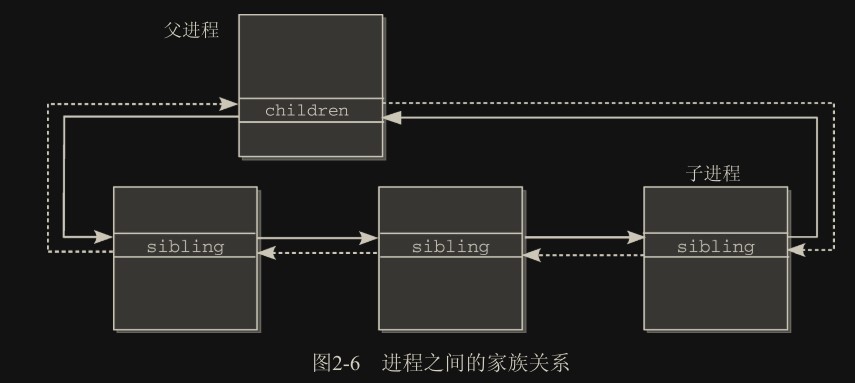
这是通过 list_head 实现的双向循环链表,表头是父进程的 children 节点。父进程的 children 和子进程们的 sibling 构成链。父进程的 sibling 和它的兄弟进程的 sibling 以及它们的父亲的 children 又构成另一条链。
链表的元素顺序可以表示创建的先后顺序
进程管理相关的系统调用
进程复制
有意思的是 Linux 并没有创建进程这一说法,所有进程都是从另一个进程复制(派生)而来
- fork 是重量级调用,因为它建立了父进程的一个完整副本,然后作为子进程执行。为减少与该调用相关的工作量,Linux 使用了写时复制(copy-on-write)技术
- vfork 类似于 fork,但并不创建父进程数据的副本。相反,父子进程之间共享数据。这节省了大量 CPU 时间(如果一个进程操纵共享数据,则另一个会自动注意到)。由于 fork 使用了写时复制技术,vfork 速度方面不再有优势,因此应该避免使用它。
- clone 产生线程,可以对父子进程之间的共享、复制进行精确控制。
写时复制
内核使用了写时复制(Copy-On-Write,COW)技术,以防止在 fork 执行时将父进程的所有数据复制到子进程。
在调用 fork 时,内核通常对父进程的每个内存页,都为子进程创建一个相同的副本。但是一般进程在 fork 后会立即执行 exec 来加载新程序,之前的地址空间就完全没用了,这浪费了内存空间和复制的时间。
内核通过仅复制页表而不复制页来规避上述缺点。这样两份页表都指向相同的物理页。
因为页的共享,父子进程不被允许修改这些页,这也是两个进程的页表对页标记了只读访问的原因。
当内核识别到对这类 COW 页 的修改时,内核会创建该页专用于当前进程的副本
COW 机制使得内核可以尽可能延迟内存页的复制,更重要的是,在很多情况下不需要复制。
执行系统调用
fork、vfork 和 clone 系统调用的入口点分别是 sys_fork、sys_vfork 和 sys_clone 函数。
注意下
fork()函数是glic 库提供的创建进程函数,实际最后还是会调用 sys_fork 系统调用,不要搞混
do_fork 是 sys_fork 会调用的一个函数,下节详细说明:
1
2
3
4
//kernel/fork.c
long do_fork(unsigned long clone_flags, unsigned long stack_start,
struct pt_regs *regs, unsigned long stack_size,
int __user *parent_tidptr, int __user *child_tidptr)
- clone_flags是一个标志集合,用来指定控制复制过程的一些属性。最低字节指定了在子进程终止时被发给父进程的信号号码。其余的高位字节保存了各种常数,下文会分别讨论。
- stack_start是用户态下栈的起始地址。(内核栈是自动分配的)
- regs是一个指向寄存器集合的指针,其中以原始形式保存了调用参数。该参数使用的数据类型是特定于体系结构的 struct pt_regs,其中按照系统调用执行时寄存器在内核栈上的存储顺序,保存了所有的寄存器(更详细的信息,请参考附录 A)。
- stack_size是用户态下栈的大小。该参数通常是不必要的,设置为 0。
- parent_tidptr和child_tidptr是指向用户空间中地址的两个指针,分别指向父子进程的 PID。NPTL(Native Posix Threads Library)库的线程实现需要这两个参数。我将在下文讨论其语义。
不同体系架构下 sys_fork 也会不同,下面以 x86 为例:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
// arch/x86/kernel/process_32.c
asmlinkage int sys_fork(struct pt_regs regs)
{
// 固定参数,SIGCHLD表示子进程终止后发送SIGCHLD信号通知父进程,复制父进程的栈
return do_fork(SIGCHLD, regs.esp, ®s, 0, NULL, NULL);
}
// arch/x86/kernel/process_32.c
asmlinkage int sys_clone(struct pt_regs regs)
{
// 先从寄存器读取参数
unsigned long clone_flags;
unsigned long newsp;
int __user *parent_tidptr, *child_tidptr;
clone_flags = regs.ebx;
newsp = regs.ecx;
parent_tidptr = (int __user *)regs.edx;
child_tidptr = (int __user *)regs.edi;
if (!newsp)
newsp = regs.esp;
// 从寄存器读出的参数,可指定独立的栈,最后两个指针用于和线程库通信
return do_fork(clone_flags, newsp, ®s, 0, parent_tidptr, child_tidptr);
}
do_fork 的实现
所有 3 个 fork 机制最终都调用了 kernel/fork.c 中的 do_fork(一个体系结构无关的函数)
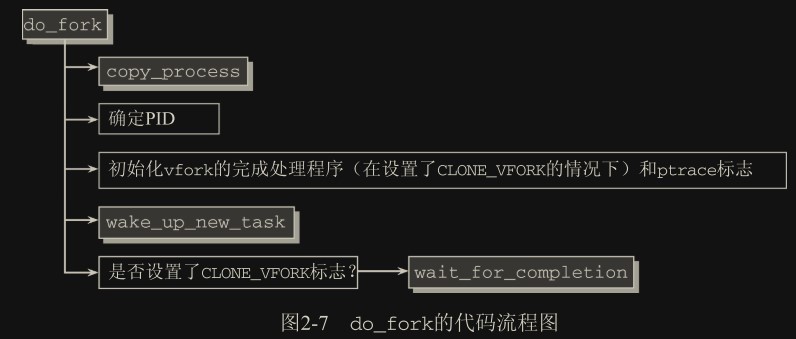
- copy_process:复制进程,并根据指定的标志重用父进程的数据。
确定 PID:为新进程分配 PID,如果不创建新的命名空间,则直接用
task_pid_vnr生成当前命名空间(从父进程中复制的命名空间 ns 指针)下的 PID。如果需要创建新命名空间,则此时子进程已经不知道父进程的命名空间(同时也是父命名空间)是什么了,需要用task_pid_nr_ns(p, current->nsproxy->pid_ns)指定父命名空间以建立继承关系并创建 PID1 2
// kernel/fork.c nr = (clone_flags & CLONE_NEWPID) ? task_pid_nr_ns(p, current->nsproxy->pid_ns) : task_pid_vnr(p);
- 如果将要使用 Ptrace(参见第 13 章)监控新的进程,那么在创建新进程后会立即向其发送 SIGSTOP 信号,以便附接的调试器检查其数据。
- 子进程使用
wake_up_new_task唤醒。也就是将其 task_struct 添加到调度器队列。调度器可能会优先调度子进程,来让子进程优先于父进程运行,以便及时执行exec,防止父进程修改共享内存导致写时复制技术开始生成副本。 - 如果使用 vfork 机制(内核通过设置的 CLONE_VFORK 标志识别),必须启用子进程的完成机制 (completions mechanism)。父进程会睡眠直至子进程通知完成。(这个挺少用到了,vfork 就是父子完全共享内存,不允许修改,所以父进程必须睡眠)
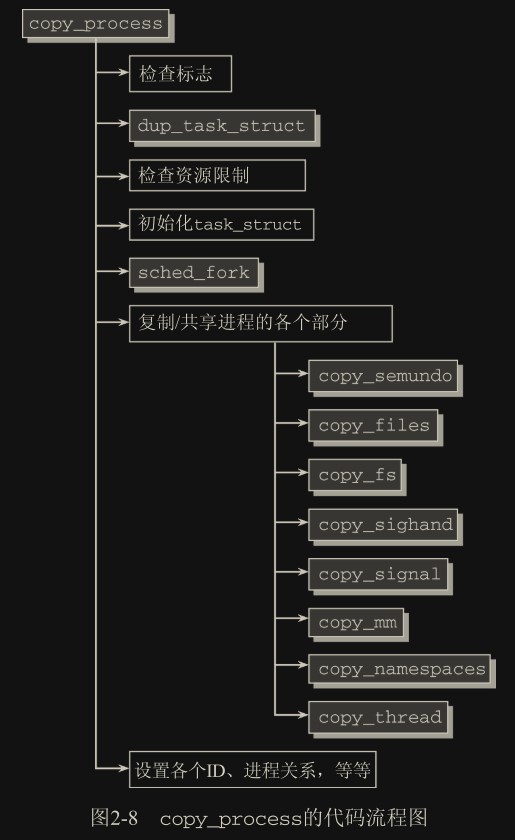
复制进程
在 do_fork 中大多数工作是由 copy_process 函数完成的,其代码流程如图所示。请注意,该函数必须处理 3 个系统调用(fork、vfork 和 clone)的主要工作。
其中 clone 允许传递大量的参数给 copy_process
1
2
3
4
5
6
7
8
9
10
11
12
13
14
// kernel/fork.c
static struct task_struct *copy_process(unsigned long clone_flags,
unsigned long stack_start, struct pt_regs *regs,
unsigned long stack_size, int __user *child_tidptr,
struct pid *pid)
{
int retval;
struct task_struct *p;
int cgroup_callbacks_done = 0;
// 如果同时启用CLONE_NEWNS和CLONE_FS表示非法操作
if ((clone_flags & (CLONE_NEWNS | CLONE_FS)) == (CLONE_NEWNS | CLONE_FS))
return ERR_PTR(-EINVAL);
...
}
Linux 返回值
Linux 有时候在操作成功时需要返回指针,而在失败时则返回错误码。而 C 语言中返回值只允许一个类型,也就是要把错误码也变成指针形式。Linux 支持的每个体系结构的虚拟地址空间中都有一个从虚拟地址 0 到至少 4 KiB 的区域没有任何意义,可以用这些区域对应的地址作为指针值,调用者判断返回值指针指向这些区域就表示错误码
检查标志:
- 在用
CLONE_THREAD创建一个线程时,必须用CLONE_SIGHAND激活信号共享。通常情况下,一个信号无法发送到线程组中的各个线程。 - 只有在父子进程之间共享虚拟地址空间时(
CLONE_VM),才能提供共享的信号处理程序。线程必须与父进程共享地址空间
dup_task_struct:
新进程分配了一个新的内核态栈,即 task_struct->stack。通常栈和 thread_info 一同保存在一个联合 thread_union 中,thread_info 保存了线程所需的所有特定于处理器的底层信息。
内核栈和用户栈
用户栈是用户空间中的一块区域,用于保存用户进程的子程序(函数)间相互调用的参数、返回值以及局部变量等信息。在 linux 系统中,用户栈的大小一般是可变的,可以通过 ulimit 命令设置。
内核栈是内核空间中为每个进程分配的一块区域,用于保存进程在内核态执行时的函数调用、系统调用、异常处理等信息,还会保存上下文切换时被切换的进程的寄存器等信息(进程切换时会陷入内核态,所以实际会使用进程的内核栈存放信息)。在 linux 系统中,内核栈的大小一般是固定的,通常为 8KB 或 16KB。
当进程从用户态切换到内核态时,需要保留用户态现场(上下文、寄存器、用户栈等),复制用户态参数,用户栈切到内核栈,进入内核态。当进程从内核态切换回用户态时,需要恢复用户态现场(上下文、寄存器、用户栈等),释放或回收内核资源,返回到原来的执行点。
1
2
3
4
5
6
// <sched.h>
union thread_union
{
struct thread_info thread_info;
unsigned long stack[THREAD_SIZE / sizeof(long)];
};
该联合实际上的内存分布情况(thread_info 和 task_struct 构成双向引用,每个“线程”都有这样的一对):
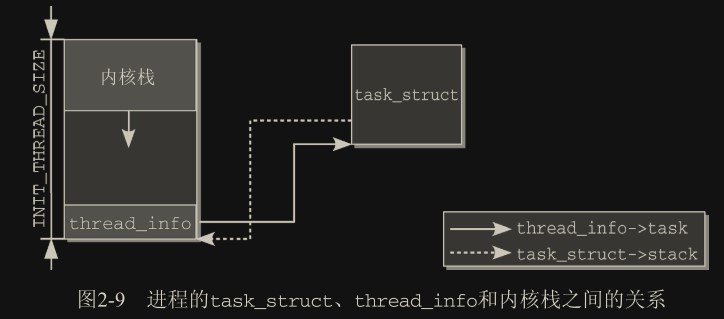
要注意栈使用过度会有覆盖 thread_info 的风险,因为两者共用同一段内存了。在 2.5 版本前,task_struct 是直接放在内核栈中的,就放在上图中 thread_info 的位置,这么做不仅会占用大量的内核栈空间,也有很大的被覆盖风险。后来 task_struct 都使用 slab 分配,同时定义了新的 thread_info,通过指针的方式指向 task_struct 对象。这样占用的栈空间就小了很多,被覆盖的可能也低了很多。
1
2
3
4
5
6
7
8
9
10
11
12
// <asm-arch/thread_info.h>
struct thread_info
{
struct task_struct *task; /* 当前进程task_struct指针 */
struct exec_domain *exec_domain; /* 执行区间 */
unsigned long flags; /* 底层标志 */
unsigned long status; /* 线程同步标志 */
__u32 cpu; /* 当前CPU */
int preempt_count; /* 0 => 可抢占, <0 => BUG */
mm_segment_t addr_limit; /* 线程地址空间(进程可以使用的虚拟地址的上限) */
struct restart_block restart_block; /* 实现信号机制 */
}
复制进程(创建线程)时该联合也会创建副本,其中 thread_info 部分会完全拷贝,栈则是新的。父子进程的 task_struct 除了 stack 指针外,其他部分完全相同(直接拷贝)
检查资源限制:
在 dup_task_struct 成功之后,内核会检查当前的特定用户在创建新进程之后,是否超出了允许的最大进程数目:
1
2
3
4
5
6
7
8
9
// kernel/fork.c
if (atomic_read(&p->user->processes) >=
p->signal->rlim[RLIMIT_NPROC].rlim_cur)
{
if (!capable(CAP_SYS_ADMIN) && !capable(CAP_SYS_RESOURCE) &&
p->user != current->nsproxy->user_ns->root_user)
goto bad_fork_free;
}
...
拥有当前进程的用户,其资源计数器保存一个 user_struct 实例(同一命名空间下的一个用户只有一个,不同命名空间下用户独立,如 root 用户就是独立的)中。task_struct 中有一个指向 user_struct 的实例的 user 指针(新版本好像没了),user_struct 中有个 processes 表示用于当前进程数。如果该值超出 rlimit 设置的限制,则放弃创建进程
初始化 task_struct:
没什么好说的
sched_fork:
开始调度新的进程。本质上,该例程会初始化一些统计字段,在多处理器系统上,如果有必要可能还会在各个 CPU 之间对可用的进程重新均衡一下,此外进程状态设置为 TASK_RUNNING(实际并没有开始运行,后面还需要一些配置后才会真正运行)。
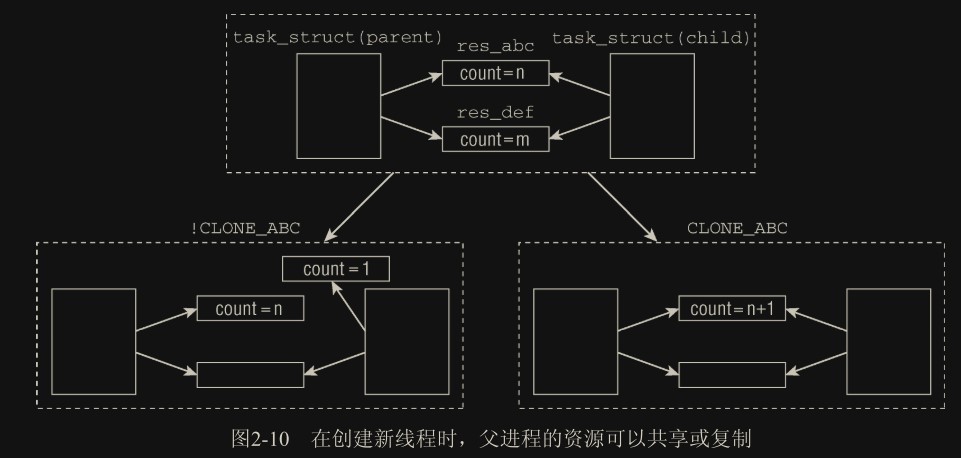
复制/共享进程的各个部分:
子进程的 task_struct 是从父进程的 task_struct 精确复制而来,因此相关的指针最初都指向同样的资源。通过一些标志来明确哪些该共享,哪些不该共享(如下图中的 CLONE_ABC 标志)。
设置各个 ID、进程关系,等等:
内核必须填好 task_struct 中对父子进程不同的各个成员:
task_struct中包含的各个链表元素,例如 sibling 和 children;- 间隔定时器成员 cpu_timers(参见第 15 章);
- 待决信号列表(pending),将在第 5 章讨论。
下面会提到很多 current,意思是当前进程,此时子进程还未创建完成,其 task_struct 结构为 p,p 的父进程就是 current
用之前描述的机制为进程分配一个新的 pid 实例,然后为 task_struct 赋值。
整个线程组使用组长(主线程)的 PID 作为线程组 ID(TGID),它们的父进程是组长进程的父进程。
1
2
3
4
5
6
7
8
9
10
11
12
// kernel/fork.c
// 根据pid实例获取全局pid号
p->pid = pid_nr(pid);
// 普通进程的线程组ID和pid相同(可以理解为只有一个线程,自己就是组长)
p->tgid = p->pid;
// 如果是线程
if (clone_flags & CLONE_THREAD)
// 线程的线程组ID和组长的pid相同(组长可以理解为主线程,
// 概念上来说线程并非一个进程,但Linux里的实现将其当作进程,且有独立的PID)
// current表示组长
p->tgid = current->tgid;
...
假设新 fork 的进程为 A,当前进程为 B。一般情况下,我们认为 A 是 B 的子进程,B 是 A 的父进程。但如果在fork()时指定了CLONE_PARENT或CLONE_THREAD,则表示保留 当前进程(curr) 的父进程信息,也就是说 A 和 B 变为兄弟进程,此时 A 的父进程不是 B 而是 B 的父进程:
1
2
3
4
5
6
7
8
// kernel/fork.c
if (clone_flags & (CLONE_PARENT | CLONE_THREAD))
// 成为兄弟关系
p->real_parent = current->real_parent;
else
// 成为父子关系
p->real_parent = current;
p->parent = p->real_parent;
对线程来说,其线程组组长是当前进程(实际父进程)的组长,也就是其本身:
1
2
3
4
5
6
7
8
// kernel/fork.c
p->group_leader = p;
if (clone_flags & CLONE_THREAD)
{
p->group_leader = current->group_leader;
list_add_tail_rcu(&p->thread_group, &p->group_leader->thread_group);
...
}
新进程接下来必须通过 children 链表与父进程连接起来:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
// kernel/fork.c
add_parent(p);
// 检查新进程的pid和tgid是否相同。倘若如此,则该进程是线程组的组长(也就是普通进程)。
if (thread_group_leader(p))
{
// 如果创建新PID命名空间
if (clone_flags & CLONE_NEWPID)
// child_reaper之前提到过是命名空间下的init进程指针,
// 如果创建新命名空间,这个进程就是该命名空间的第一个进程,
// 必须由它承担init的职责,所以init进程就是它本身
// 注意下创建命名空间的过程不在这里,这里是已经创建好的情况
p->nsproxy->pid_ns->child_reaper = p;
// 新进程加入当前进程组
set_task_pgrp(p, task_pgrp_nr(current));
// 新进程加入当前会话
set_task_session(p, task_session_nr(current));
attach_pid(p, PIDTYPE_PGID, task_pgrp(current));
attach_pid(p, PIDTYPE_SID, task_session(current));
}
attach_pid(p, PIDTYPE_PID, pid);
...
return p;
}
创建线程时的特别问题
用户空间线程库使用 clone 系统调用来生成新线程。该调用支持(上文讨论之外的)标志,对 copy_process(及其调用的函数)具有某些特殊影响。
一些专用于线程库的标志,这里不做介绍
内核线程
内核线程是直接由内核本身启动的进程。内核线程实际上是将内核函数委托给独立的进程,与系统中其他进程“并行”执行(实际上,也并行于内核自身的执行),内核线程经常称之为(内核)守护进程。
内核线程的存在并不违背宏内核的设计理念,因为内核线程是“线程”而不是“进程”,内核线程在内核态运行且可以直接访问内核地址空间的所有内容,而无需使用进程间通信,所以本质上还是内核整体的一部分。
用于执行下列任务:
- 周期性地将修改的内存页与页来源块设备同步(例如,使用 mmap 的文件映射)(这里说的应该是块设备页的缓存,定期将脏页写入块设备持久化保存)。
- 如果内存页很少使用,则写入交换区。
- 管理延时动作(deferred action)。
- 实现文件系统的事务日志。
基本上,有两种类型的内核线程:
- 阻塞型:线程启动后一直等待,直至内核请求线程执行某一特定操作。
- 周期型:线程启动后按周期性间隔运行,检测特定资源的使用,在用量超出或低于预置的限制值时采取行动。内核使用这类线程用于连续监测任务。
调用 kernel_thread 函数可启动一个内核线程, fn 是要执行的函数,arg 是该函数的参数,flags 是 CLONE 标志(挺像 pthread 线程库的启动函数的):
1
2
// <asm-arch/processor.h>
int kernel_thread(int (*fn)(void *), void *arg, unsigned long flags)
kernel_thread 的第一个任务是构建一个 pt_regs 实例,对其中的寄存器指定适当的值,这与普通的 fork 系统调用类似。接下来调用我们熟悉的 do_fork 函数
1
p = do_fork(flags | CLONE_VM | CLONE_UNTRACED, 0, ®s, 0, NULL, NULL);
因为内核线程是由内核自身生成的,应该注意下面两个特别之处:
内核空间和用户空间
大多数计算机上系统的全部虚拟地址空间分割成两个部分:
- 用户空间:可以由用户层程序访问
- 内核空间:专供内核使用
内核空间和用户空间有很高的隔离性,用户进程无法访问内核空间,但可以通过系统调用陷入内核态,此时系统调用可以访问内核空间。处于内核态时,也不能直接访问用户空间,需要通过
copy_from_user()和copy_to_user()API 保证访问合法性。
1
2
3
4
5
6
// <sched.h>
struct task_struct {
...
struct mm_struct *mm, *active_mm;
...
}
进程所使用的用户空间由 task_struct 中的 mm 描述,当内核执行上下文切换时,内核会找对应进程的 mm,并以此做切换页表、更新 TLB 等其他操作(具体的可见内存描述符)。
内核线程通过把自己的 task_struct 中的 mm 设置为 NULL 来避免访问用户空间(即使这些用户空间也是这个进程私有的,这是为了惰性 TLB 功能)
惰性 TLB:假如用户进程切换到内核线程,又切回同一个用户进程,此时由于内核线程不会去改 mm 内的东西(因为 mm 被设为 NULL 了,这些空间访问不到,也改不了),所以 TLB 表可以不切换到内核线程,从内核线程退出时 TLB 表也不用切换,相当于省了两次切换。
内核线程可以用下面几种方法实现:
- 直接调用
kernel_thread- 该函数从内核线程释放其父进程(用户进程)的所有资源(为了避免冲突,所有资源都会被上锁,直到线程结束,但一般内核线程会一直运行,所以干脆把父进程的资源都释放了,反正也用不了了)
- daemonize 阻塞信号的接收
- 将 init 用作该内核线程的父进程
使用更现代的
kthread_create1 2
// kernel/kthread.c struct task_struct *kthread_create(int (*threadfn)(void *data), void *data, const char namefmt[], ...)
最初该线程是停止的,需要使用
wake_up_process启动它。宏 kthread_run封装了创建和启动kthread_create_cpu 可以取代 kthread_create 用于绑定特定 CPU
使用
kthread_runkthread_run 封装了 kthread_create 和 wake_up_process,也就是创建和启动过程合并了
内核线程会出现在系统进程列表中,但在 ps 的输出中由方括号包围,以便与普通进程区分,斜杠后表示绑定的 CPU 编号:
1
2
3
4
5
6
7
8
9
10
11
12
wolfgang@meitner> ps fax
PID TTY STAT TIME COMMAND
2? S< 0:00 [kthreadd]
3? S< 0:00 _ [migration/0]
4? S< 0:00 _ [ksoftirqd/0]
5? S< 0:00 _ [migration/1]
6? S< 0:00 _ [ksoftirqd/1]
...
52? S< 0:00 _ [kblockd/3]
55? S< 0:00 _ [kacpid]
56? S< 0:00 _ [kacpi_notify]
...
启动新程序
execve 的实现
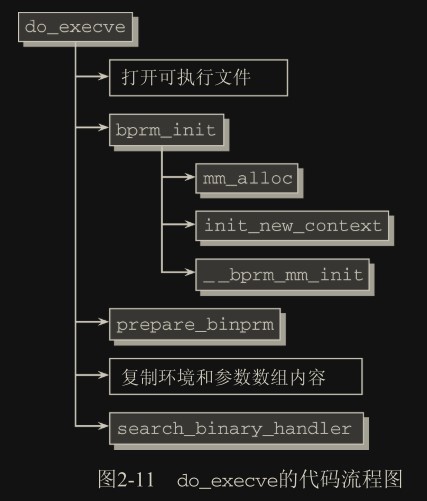
打开可执行文件:
首先打开要执行的文件,这个是文件系统的工作
bprm_init:
bprm_init 接下来处理若干管理性任务:
mm_alloc生成一个新的 mm_struct 实例来管理进程地址空间(参见第 4 章)。init_new_context是一个特定于体系结构的函数,用于初始化该实例__bprm_mm_init则建立初始的栈。
linux_binprm:
新进程的各个参数(例如,euid、egid、参数列表(argv[])、环境(环境变量)、文件名,等等)随后会分别传递给其他函数,此时为简明起见,则合并成一个类型为 linux_binprm 的结构
复制环境和参数数组内容:
将 linux_binprm 内容复制到进程结构中
search_binary_handler:
Linux 支持可执行文件的各种不同组织格式。标准格式是 ELF(Executable and Linkable Format)。
search_binary_handler 用于识别正确的二进制格式
二进制格式处理程序负责将新程序的数据加载到旧的地址空间中:
- 释放原进程使用的所有资源
- 将应用程序映射到虚拟地址空间中:
- text 段包含程序的可执行代码
- 预先初始化的数据(data 段)
- 堆
- 栈
- 程序的参数和环境
- 设置进程的指令指针和其他特定于体系结构的寄存器,以便在调度器选择该进程时开始执行程序的
main函数。
Linux 支持的二进制格式:
| 名称 | 含义 |
|---|---|
| flat_format | 平坦格式用于没有内存管理单元(MMU)的嵌入式 CPU 上。为节省空间,可执行文件中的数据还可以压缩(如果内核可提供 zlib 支持) |
| script_format | 这是一种伪格式,用于运行使用#!机制的脚本。检查文件的第一行,内核即知道使用何种解释器,启动适当的应用程序即可(例如,如果是#! /usr/bin/perl,则启动 Perl) |
| misc_format | 这也是一种伪格式,用于启动需要外部解释器的应用程序。与#!机制相比,解释器无须显式指定,而可以通过特定的文件标识符(后缀、文件头,等等)确定。例如,该格式用于执行 Java 字节代码或用 Wine 运行 Windows 程序 |
| elf_format | 这是一种与计算机和体系结构无关的格式,可用于 32 位和 64 位。它是 Linux 的标准格式 |
| elf_fdpic_format | ELF 格式变体,提供了针对没有 MMU 系统的特别特性 |
| irix_format | ELF 格式变体,提供了特定于 Irix 的特性 |
| som_format | 在 PA-Risc 计算机上使用,特定于 HP-UX 的格式 |
| aout_format | a.out 是引入 ELF 之前 Linux 的标准格式。因为它太不灵活,所以现在很少使用 |
解释二进制格式
在 Linux 内核中,每种二进制格式都表示为下列数据结构(已经简化过)的一个实例:
1
2
3
4
5
6
7
8
9
10
// <binfmts.h>
struct linux_binfmt
{
struct linux_binfmt *next;
struct module *module;
int (*load_binary)(struct linux_binprm *, struct pt_regs *regs);
int (*load_shlib)(struct file *);
int (*core_dump)(long signr, struct pt_regs *regs, struct file *file);
unsigned long min_coredump; /* minimal dump size */
};
对于每种二进制格式对象都必须提供下面 3 个函数(应该是内核提供的,每种格式的函数都相同):
- (1) load_binary 用于加载普通程序。
- (2) load_shlib 用于加载共享库,即动态库。
- (3) core_dump 用于在程序错误的情况下输出内存转储。该转储随后可使用调试器(例如,gdb)分析,以便解决问题。min_coredump 是生成内存转储时,内存转储文件长度的下界(通常,这是一个内存页的长度)。
每种二进制格式对象首先必须使用 register_binfmt 向内核注册(每种格式仅注册一次,后续该格式文件都可用这个结构)。该函数的目的是向一个链表增加一种新的二进制格式,该链表的表头是 fs/exec.c 中的全局变量 formats。linux_binfmt 实例通过其 next 成员彼此连接起来。
退出进程
进程可以主动调用 exit 系统调用终止自己,也可以被动的被终止。即使代码中没有显式使用 exit 系统调用,C 编译器也会自动在 main()函数返回前加上 exit()。
释放进程关联的资源
- 将 tast_struct 中的标志成员设置为
PF_EXITING。 - 调用 del_timer_sync()删除关联的内核定时器。根据返回的结果,它确保没有定时器在排队,也没有定时器处理程序在运行。
- 如果 BSD 的进程记账功能是开启的,do_exit()调用 acct_update_integrals()来输出记账信息。
- 然后调用 exit_mm()函数释放进程占用的
mm_struct,如果没有别的进程使用它们(也就是说,这个地址空间没有被共享),就彻底释放它们。 - 接下来调用 sem_exit()函数。如果进程排队等候 IPC 信号,它则离开队列。
- 调用 exit_files()和 exit_fs(),以分别递减文件描述符、文件系统数据的引用计数。如果其中某个引用计数的数值降为零,那么就代表没有进程在使用相应的资源,此时可以释放。
- 接着把存放在 task_struct 的
exit_code成员中的任务退出代码置为由 exit()提供的退出代码,或者去完成任何其他由内核机制规定的退出动作。退出代码存放在这里供父进程随时检索。 - 调用
exit_notify()向父进程发送信号,给子进程重新找养父,养父为线程组中的其他线程或者为 init 进程,并把本进程状态(存放在 task_struct 结构的 exit_state 中)设成EXIT_ZOMBIE(僵尸状态)。 - do_exit()调用 schedule()切换到新的进程(参看第 4 章)为处于 EXIT_ZOMBIE 状态的进程不会再被调度,所以这是进程所执行的最后一段代码。do_exit()永不返回。
至此,与进程相关联的所有独享的资源都被释放掉了。它现在占用的内存空间只有内核栈、thread_info 结构和 task_struct 结构。接下来就是清理这些信息。
释放进程相关描述信息
在父进程获得已终结的子进程的信息后,会调用 wait() 来通知内核可以清理这些残留的进程描述信息,wait()这一族函数都是通过唯一(但是很复杂)的一个系统调用 wait4()来实现的。它的标准动作是挂起调用它的进程,直到其中的一个子进程退出,此时函数会返回该子进程的 PID。此外,调用该函数时提供的指针会包含子函数退出时的退出代码。
之后内核将调用 release_task() 释放残留的进程描述信息:
- 它调用
__exit_signal(),该函数调用__unhash_process(),后者又调用detach_pid()从 pidhash 上删除该进程,同时也要从任务列表中删除该进程。 __exit_signal()释放目前僵死进程所使用的所有剩余资源,并进行最终统计和记录。- 如果这个进程是线程组最后一个进程,并且领头进程已经死掉,那么 release_task()就要通知僵死的领头进程的父进程。
- release_task()调用 put_task_struct() 释放进程内核栈和 thread_info 结构所占的页,并释放
task_struct所占的 slab 高速缓存。
至此,进程描述符和所有进程独享的资源就全部释放掉了。
调度器的实现
概观
内核必须提供一种方法,在各个进程之间尽可能公平地共享 CPU 时间,而同时又要考虑不同的任务优先级。
schedule 函数是理解调度操作的起点。该函数定义在 kernel/sched.c 中,是内核代码中最常调用的函数之一。
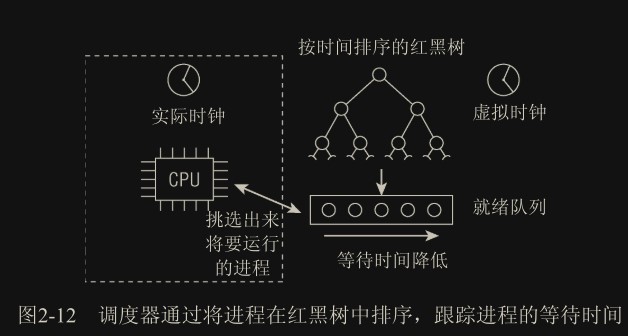
Linux 调度器的一个杰出特性是:它不需要时间片概念,至少不需要传统的时间片。经典的调度器对系统中的进程分别计算时间片,使进程运行直至时间片用尽。在所有进程的所有时间片都已经用尽时,则需要重新计算。相比之下,Linux 的调度器只考虑进程的等待时间,即进程在就绪队列(run-queue)中已经等待了多长时间。对 CPU 时间需求最严格的进程被调度执行。
我们可以把等待时间视为一种不公平因素,等待时间越长越不公平,而依次轮流运行很难解决该问题。所以需要考虑等待时间的调度策略
计算密集型和 I/O 密集型进程
计算密集型:是指程序的执行主要依赖于 CPU 的计算能力,而不是 I/O 的读写速度。计算密集型的任务通常包含大量的复杂运算和逻辑判断,比如数据分析、图像处理、机器学习等。从系统响应速度考虑,调度器不应该经常让它们运行,也就是降低其优先级。
I/O 密集型:也叫做输入输出密集型,指的是程序的执行主要依赖于 I/O 设备(如硬盘、内存、网络)的读写速度,而不是 CPU 的计算能力。I/O 密集型的任务通常包含大量的文件操作、网络请求、数据库访问等。一般交互型的程序如 GUI 程序,也属于 I/O 密集型,因为它需要等待用户输入,所以为了用户体验,一般要提高其优先级。但 I/O 密集型对 CPU 的依赖不高,这类进程被调度后可能就很短的时间就又去等待 I/O 了,这会导致频繁的进程切换而浪费 CPU。
分类并不是绝对的,同一个进程在不同的时刻其特性也有可能不同。
调度策略通常要在两个矛盾的目标中间寻找平衡:提高响应速度(提高 I/O 密集型优先级)和提高 CPU 利用率(提高计算密集型优先级)。
进程优先级
进程按优先级可分为硬实时进程、软实时进程、普通进程。
硬实时进程
有严格的时间限制,某些任务必须在指定的时限内完成。
实时操作系统就是用来做这件事的,Linux 并非实时操作系统,不支持硬实时进程。Linux 是针对吞吐量优化的,试图尽快地处理常见情形,其实很难实现可保证的响应时间。
软实时进程
硬实时进程的一种弱化形式。尽管仍然需要快速得到结果,但稍微晚一点也能接受
普通进程
没有特定时间约束,但仍然可以根据重要性来分配优先级。
Linux 采用了两种不同的优先级范围:
- nice 值:用于表示非实时进程的优先级,它的范围是从-20 到+19,默认值为 0;越大的 nice 值意味着更低的优先级
- 实时优先级:默认情况下它的变化范围是从 0 到 99。这是为了处理实时进程(Linux 支持软实时进程),实时进程(无论实时优先级值大小)总是优先于普通进程(无实时优先级)。
nice 值与实时优先级属于两个体系,并无直接关系。
调度相关数据结构
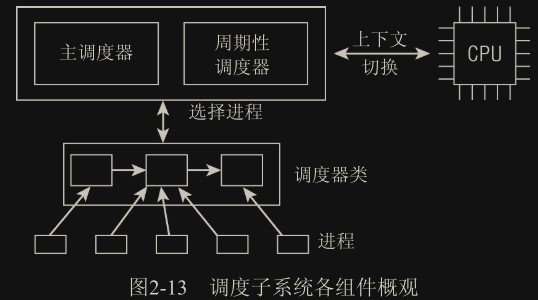
如图所示可以用两种方法激活调度:
- 主调度器(generic scheduler):直接的,比如进程打算睡眠或出于其他原因
放弃CPU; - 核心调度器(core scheduler):通过周期性机制,以固定的频率运行,不时检测是否有必要进行进程切换。
在调度器被调用时,它会查询调度器类,得知接下来运行哪个进程。内核支持不同的调度策略(完全公平调度、实时调度、在无事可做时调度空闲进程等),每种策略对应一个调度器类。每个进程都只属于某一调度器类,各个调度器类负责管理所属的进程。
在选中将要运行的进程之后,必须执行底层任务切换。这需要与 CPU 的紧密交互。
task_struct 的成员
task_struct 中与调度相关的部分:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
// <sched.h>
struct task_struct
{
...
int prio, static_prio, normal_prio;
unsigned int rt_priority;
struct list_head run_list;
const struct sched_class *sched_class;
struct sched_entity se;
unsigned int policy;
cpumask_t cpus_allowed;
unsigned int time_slice;
...
}
- prio, static_prio, normal_prio 优先级,静态优先级和普通优先级。静态优先级是进程启动时分配的优先级。normal_priority 表示基于进程的静态优先级和调度策略计算出的优先级。调度器考虑的优先级则保存在 prio
- rt_priority 表示实时进程的实时优先级。0-99,值越大,表明优先级越高。
- sched_class 表示该进程所属的调度器类。
- se 调度器不限于调度进程,还可以处理更大的实体(entity)。这个实体可以是进程组,也就是多个进程的集合,然后再在组内自行调度每个进程。所以调度器实际上调度的是一个
实体(sched_entity 结构实例),为了调度单进程,需要在 task_struct 结构内加上 sched_entity 结构将其视为一个实体 - policy 保存了对该进程应用的调度策略。Linux 支持 5 个可能的值,和 sched_class 关联的调度器类有关
- SCHED_NORMAL 用于普通进程,通过完全公平调度器来处理
- SCHED_BATCH 用于非交互、CPU 密集型的批处理进程。权重较低。
- SCHED_IDLE 进程的重要性也比较低,相对权重最小(注意这个不是空闲进程的意思)
- SCHED_RR 和 SCHED_FIFO 用于实现软实时进程。SCHED_RR 实现了一种循环方法,而 SCHED_FIFO 则使用先进先出机制。这类进程不是由完全公平调度器类处理,而是由实时调度器类处理,
- cpus_allowed 是一个位域,在多处理器系统上使用,用来限制进程可以在哪些 CPU 上运行。
- run_list 和 time_slice 是循环实时调度器所需要的,不用于完全公平调度器。run_list 是一个表头,用于维护包含各进程的一个运行表,而 time_slice 则指定进程可使用 CPU 的剩余时间段。
调度器类
目前 Linux 提供以下调度器类:
- Completely Fair Scheduler (CFS):CFS 是 Linux 内核默认的调度器,采用红黑树数据结构来维护进程队列,并根据进程的优先级和时间片大小来进行进程调度。
- Real-time Scheduler (RT):Real-time Scheduler 是 Linux 内核提供的实时调度器,可用于需要满足硬实时性要求的应用程序。它提供了多种调度策略,如 FIFO、RR 和 Deadline 等。
- Deadline Scheduler:Deadline Scheduler 是一种基于 Deadline 的调度器,可以确保任务在其截止时间之前完成。它适用于嵌入式和实时系统中的任务调度。它可以让 Linux 的实时性能得到显著的提升,但是并不能完全将 Linux 变成硬实时操作系统。
本文介绍其中最常用的 CFS 和实时调度器类。
sched_class 结构提供了通用调度器和各个调度方法之间的关联:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
// <sched.h>
struct sched_class
{
// 各个调度器类构成单向链表,见上图
const struct sched_class *next;
// 进程加入就绪队列
void (*enqueue_task)(struct rq *rq, struct task_struct *p, int wakeup);
// 从就绪队列删除进程
void (*dequeue_task)(struct rq *rq, struct task_struct *p, int sleep);
// 进程主动放弃CPU时该函数被内核调用
void (*yield_task)(struct rq *rq);
// 用一个新唤醒的进程来抢占当前进程
void (*check_preempt_curr)(struct rq *rq, struct task_struct *p);
// 选择下一个将要运行的进程
struct task_struct *(*pick_next_task)(struct rq *rq);
// 用另一个进程代替当前运行的进程之前调用
void (*put_prev_task)(struct rq *rq, struct task_struct *p);
// 在进程的调度策略发生变化时调用
void (*set_curr_task)(struct rq *rq);
// 在每次激活周期性调度器时,由周期性调度器调用。
void (*task_tick)(struct rq *rq, struct task_struct *p);
// 用于建立fork系统调用和调度器之间的关联。每次新进程建立后,则用new_task 通知调度器。
void (*task_new)(struct rq *rq, struct task_struct *p);
};
用户层应用程序无法直接与调度器类交互。它们只知道自己的 policy(上一节提到的,如SCHED_NORMAL),也就是自己属于哪类进程(具体由哪个调度器类处理无法得知)。
内核负责将这些常量和可用的调度器类之间提供适当的映射。
fair_sched_class(CFS 类):SCHED_NORMAL、SCHED_BATCH和SCHED_IDLErt_sched_class(实时调度器类):SCHED_RR和SCHED_FIFO
fair_sched_class 和 rt_sched_class 都是 struct sched_class 的实例,分别表示完全公平调度器类和实时调度器类。
1
2
3
4
5
// kernel/sched/sched.h
extern const struct sched_class stop_sched_class;
extern const struct sched_class rt_sched_class;
extern const struct sched_class fair_sched_class;
extern const struct sched_class idle_sched_class;
1
2
3
4
5
6
7
8
9
10
11
// kernel/sched/fair.c
const struct sched_class fair_sched_class = {
.next = &idle_sched_class,
.enqueue_task = enqueue_task_fair,
.dequeue_task = dequeue_task_fair,
.yield_task = yield_task_fair,
.yield_to_task = yield_to_task_fair,
.check_preempt_curr = check_preempt_wakeup,
...
}
就绪队列
各个 CPU 都有自身的就绪队列,对应 struct rq,各个活动进程只出现在一个就绪队列中。
进程并不是由就绪队列的成员直接管理的,而是由各个调度器类分别管理,因此在各个就绪队列中嵌入了特定于调度器类的子就绪队列。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
// kernel/sched/sched.h
struct rq
{
// 队列上可运行进程的数目(包括了正在运行的)
unsigned long nr_running;
#define CPU_LOAD_IDX_MAX 5
...
// 跟踪历史负荷状态(load变量),数组大小为5表示存储最近5次的load值
unsigned long cpu_load[CPU_LOAD_IDX_MAX];
// 就绪队列当前负荷的度量,负荷算法后面介绍
struct load_weight load;
// 嵌入的子就绪队列(完全公平调度器)
struct cfs_rq cfs;
// 嵌入的子就绪队列(实时调度器)
struct rt_rq rt;
// curr 指向当前运行的进程的task_struct实例
// idle 指向idle进程的task_struct实例
struct task_struct *curr, *idle;
// clock表示CPU启动后经过的时间,以纳秒为单位。每次调用周期性调度器时,都会更新clock的值
u64 clock;
...
};
系统的所有就绪队列都在 runqueues 数组中,该数组的每个元素分别对应于系统中的一个 CPU。在单处理器系统中,由于只需要一个就绪队列,数组只有一个元素:
1
2
// kernel/sched/sched.h
DECLARE_PER_CPU(struct rq, runqueues);
对于该变量的定义用到了
DECLARE_PER_CPU宏,可见编译时的每个 CPU 数据
发源于同一进程的各线程可以在不同处理器上执行,因为进程管理对进程和线程不作重要的区分。
调度实体
调度器操作的是比进程描述符更通用的调度实体(sched_entity),而非 task_struct 结构。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
// include/linux/sched.h
struct sched_entity {
struct load_weight load; /* for load-balancing */
// 红黑树节点
struct rb_node run_node;
struct list_head group_node;
// 该实体当前是否在就绪队列上接受调度
unsigned int on_rq;
// 在进程运行时,我们需要记录消耗的CPU时间,以用于完全公平调度器。
// 进程开始运行时间(一个运行周期内,被调度切换进程时清空)
u64 exec_start;
// 进程总物理运行时间(进程总生命周期,一个运行周期结束不重置),
// 通过当前时间减去exec_start获得(分段累计,防止exec_start的清空)
u64 sum_exec_runtime;
// 进程总虚拟运行时间(类似sum_exec_runtime)
u64 vruntime;
// 上个运行周期结束sum_exec_runtime的值
u64 prev_sum_exec_runtime;
u64 nr_migrations;
#ifdef CONFIG_SCHEDSTATS
struct sched_statistics statistics;
#endif
#ifdef CONFIG_FAIR_GROUP_SCHED
struct sched_entity *parent;
/* rq on which this entity is (to be) queued: */
struct cfs_rq *cfs_rq;
/* rq "owned" by this entity/group: */
struct cfs_rq *my_q;
#endif
/*
* Load-tracking only depends on SMP, FAIR_GROUP_SCHED dependency below may be
* removed when useful for applications beyond shares distribution (e.g.
* load-balance).
*/
#if defined(CONFIG_SMP) && defined(CONFIG_FAIR_GROUP_SCHED)
/* Per-entity load-tracking */
struct sched_avg avg;
#endif
};
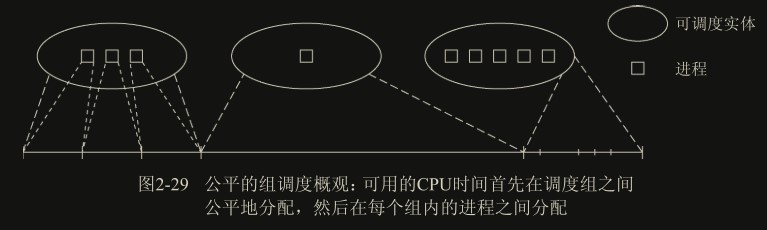
每个 task_struct 都嵌入了一个 sched_entity 成员,以便其可以被调度器调度。多个进程可以合并为调度组,由同一个调度实体管理(组调度),通过启用CONFIG_FAIR_GROUP_SCHED实现:
处理优先级
Linux 中的 nice 值表示进程的友好度,范围为[-20,+19],越高越友好,表示其更愿意让出 CPU,相反越低表示其越“吝啬”和严格。
nice 值是优先级和权重的基础,Linux 会根据 nice 值计算各进程的优先级和权重。
优先级的内核表示
在用户空间可以通过 nice 命令设置进程的静态优先级,这在内部会调用 nice 系统调用。进程的 nice 值在 -20 和+19 之间(包含)。值越低,表明优先级越高。
内核使用一个简单些的数值范围,从 0 到 139(包含),用来表示内部优先级,整合了实时和非实时进程的优先级。同样是值越低,优先级越高。从 0 到 99 的范围专供实时进程使用。nice 值[-20, +19]映射到范围 100 到 139,如图 2-14 所示。 实时进程的优先级总是比普通进程更高。

1
2
3
4
5
6
7
8
9
// <sched.h>
#define MAX_USER_RT_PRIO 100
#define MAX_RT_PRIO MAX_USER_RT_PRIO
#define MAX_PRIO (MAX_RT_PRIO + 40)
#define DEFAULT_PRIO (MAX_RT_PRIO + 20)
// kernel/sched.c
#define NICE_TO_PRIO(nice) (MAX_RT_PRIO + (nice) + 20)
#define PRIO_TO_NICE(prio) ((prio) -MAX_RT_PRIO -20)
#define TASK_NICE(p) PRIO_TO_NICE((p)->static_prio)
计算优先级
- 动态优先级(task_struct->prio)
- 普通优先级(task_struct->normal_prio)
- 静态优先级(task_struct->static_prio)
这些优先级按有趣的方式彼此关联,动态优先级和普通优先级通过静态优先级计算而来:
1
p->prio = effective_prio(p);
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
// kernel/sched.c
// 计算动态优先级
static int effective_prio(struct task_struct *p)
{
// 计算普通优先级
p->normal_prio = normal_prio(p);
if (!rt_prio(p->prio))
// 如果不是实时进程,返回普通优先级(会赋值给p->prio)
return p->normal_prio;
/* 如果是实时进程(或是临时提高至实时优先级的普通进程),则保持优先级不变。*/
return p->prio;
}
// kernel/sched.c
// 计算普通优先级
static inline int normal_prio(struct task_struct *p)
{
int prio;
// 如果是实时进程
if (task_has_rt_policy(p))
// 利用task_struct中的rt_priority
// rt_priority是个独立的用于表示实时优先度的变量,越高优先度越高
// 由于该优先度表示和内核优先级相反(内核是越小越高),
// 需要用减法做处理
prio = MAX_RT_PRIO - 1 - p->rt_priority;
// 如果是普通进程
else
prio = __normal_prio(p);
return prio;
}
// kernel/sched.c
static inline int __normal_prio(struct task_struct *p)
{
// 如果是普通进程,直接让normal优先级和static相同
return p->static_prio;
}
对各种类型的进程计算优先级结果:
| 进程类型/优先级 | static_prio | normal_prio | prio |
|---|---|---|---|
| 非实时进程(全相同) | static_prio | static_prio | static_prio |
| 优先级提高的非实时进程 | static_prio | static_prio | prio 不变 |
| 实时进程 | static_prio | MAX_RT_PRIO-1-rt_priority | prio 不变 |
从上表可知,内核允许让非实时进程通过修改 prio 的值来临时上升为实时进程优先级,prio 值除非被单独修改否则后续不会受到 static_prio 的影响(比如用 nice 修改 static_prio)。
在进程分支出子进程时,子进程的静态优先级继承自父进程。子进程的动态优先级,即 task_struct->prio,则设置为父进程的普通优先级。这确保了实时互斥量引起的优先级提高不会传递到子进程。
计算负荷权重
进程的重要性不仅由优先级决定,还需要考虑权重(保存在 task_struct->se.load)。Linux 调度器类会根据优先级和权重共同计算下个要调度的进程,以及其可占用的 CPU 时间。
1
2
3
4
5
// <sched.h>
struct load_weight
{
unsigned long weight, inv_weight;
};
set_load_weight() 函数负责根据进程类型及其静态优先级计算权重。内核不仅维护了权重自身(weight),而且还有另一个数值(inv_weight),用于表示权重倒数(1/weight)。
一般概念是这样,进程每降低一个 nice 值,则多获得 10% 的 CPU 时间,每升高一个 nice 值,则放弃 10% 的 CPU 时间。为执行该策略,内核将优先级转换为权重值。我们首先看一下转换表:
1
2
3
4
5
6
7
8
9
10
11
// kernel/sched.c
static const int prio_to_weight[40] = {
/* -20 */ 88761, 71755, 56483, 46273, 36291,
/* -15 */ 29154, 23254, 18705, 14949, 11916,
/* -10 */ 9548, 7620, 6100, 4904, 3906,
/* -5 */ 3121, 2501, 1991, 1586, 1277,
/* 0 */ 1024, 820, 655, 526, 423,
/* 5 */ 335, 272, 215, 172, 137,
/* 10 */ 110, 87, 70, 56, 45,
/* 15 */ 36, 29, 23, 18, 15,
};
对内核使用的范围[-20, +15]中的每个 nice 级别,该数组中都有一个对应项(映射到 0-39)。数组各项间的乘数因子是 1.25(index项 是 index+1项 的 1.25 倍,这是为了上面说的增加 nice 值带来的 10% CPU 时间提升)。
两个进程 A 和 B 在 nice 级别 0 运行,因此两个进程的 CPU 份额相同,即都是 50%。nice 级别为 0 的进程,其权重查表可知为 1024。每个进程的份额是 1024/(1024+1024)=0.5,即 50%。如果进程 B 的优先级值加 1(优先级降低),那么其 CPU 份额应该减少 10%。换句话说,这意味着进程 A 得到总的 CPU 时间的 55%,而进程 B 得到 45%。优先级增加 1 导致权重减少,即 1024/1.25≈820。因此进程 A 现在将得到的 CPU 份额是 1024/(1024+820)≈0.55(数学中标准权重占比计算方式),而进程 B 的份额则是 820/(1024+820)≈0.45,这样就产生了 10% 的差值。
执行转换的代码也需要考虑实时进程。实时进程的权重至少是普通进程的两倍,而SCHED_IDLE类型的空闲进程的权重总是非常小:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
// kernel/sched.c
#define WEIGHT_IDLEPRIO 2
#define WMULT_IDLEPRIO (1 << 31)
static void
set_load_weight(struct task_struct *p)
{
// 如果是实时进程
if (task_has_rt_policy(p))
{
// 权重总是最大值,且需要翻个倍
p->se.load.weight = prio_to_weight[0] * 2;
// 计算倒数,保存到inv_weight
p->se.load.inv_weight = prio_to_wmult[0] >> 1;
return;
}
/** SCHED_IDLE进程得到的权重最小:
*/
if (p->policy == SCHED_IDLE)
{
p->se.load.weight = WEIGHT_IDLEPRIO;
p->se.load.inv_weight = WMULT_IDLEPRIO;
return;
}
// 如果是非实时普通进程
p->se.load.weight = prio_to_weight[p->static_prio - MAX_RT_PRIO];
p->se.load.inv_weight = prio_to_wmult[p->static_prio - MAX_RT_PRIO];
}
计算负荷
在 Linux 系统中,系统负荷(system load) 是指的是在给定时刻的可运行状态(TASK_RUNNING) 和 不可中断状态(TASK_UNINTERRUPTIBLE) 的进程数量,处于空闲状态时为 0。
一般使用一段时间内的 平均系统负荷(load average) 来表示系统运行情况(下面例子是单核 CPU 的情况):
- 当平均负荷小于 1 时,表示这段时间 CPU 不仅能处理所有进程,还有部分时间处于没有进程运行的空闲状态,也就是说这段时间内所有的进程都得到了所需的 CPU 时间;
- 当平均负荷大于 1 时,表示肯定有部分进程没有获得所需的 CPU 时间;
- 如果持续过高,表示有部分进程长时间处于饥饿状态。
系统负荷和 CPU 使用率并无直接关系,高负荷也有可能是过多的 I/O 导致的(占用 CPU 时间片但并实际是在忙等待,忙等待一般采取休眠 CPU 并轮询的方式,持续占用 CPU 但 CPU 使用率并不高)。可以说系统负荷表示 CPU 时间的占用率,具体进程占用时间片用于什么目的才能决定 CPU 的使用率。
不同 CPU 指令的消耗
当 CPU 执行指令时,会产生电流和功率消耗。一些指令需要更多的电流和功率,因此会产生更多的热量。例如,浮点数运算、乘法和除法等指令需要更多的电流和功率,因此会产生更多的热量,而移位、逻辑运算等指令则需要更少的电流和功率,因此产生的热量也相对较少。而 空指令(NOP) 仅占用 CPU 时间,不执行任何操作,几乎不消耗额外资源。
之前在就绪队列一节提到就绪队列 rq 中有一个 load,表示负荷值。它和系统负荷相关,但它并不表示系统负荷(system load),真正的系统负荷需要结合调度策略等共同计算。
每次进程被加到就绪队列时,内核会调用 inc_nr_running 添加该负荷:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
// kernel/sched.c
static inline void update_load_add(struct load_weight *lw, unsigned long inc)
{
lw->weight += inc;
}
static inline void inc_load(struct rq *rq, const struct task_struct *p)
{
update_load_add(&rq->load, p->se.load.weight);
}
static void inc_nr_running(struct task_struct *p, struct rq *rq)
{
rq->nr_running++;
inc_load(rq, p);
}
核心调度器
调度器的实现基于两个函数:
- 周期性调度器函数
- 主调度器函数
周期性调度器
周期性调度器函数 scheduler_tick()在每个 CPU ticks 调用一次,该函数有下面两个主要任务:
- (1) 管理内核中与整个系统和各个进程的调度相关的统计量。其间执行的主要操作是对各种
计数器加 1。 - (2) 激活负责当前进程的调度类的周期性调度方法(
task_tick钩子)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
void scheduler_tick(void)
{
// 当前 CPU
int cpu = smp_processor_id();
// 当前CPU的就绪队列
struct rq *rq = cpu_rq(cpu);
// 当前运行的进程
struct task_struct *curr = rq->curr;
sched_clock_tick();
raw_spin_lock(&rq->lock);
// 处理就绪队列时钟的更新,也就是clock成员
update_rq_clock(rq);
// 更新cpu_load[]数组,保存历史负荷值
update_cpu_load_active(rq);
// 调用进程对应的的调度器类实例的方法
curr->sched_class->task_tick(rq, curr, 0);
raw_spin_unlock(&rq->lock);
perf_event_task_tick();
#ifdef CONFIG_SMP
rq->idle_balance = idle_cpu(cpu);
// SMP相关,触发CPU负载均衡,软中断实现
trigger_load_balance(rq, cpu);
#endif
rq_last_tick_reset(rq);
}
task_tick 的实现方式取决于底层的调度器类。例如,完全公平调度器会在该方法中检测是否进程已经运行太长时间,以避免过长的延迟。(这里就是和时间片轮转不同的地方,完全公平调度器会实时检测进程的运行的时长而动态调整调度它的时间,而不是死板的进程开始就确定只能运行多长时间片)
如果当前进程应该被重新调度(还没执行结束就被抢占了),那么调度器类方法会在 task_struct 中设置 TIF_NEED_RESCHED 标志(需要调度标志),而内核会在接下来的适当时机完成该请求。
也就是说周期性调度器并不负责执行调度过程,只是设置应该调度的标志,后续会由内核在合适的时候调用主调度器schedule()根据标志执行调度。(一般来说内核会在定时中断返回用户空间前执行一次schedule(),给了一次调度的机会)
主调度器
在内核中的许多地方,如果要将 CPU 分配给与当前活动进程不同的另一个进程(切换进程),都会直接调用主调度器函数(schedule)。在从系统调用返回之后(如果支持内核抢占,中断返回后也会检测一次),内核也会检查当前进程是否设置了重调度标志 TIF_NEED_RESCHED,例如,前述的 scheduler_tick 就会设置该标志,标志置位时内核会调用 schedule()。
会调用 schedule 的函数模板必须有 __sched 前缀:
1
2
3
4
5
void __sched some_function(...) {
...
schedule();
...
}
__sched 前缀:该前缀用于所有可能调用 schedule 的函数, 包括 schedule 自身。该前缀目的在于,将相关函数的代码编译之后,放到目标文件的一个特定的段中,即.sched.text 中。该信息使得内核在显示栈转储或类似信息时,忽略所有与调度有关的调用。由于调度器函数调用不是普通代码流程的一部分,因此在这种情况下这些信息和被调度的进程是没有关系的。
schedule() 的实现:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
// kernel/sched/core.c
static void __sched __schedule(void)
{
struct task_struct *prev, *next;
unsigned long *switch_count;
struct rq *rq;
int cpu;
need_resched:
// 关闭内核抢占
preempt_disable();
cpu = smp_processor_id();
// 获取当前CPU就绪队列
rq = cpu_rq(cpu);
rcu_note_context_switch(cpu);
prev = rq->curr;
schedule_debug(prev);
if (sched_feat(HRTICK))
hrtick_clear(rq);
/*
* Make sure that signal_pending_state()->signal_pending() below
* can't be reordered with __set_current_state(TASK_INTERRUPTIBLE)
* done by the caller to avoid the race with signal_wake_up().
*/
smp_mb__before_spinlock();
// 锁定rq
raw_spin_lock_irq(&rq->lock);
switch_count = &prev->nivcsw;
/*
* 如果state为TASK_RUNNING(0)或是抢占计数器设置了PREEMPT_ACTIVE
* 表示本次调度由抢占触发,也就是被更高优先级进程强制抢占。判断条件
* 失败,跳过该分支
* 如果不为TASK_RUNNING且调度不是由抢占触发的,表示可能是
* 主动进入休眠了,比如等待I/O等,此时就要进入分支停用该
* 进程(deactivate_task)
*/
if (prev->state && !(preempt_count() & PREEMPT_ACTIVE)) {
/*
* 如果当前进程prev处于可中断睡眠状态TASK_INTERRUPTIBLE
* (一般进程主动休眠前都会将自己的状态置为TASK_INTERRUPTIBLE),
* 判断当前是否有唤醒信号。这样如果进程刚休眠就收到唤醒信号,
* 就能及时重新运行(如果优先级还是最高),也免去了调度的消耗。
*/
if (unlikely(signal_pending_state(prev->state, prev))) {
// 当前进程置为可运行状态
prev->state = TASK_RUNNING;
} else {
// 否则将其移出调度器类的队列
deactivate_task(rq, prev, DEQUEUE_SLEEP);
prev->on_rq = 0;
/*
* If a worker went to sleep, notify and ask workqueue
* whether it wants to wake up a task to maintain
* concurrency.
*/
// 一个工作者休眠,尝试唤醒工作队列中另一个工作者
if (prev->flags & PF_WQ_WORKER) {
struct task_struct *to_wakeup;
to_wakeup = wq_worker_sleeping(prev, cpu);
if (to_wakeup)
try_to_wake_up_local(to_wakeup);
}
}
switch_count = &prev->nvcsw;
}
pre_schedule(rq, prev);
if (unlikely(!rq->nr_running))
idle_balance(cpu, rq);
/**
* put_prev_task首先通知调度器类当前运行的进程将要被另一个进程代替。
* 提供了一个时机,供执行一些簿记工作并更新统计量。
* 在完全公平调度器类中,如果进程是运行中的(不是主动休眠),
* 相关钩子函数会更新进程的vruntime(update_curr),
* 注意进程在运行时不在红黑树上,然后该操作会在更新完vruntime后将进程
* 放回红黑树中,此时进程算是重回就绪队列,等待下次调度
*/
put_prev_task(rq, prev);
// 核心步骤:调度类选择下一个应该执行的进程,
// 比如CFS会从红黑树中寻找最左边节点对应的进程
next = pick_next_task(rq);
// 清除当前运行进程task_struct中的重调度标志TIF_NEED_RESCHED。
clear_tsk_need_resched(prev);
rq->skip_clock_update = 0;
// 如果next不为prev,表示需要进程切换
if (likely(prev != next)) {
rq->nr_switches++;
rq->curr = next;
++*switch_count;
// 切换上下文,在过程中进程将停止运行,直到再次被调度时该函数返回
// (该操作同时会解锁rq)
context_switch(rq, prev, next); /* unlocks the rq */
/*
* The context switch have flipped the stack from under us
* and restored the local variables which were saved when
* this task called schedule() in the past. prev == current
* is still correct, but it can be moved to another cpu/rq.
*/
// 进程再次运行时,可能不在之前的CPU上了,需要重新定位
cpu = smp_processor_id();
// 获取当前的rq
rq = cpu_rq(cpu);
} else
// 解锁rq
raw_spin_unlock_irq(&rq->lock);
// 如果可行,将当前进程重新加入队列
post_schedule(rq);
// 重新开启内核抢占
sched_preempt_enable_no_resched();
/* 再次检测TIF_NEED_RESCHED标志,如果进程又需要被重新调度,
* 可以及时处理,不用返回用户空间等待下次调度。
* TODO:一般发生在什么时候?可能的情况是进程在休眠期间自己的
* TIF_NEED_RESCHED又被其他进程置位了
*/
if (need_resched())
goto need_resched;
}
核心步骤选择下一个运行的进程pick_next_task:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
// kernel/sched/core.c
static inline struct task_struct *
pick_next_task(struct rq *rq)
{
const struct sched_class *class;
struct task_struct *p;
/*
* Optimization: we know that if all tasks are in
* the fair class we can call that function directly:
*/
// 如果整个就绪队列长度等于CFS就绪队列长度,
// 说明整个就绪队列都是CFS管理的进程,直接使用CFS的pick_next_task方法
if (likely(rq->nr_running == rq->cfs.h_nr_running)) {
p = fair_sched_class.pick_next_task(rq);
if (likely(p))
return p;
}
// 依次遍历所有调度器类,首先是实时调度器类,实时进程总是被优先调度
for_each_class(class) {
p = class->pick_next_task(rq);
if (p)
return p;
}
BUG(); /* the idle class will always have a runnable task */
}
主调度器的触发时机
- 内核抢占,详见内核抢占的触发时机
- 进程阻塞,主动放弃 CPU
在内核中耗时较长的函数中见缝插针(比如每个循环中)的触发,这会使用到
cond_resched()(其实很像preempt_schedule()):1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20
static inline int should_resched(void) { return need_resched() && !(preempt_count() & PREEMPT_ACTIVE); } static void __cond_resched(void) { add_preempt_count(PREEMPT_ACTIVE); __schedule(); sub_preempt_count(PREEMPT_ACTIVE); } int __sched _cond_resched(void) { if (should_resched()) { __cond_resched(); return 1; } return 0; }
即使没有显式内核抢占,这也能够保证较高的响应速度。
与 fork 的交互
每当使用 fork 系统调用或其变体之一建立新进程时,会执行调度器对应的 sched_fork 函数,为进程初始化调度相关信息。在单处理器系统上,该函数实质上执行 3 个操作:
- 初始化新进程与调度相关的字段
- 建立数据结构(相当简单直接)
- 确定进程的动态优先级
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
// kernel/sched.c
/* * fork()/clone()时的设置: */
void sched_fork(struct task_struct *p, int clone_flags)
{
/* 初始化数据结构 */
...
/** 确认没有将提高的优先级泄漏到子进程 */
// 使用父进程的normal_prio,具体含义见上面讲过的优先级介绍
p->prio = current->normal_prio;
// 如果是非实时进程
if (!rt_prio(p->prio))
// 用完全公平调度器
p->sched_class = &fair_sched_class;
...
}
在使用 wake_up_new_task 唤醒新进程时(上文有提到),则是调度器与进程创建逻辑交互的第二个时机:内核会调用调度类的 task_new 函数。这提供了一个时机,将新进程加入到相应类的就绪队列中。
上下文切换
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
// kernel/sched/core.c
static inline void
context_switch(struct rq *rq, struct task_struct *prev, struct task_struct *next)
{
struct mm_struct *mm, *oldmm;
// prepare_task_switch会调用每个体系结构都必须定义的prepare_arch_switch函数
prepare_task_switch(rq, prev, next);
// mm_struct为内存管理上下文结构,主要包括加载页表、刷出地址转换后备缓冲器(部分或全部)、向内存管理单元(MMU)提供新的信息。
mm = next->mm;
oldmm = prev->active_mm;
arch_start_context_switch(prev);
// 内核线程没有自己的用户空间内存上下文,可能在某个随机进程地址空间的上部执行,可见上文。
// 其task_struct->mm为NULL。从当前进程“借来”的地址空间记录在active_mm中:
if (unlikely(!mm))
{// !mm表示mm为空,也就是说是内核线程
// 每次都借上一个用户进程的地址空间,内核线程使用匿名地址空间
next->active_mm = oldmm;
// 增加该内存描述符引用计数
atomic_inc(&oldmm->mm_count);
// 由于内核线程实际并不会使用任何用户进程地址空间
// 所以通知内核无需切换页表。借用只是形式上借用下
enter_lazy_tlb(oldmm, next);
}
else
// 实际切换mm
switch_mm(oldmm, mm, next);
// 如果当前进程是内核线程
if (unlikely(!prev->mm))
{
// 取消对借用的地址空间的借用
prev->active_mm = NULL;
rq->prev_mm = oldmm;
}
#ifndef __ARCH_WANT_UNLOCKED_CTXSW
spin_release(&rq->lock.dep_map, 1, _THIS_IP_);
#endif
context_tracking_task_switch(prev, next);
/* 这里我们只是切换寄存器状态和栈。注意这里的三个参数,后面介绍 */
switch_to(prev, next, prev);
// switch_to之后的代码只有在当前进程下一次被选择运行时才会执行。
// switch_to返回后,prev将会是最后一次切换前的进程
// barrier语句是一个编译器指令,确保switch_to和finish_task_switch语句的执行顺序不会因为任何可能的优化而改变
barrier();
/*
* finish_task_switch完成一些清理工作,使得能够正确地释放锁,
* this_rq必须重新计算,因为在调用schedule()之后本进程可能已经移动到其他CPU,
* 此时其栈帧上的rq是无效的。
* prev就是实际上一个运行的进程,后面有提到
*/
finish_task_switch(this_rq(), prev);
}
用户空间进程的寄存器内容在进入内核态时由硬件自动保存在内核栈上,在上下文切换期间无需显式操作。每个用户进程都是从switch_to后开始执行,此时还处于内核态,所以所有用户进程都是从内核态开始执行的(之后会切换到用户态),在返回用户空间时,会使用内核栈上保存的值自动恢复寄存器数据
switch_to() 的复杂之处:
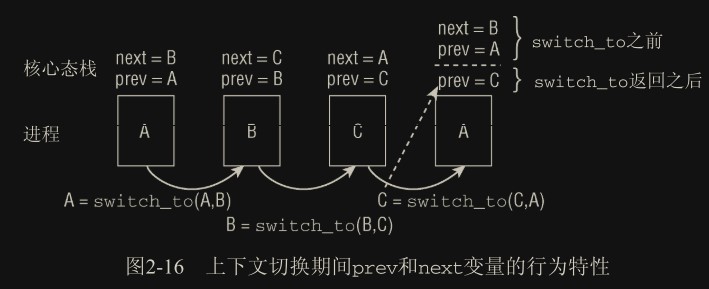
进程 A 切 B,再切 C,最后切 A,A 被恢复执行时,switch_to 返回后,它的栈被恢复,此时它认为的 prev 还是 A,next 还是 B,就是第一次调度时保存下来的栈。在这种情况下,内核无法知道实际上在进程 A 之前运行的是进程 C。因此,在新进程被选中时,底层的进程切换例程必须将此前执行的进程提供给 context_switch。
switch_to 宏实际上执行的代码如下:
1
prev = switch_to(prev,next)
通过这个方式,内核可以用实际的 switch_to 函数的返回值为恢复的栈提供实际的 prev 值。这个过程依赖底层的体系结构,也就是内核需要有能力控制这两个栈。
惰性 FPU 模式:
上下文切换时一般会把当前进程用到的寄存器压栈,然后从需要执行的进程的栈中恢复寄存器。但浮点计算寄存器(FPU)由于很少使用且每次保存恢复的开销较大,就有了惰性 FPU 模式,也就是上下文切换期间默认不去操作该寄存器(假定新的进程不会去操作该寄存器),直到进程第一次使用该寄存器时将原有的值压入最后一次使用的进程的栈中。
现代 CPU 为 FPU context 切换进行了优化,所以 save/restore 的开销不再是一个问题。
休眠和唤醒
进程休眠肯定是为了等待一些事件,如文件 I/O、等待键盘输入等。
休眠有两种相关的进程状态:TASK_INTERRUPTIBLE和TASK_UNINTERRUPTIBLE,见state。
进程休眠时离开就绪队列进入等待队列,如果是 CFS 策略,则从红黑树中移出。
休眠通过等待队列进行,数据结构为进程组成的链表。休眠的实现可能会有竞争条件:condition 为真后进程却进入了休眠,导致永远无法被唤醒。以下实现可以规避该问题:
1
2
3
4
5
6
7
8
9
10
11
12
#define __wait_event(wq, condition) \
do { \
DEFINE_WAIT(__wait); \
\
for (;;) { \
prepare_to_wait(&wq, &__wait, TASK_UNINTERRUPTIBLE); \
if (condition) \
break; \
schedule(); \
} \
finish_wait(&wq, &__wait); \
} while (0)
伪唤醒:有时进程被唤醒并不是其等待的条件满足了,而是收到了其他事件被唤醒(比如被信号唤醒,或和其他进程处于同一个等待队列时被同步唤醒),所以每次重新开始执行后需要再次判断条件。
此处的 while 循环和判断条件实际只是为了防止伪唤醒,也就是条件实际并未达成就被唤醒,就继续进入唤醒状态。正常唤醒情况下,条件肯定是满足的,可以简化为:
1
2
3
4
5
6
DEFINE_WAIT(wait); // 将本进程打包为wait_queue_t项
// 假设仅会在条件满足时被wakeup()唤醒
prepare_to_wait(&q, &wait, TASK_UNINTERRUPTIBLE);
if(!condition)
// 非预期错误
finish_wait(&q, &wait);
相关的函数:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
#define set_mb(var, value) do { var = value; mb(); } while (0)
#define set_current_state(state_value) \
set_mb(current->state, (state_value))
/*
* Note: we use "set_current_state()" _after_ the wait-queue add,
* because we need a memory barrier there on SMP, so that any
* wake-function that tests for the wait-queue being active
* will be guaranteed to see waitqueue addition _or_ subsequent
* tests in this thread will see the wakeup having taken place.
*
* The spin_unlock() itself is semi-permeable and only protects
* one way (it only protects stuff inside the critical region and
* stops them from bleeding out - it would still allow subsequent
* loads to move into the critical region).
*/
void
prepare_to_wait(wait_queue_head_t *q, wait_queue_t *wait, int state)
{
unsigned long flags;
wait->flags &= ~WQ_FLAG_EXCLUSIVE;
spin_lock_irqsave(&q->lock, flags); // 使用该接口使得其可在中断中使用
if (list_empty(&wait->task_list))
__add_wait_queue(q, wait);
// 若未保证原子性可能加入队列之后立即被唤醒(移出队列),
// 然后这步状态却是置为休眠,导致错过唤醒,永远休眠了
set_current_state(state);
spin_unlock_irqrestore(&q->lock, flags);
}
/*
* The core wakeup function. Non-exclusive wakeups (nr_exclusive == 0) just
* wake everything up. If it's an exclusive wakeup (nr_exclusive == small +ve
* number) then we wake all the non-exclusive tasks and one exclusive task.
*
* There are circumstances in which we can try to wake a task which has already
* started to run but is not in state TASK_RUNNING. try_to_wake_up() returns
* zero in this (rare) case, and we handle it by continuing to scan the queue.
*/
static void __wake_up_common(wait_queue_head_t *q, unsigned int mode,
int nr_exclusive, int wake_flags, void *key)
{
wait_queue_t *curr, *next;
list_for_each_entry_safe(curr, next, &q->task_list, task_list) {
unsigned flags = curr->flags;
if (curr->func(curr, mode, wake_flags, key) &&
(flags & WQ_FLAG_EXCLUSIVE) && !--nr_exclusive)
break;
}
}
#define wake_up(x) __wake_up(x, TASK_NORMAL, 1, NULL)
/**
* __wake_up - wake up threads blocked on a waitqueue.
* @q: the waitqueue
* @mode: which threads
* @nr_exclusive: how many wake-one or wake-many threads to wake up
* @key: is directly passed to the wakeup function
*
* It may be assumed that this function implies a write memory barrier before
* changing the task state if and only if any tasks are woken up.
*/
void __wake_up(wait_queue_head_t *q, unsigned int mode,
int nr_exclusive, void *key)
{
unsigned long flags;
spin_lock_irqsave(&q->lock, flags);
__wake_up_common(q, mode, nr_exclusive, 0, key);
spin_unlock_irqrestore(&q->lock, flags);
}
/**
* try_to_wake_up - wake up a thread
* @p: the thread to be awakened
* @state: the mask of task states that can be woken
* @wake_flags: wake modifier flags (WF_*)
*
* Put it on the run-queue if it's not already there. The "current"
* thread is always on the run-queue (except when the actual
* re-schedule is in progress), and as such you're allowed to do
* the simpler "current->state = TASK_RUNNING" to mark yourself
* runnable without the overhead of this.
*
* Returns %true if @p was woken up, %false if it was already running
* or @state didn't match @p's state.
*/
static int
try_to_wake_up(struct task_struct *p, unsigned int state, int wake_flags)
{
unsigned long flags;
int cpu, success = 0;
/*
* If we are going to wake up a thread waiting for CONDITION we
* need to ensure that CONDITION=1 done by the caller can not be
* reordered with p->state check below. This pairs with mb() in
* set_current_state() the waiting thread does.
*/
smp_mb__before_spinlock(); // 先设置一个屏障保证之前的赋值操作完成
raw_spin_lock_irqsave(&p->pi_lock, flags);
if (!(p->state & state))
goto out;
success = 1; /* we're going to change ->state */
cpu = task_cpu(p);
/*
* Ensure we load p->on_rq _after_ p->state, otherwise it would
* be possible to, falsely, observe p->on_rq == 0 and get stuck
* in smp_cond_load_acquire() below.
*
* sched_ttwu_pending() try_to_wake_up()
* [S] p->on_rq = 1; [L] P->state
* UNLOCK rq->lock -----.
* \
* +--- RMB
* schedule() /
* LOCK rq->lock -----'
* UNLOCK rq->lock
*
* [task p]
* [S] p->state = UNINTERRUPTIBLE [L] p->on_rq
*
* Pairs with the UNLOCK+LOCK on rq->lock from the
* last wakeup of our task and the schedule that got our task
* current.
*/
smp_rmb();
if (p->on_rq && ttwu_remote(p, wake_flags))
goto stat;
// (以下省略)
}
其中竞争条件(condition 的赋值和 condition 的读取顺序)的处理使用屏障的方式:
1
2
3
4
5
6
7
8
9
CPU 1 CPU 2
=============================== ===============================
// prepare_to_wait 内部实现 STORE event_indicated
set_current_state(); // wake_up 的实现
set_mb(); wake_up();
// 进程进入休眠态 <write barrier> // 写屏障,保证event_indicated已经写成功
STORE current->state STORE current->state // 进程进入就绪态
<general barrier> // 读写屏障,保证 event_indicated 的读取在写 state 后(等唤醒后执行)
LOAD event_indicated
通过 prepare_to_wait 内部(set_current_state)封装的一个读写屏障和 wake_up 内部封装的一个写屏障(可能和上面的内核代码不对应,但这是核心思想),保证了 CPU2 对 event_indicated 的修改一定在唤醒进程(修改state)前,且 CPU1 对 event_indicated 的读取一定在休眠之后(这点主要还是为了防止伪唤醒)。
唤醒操作可通过函数 wake_up()进行,它会唤醒指定的等待队列上的所有进程。它调用函数 try_to_wake_up(),该函数负责将进程设置为 TASK_RUNNING 状态。如果是 CFS 队列进程,还会调用 enqueue_task() 将此进程放入红黑树中。
内核代码实例:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
static ssize_t inotify_read(struct file *file, char __user *buf,
size_t count, loff_t *pos)
{
struct fsnotify_group *group;
struct fsnotify_event *kevent;
char __user *start;
int ret;
DEFINE_WAIT(wait);
start = buf;
group = file->private_data;
while (1) {
prepare_to_wait(&group->notification_waitq, &wait, TASK_INTERRUPTIBLE);
mutex_lock(&group->notification_mutex);
kevent = get_one_event(group, count);
mutex_unlock(&group->notification_mutex);
pr_debug("%s: group=%p kevent=%p\n", __func__, group, kevent);
if (kevent) {
ret = PTR_ERR(kevent);
if (IS_ERR(kevent))
break;
ret = copy_event_to_user(group, kevent, buf);
fsnotify_put_event(kevent);
if (ret < 0)
break;
buf += ret;
count -= ret;
continue;
}
ret = -EAGAIN;
if (file->f_flags & O_NONBLOCK)
break;
ret = -ERESTARTSYS;
if (signal_pending(current))
break;
if (start != buf)
break;
schedule();
}
finish_wait(&group->notification_waitq, &wait);
if (start != buf && ret != -EFAULT)
ret = buf - start;
return ret;
}
完全公平调度类
Completely Fair Scheduler(CFS)结构中是一系列的函数指针:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
// kernel/sched_fair.c
static const struct sched_class fair_sched_class = {
.next = &idle_sched_class,
.enqueue_task = enqueue_task_fair,
.dequeue_task = dequeue_task_fair,
.yield_task = yield_task_fair,
.check_preempt_curr = check_preempt_wakeup,
.pick_next_task = pick_next_task_fair,
.put_prev_task = put_prev_task_fair,
...
.set_curr_task = set_curr_task_fair,
.task_tick = task_tick_fair,
.task_new = task_new_fair,
};
主调度器的每个就绪队列中都嵌入了一个该 cfs_rq 结构的实例(每个 CPU 一个就绪队列)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
// kernel/sched.c
struct cfs_rq
{
// 所有这些进程的累积负荷值
struct load_weight load;
// 队列上可运行进程的数目
unsigned long nr_running;
// 跟踪记录队列上所有进程的最小虚拟运行时间
u64 min_vruntime;
// 用于在按时间排序的红黑树中管理所有进程
struct rb_root tasks_timeline;
// 保存指向树最左边的结点,即最需要被调度的进程,这样就不用每次遍历树了
struct rb_node *rb_leftmost;
// 指向当前执行进程的可调度实体
struct sched_entity *curr;
}
虚拟运行时间
关于为什么需要一个虚拟运行时间来描述进程:假设我们直接使用实际运行时间,也就是绝对物理时间,现实世界的 1 秒就是 1 秒,在调度进程时,我们可以选择实际运行时间最短的进程运行,来保证公平性。但是要怎么实现优先级的概念?如何知道拥有了优先级后的进程的饥饿情况?最终我们肯定需要通过优先级(或者权重)和实际运行时间进行换算得到进程的饥饿情况,也就有了虚拟运行时间的概念,这样调度进程时直接调度虚拟运行时间最短的进程就行(其实也可以称为相对运行时间。关于为什么需要一个变量单独保存就是为了空间换时间,虚拟运行时间可以通过权重和实际运行时间换算,只不过每次使用都换算一遍太浪费性能,能一次算完用一个变量保存最好,同时用作红黑树键值进行管理也更方便)。
所有与虚拟时钟有关的计算都在 update_curr 中执行,该函数在系统中各个不同地方调用,包括周期性调度器之内。

update_curr()实现了 CFS 策略所需信息(进程所占用的虚拟运行时间)的统计:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
// kernel/sched/fair.c
static void update_curr(struct cfs_rq *cfs_rq)
{
// 当前进程
struct sched_entity *curr = cfs_rq->curr;
// rq_of用于获取对应的rq实例
u64 now = rq_of(cfs_rq)->clock_task;
unsigned long delta_exec;
// 如果CFS队列上没有正在运行的进程,无需更新,
// 因为任何CFS管理的进程的vruntime不可能有变化
if (unlikely(!curr))
return;
/*
* Get the amount of time the current task was running
* since the last time we changed load (this cannot
* overflow on 32 bits):
*/
// 计算当前时间和上一次执行该函数时两次的时间差,
// 表示该进程本次执行时间,注意防止32位溢出
delta_exec = (unsigned long)(now - curr->exec_start);
if (!delta_exec)
return;
__update_curr(cfs_rq, curr, delta_exec);
curr->exec_start = now;
if (entity_is_task(curr)) {
struct task_struct *curtask = task_of(curr);
trace_sched_stat_runtime(curtask, delta_exec, curr->vruntime);
cpuacct_charge(curtask, delta_exec);
account_group_exec_runtime(curtask, delta_exec);
}
account_cfs_rq_runtime(cfs_rq, delta_exec);
}
此操作并不会更新红黑树,因为正在运行的进程并不在红黑树中,在其运行前就已经被移出红黑树了,所以仅更新该进程的统计量 vruntime 不影响红黑树的排序
其中__update_curr() 计算并更新当前进程在 CPU 上执行花费的物理运行时间和虚拟运行时间:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
// kernel/sched/fair.c
static inline void
__update_curr(struct cfs_rq *cfs_rq, struct sched_entity *curr, unsigned long delta_exec)
{
unsigned long delta_exec_weighted;
schedstat_set(curr->statistics.exec_max,
max((u64)delta_exec, curr->statistics.exec_max));
// 物理运行时间的更新比较简单,只要将时间差加到先前统计的时间即可
curr->sum_exec_runtime += delta_exec;
schedstat_add(cfs_rq, exec_clock, delta_exec);
// 对于nice=0的进程,定义其虚拟运行时间和物理运行时间相等(物理运行时间经过1s,
// 虚拟运行时间经过1s)
delta_exec_weighted = delta_exec;
// 对于nice!=0的进程([-20, +15]),NICE_0_LOAD是nice=0值映射到的负荷权重weight
if (unlikely(curr->load.weight != NICE_0_LOAD))
{
// 在使用不同的优先级时,必须根据进程的负荷权重重新衡定时间
delta_exec_weighted = calc_delta_fair(delta_exec_weighted, &curr->load);
}
// 更新总虚拟运行时间
curr->vruntime += delta_exec_weighted;
update_min_vruntime(cfs_rq);
}
static void update_min_vruntime(struct cfs_rq *cfs_rq)
{
u64 vruntime = cfs_rq->min_vruntime;
if (cfs_rq->curr)
vruntime = cfs_rq->curr->vruntime;
/** 跟踪红黑树中最左边的结点的vruntime,维护cfs_rq->min_vruntime的单调递增性 */
// 判断树中是否有最左节点,也就是等待调度的进程,rb_leftmost是最左节点缓存
if (cfs_rq->rb_leftmost) {
// 如果存在,获取该节点对应的进程的调度实体sched_entity
struct sched_entity *se = rb_entry(cfs_rq->rb_leftmost,
struct sched_entity,
run_node);
if (!cfs_rq->curr)
vruntime = se->vruntime;
else
vruntime = min_vruntime(vruntime, se->vruntime);
}
/* ensure we never gain time by being placed backwards. */
// 更新队列上进程的最小虚拟运行时间,取较大值用于保证min_vruntime单调递增(只增加不减少)
cfs_rq->min_vruntime = max_vruntime(cfs_rq->min_vruntime, vruntime);
#ifndef CONFIG_64BIT
smp_wmb();
cfs_rq->min_vruntime_copy = cfs_rq->min_vruntime;
#endif
}
虚拟运行时间计算
__update_curr() 中的 calc_delta_fair() 函数作用是根据物理运行时间计算虚拟运行时间,公式如下:
负荷权重 weight 的计算方式见计算负荷权重,权重和优先级值成反比(和优先级成正比),权重 weight越大,进程的虚拟运行时间 vruntime越小(也就是走的越慢),这样就能占用更多的物理 CPU 时间(优先级越高)。
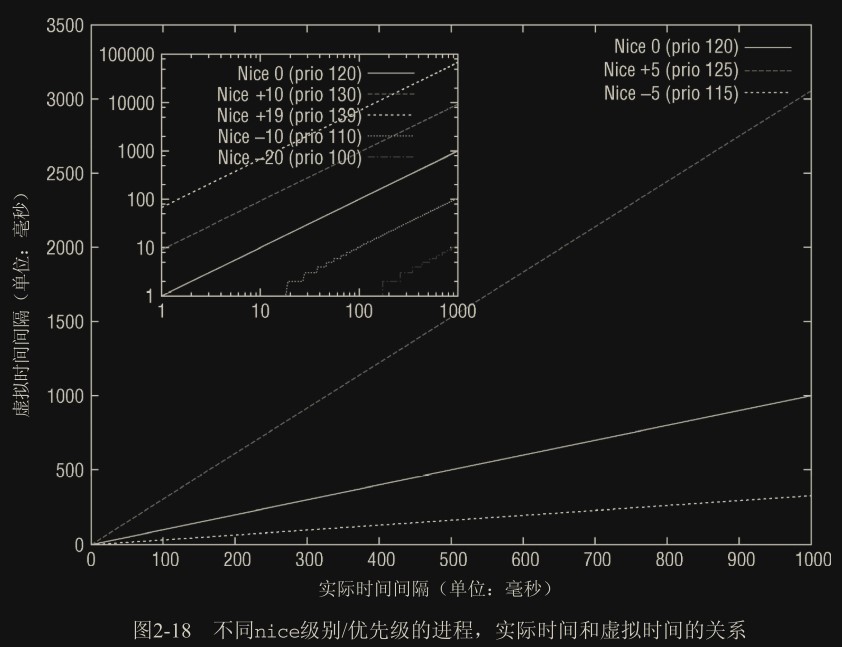
红黑树
完全公平调度器类(CFS)使用红黑树来组织可运行进程队列。排序依据(键值)为 vruntime。键值较小的结点,排序位置就更靠左,因此会被更快地调度。用这种方法,内核实现了下面两种对立的机制:
- 在进程运行时,其
vruntime稳定地增加,它在红黑树中总是向右移动的。 因为越重要的进程 vruntime 增加越慢,因此它们向右移动的速度也越慢,这样其被调度的机会要大于次要进程,这刚好是我们需要的。 - 如果进程进入睡眠,则其
vruntime保持不变。因为每个队列min_vruntime同时会增加(根据上面的代码,它是单调递增的),那么睡眠进程醒来后,在红黑树中的位置会更靠左,因为其键值变得更小了。
查找树中最左边的节点,也就是键值最小的节点,表示最应该被调度的进程实体:
1
2
3
4
5
6
7
8
9
struct sched_entity *__pick_first_entity(struct cfs_rq *cfs_rq)
{
struct rb_node *left = cfs_rq->rb_leftmost;
if (!left)
return NULL;
return rb_entry(left, struct sched_entity, run_node);
}
向树中加入一个节点,也就是进程加入就绪队列(发生在进程变为可运行状态(被唤醒)或者是通过fork()调用第一次创建进程时):
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
static void
enqueue_entity(struct cfs_rq *cfs_rq, struct sched_entity *se, int flags)
{
/*
* Update the normalized vruntime before updating min_vruntime
* through callig update_curr().
*/
// 如果是新创建的进程(不是被唤醒WAKEUP的进程)
if (!(flags & ENQUEUE_WAKEUP) || (flags & ENQUEUE_WAKING))
/*
* cfs_rq->min_vruntime可以表示当前队列已运行的虚拟运行时间,
* 后续新加入的进程在该时间的基础上运行,也就是vruntime需要加上
* 这个已经经过的虚拟时间。
*
* 否则该进程的vruntime可能就以0开始,这对其他已经在队列中的进程不公平
*/
se->vruntime += cfs_rq->min_vruntime;
/*
* Update run-time statistics of the 'current'.
*/
update_curr(cfs_rq);
enqueue_entity_load_avg(cfs_rq, se, flags & ENQUEUE_WAKEUP);
account_entity_enqueue(cfs_rq, se);
update_cfs_shares(cfs_rq);
if (flags & ENQUEUE_WAKEUP) {
place_entity(cfs_rq, se, 0);
enqueue_sleeper(cfs_rq, se);
}
update_stats_enqueue(cfs_rq, se);
check_spread(cfs_rq, se);
if (se != cfs_rq->curr)
// 把一个调度实体插入红黑树中
__enqueue_entity(cfs_rq, se);
se->on_rq = 1;
if (cfs_rq->nr_running == 1) {
list_add_leaf_cfs_rq(cfs_rq);
check_enqueue_throttle(cfs_rq);
}
}
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
static void __enqueue_entity(struct cfs_rq *cfs_rq, struct sched_entity *se)
{
// 获取树的根节点
struct rb_node **link = &cfs_rq->tasks_timeline.rb_node;
struct rb_node *parent = NULL;
struct sched_entity *entry;
int leftmost = 1;
/*
* Find the right place in the rbtree:
*/
// 从根开始遍历红黑树节点
while (*link) {
parent = *link;
// 获取节点对象(sched_entity对象)
entry = rb_entry(parent, struct sched_entity, run_node);
/*
* We dont care about collisions. Nodes with
* the same key stay together.
*/
// 如果新节点在该节点的左边(key值小于该节点)
if (entity_before(se, entry)) {
// 遍历左子树
link = &parent->rb_left;
} else {
// 遍历右子树
link = &parent->rb_right;
// 因为一旦开始遍历右子树,表示新节点已经不可能是树中最左边的节点了,
// 我们将leftmost标志置为0
leftmost = 0;
}
}
/*
* Maintain a cache of leftmost tree entries (it is frequently
* used):
*/
// 如果新节点为最左节点,那可以直接缓存它,以后获取树的最左子节点直接用这个缓存
if (leftmost)
cfs_rq->rb_leftmost = &se->run_node;
rb_link_node(&se->run_node, parent, link);
// 树的自平衡(红黑着色)操作
rb_insert_color(&se->run_node, &cfs_rq->tasks_timeline);
}
当进程切换时,schedule()会调用deactivate_task()将当前进程从对应的调度器类(比如这里是 CFS)的队列中移除(这里就是从红黑树中删除节点)
延迟跟踪
上面的虚拟运行时间保证的进程分到的 CPU 时间的公平性,但不能保证进程的执行间隔(及时性),可能分到了 10ms,但是执行时一次执行了 10ms,后面的 1s 都没有执行机会,对用户来说就是无响应状态。所以需要细分一个执行周期,保证周期内所有进程都至少执行一次,哪怕执行的时间很短,也能保证及时性。但是也不能过于频繁的切换进程,这会影响效率,后续会提到通过 sysctl_sched_wakeup_granularity 来限制进程切换速度。
通过延迟跟踪来保证进程执行的及时性:
sysctl_sched_latency:延迟周期。保证每个可运行的进程都应该至少运行一次的某个时间间隔。可通过/proc/sys/kernel/sched_latency_ns控制,默认值为 20000000 纳秒或 20 毫秒。这个时间是物理运行时间sched_nr_latency:控制在一个延迟周期中处理的最大活动进程数目。如果活动进程的数目超出该上限,则延迟周期也成比例地线性扩展。
通过考虑各个进程的相对权重,将一个延迟周期的时间在活动进程之间进行分配。
对于由某个可调度实体表示的给定进程,一个延迟周期内分配到的物理运行时间如下计算:
1
2
3
4
5
6
7
8
9
10
// kernel/sched_fair.c
static u64 sched_slice(struct cfs_rq *cfs_rq, struct sched_entity *se)
{
// __sched_period用于计算sysctl_sched_latency,也就是延迟周期
u64 slice = __sched_period(cfs_rq->nr_running);
// 计算物理运行时间比重,进程的负荷权重先乘以延迟周期,再除以总负荷权重。计算得到占用延迟周期内物理运行时间
slice *= se->load.weight;
do_div(slice, cfs_rq->load.weight);
return slice;
}
$ time \times \frac{Nice0Load}{weight} $ 用于计算一个延迟周期内分配到的虚拟运行时间,上文有提到计算负荷权重:
1
2
3
4
5
6
7
8
9
10
11
12
// kernel/sched_fair.c
static u64 __sched_vslice(unsigned long rq_weight, unsigned long nr_running)
{
u64 vslice = __sched_period(nr_running);
vslice *= NICE_0_LOAD;
do_div(vslice, rq_weight);
return vslice;
}
static u64 sched_vslice(struct cfs_rq *cfs_rq)
{
return __sched_vslice(cfs_rq->load.weight, cfs_rq->nr_running);
}
队列操作
进程加入就绪队列
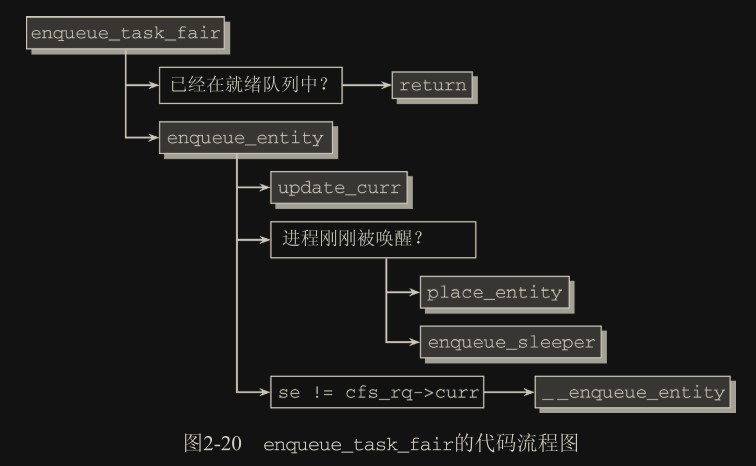
用于被唤醒的进程和新创建的进程,通过参数 wakeup 标识。
如果进程此前在睡眠,那么在 place_entity 中首先会调整进程的虚拟运行时间(新进程的加入会导致队列的总权重上升,让其中原有的每个进程权重的占比略微降低,也就是会降低每个进程在一个延迟周期内的运行时间,为了不干扰本轮延迟周期,本函数会进行一些操作修正 vruntime):
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
// kernel/sched/fair.c
static void
place_entity(struct cfs_rq *cfs_rq, struct sched_entity *se, int initial)
{
// 读取队列当前最小vruntime
u64 vruntime = cfs_rq->min_vruntime;
/*
* The 'current' period is already promised to the current tasks,
* however the extra weight of the new task will slow them down a
* little, place the new task so that it fits in the slot that
* stays open at the end.
*/
// 如果是新进程
if (initial && sched_feat(START_DEBIT))
/*
* 让该进程的虚拟运行时间加上本周期内允许运行的虚拟时间,
* 相当于这个新进程用完了当前延迟周期内分配到的所有时间,只能等待下次延迟周期,
* 从而不会影响本次周期
*/
vruntime += sched_vslice(cfs_rq, se);
/* sleeps up to a single latency don't count. */
// 如果不是新进程,也就是刚被唤醒的休眠进程
if (!initial) {
unsigned long thresh = sysctl_sched_latency;
/*
* Halve their sleep time's effect, to allow
* for a gentler effect of sleepers:
*/
/*
* 如果GENTLE_FAIR_SLEEPERS标志置位,表示启用
* 限制睡眠线程的补偿时间为sysctl_sched_latency的50%,
* 可以减少其他任务的调度延迟,该功能内核默认打开。
* 否则按延迟周期100%补偿该进程因休眠损失的CPU时间。
* 老版本的内核没有该特性,都是100%补偿的。
*/
if (sched_feat(GENTLE_FAIR_SLEEPERS))
thresh >>= 1;
/*
* 在当前周期补偿该进程因休眠损失的CPU时间,
* 通过这样让cfs_rq->min_vruntime减去sysctl_sched_latency周期,
* vruntime就落后于当前队列运行时间,直到其运行时间达到cfs_rq->min_vruntime,
* 才能消除该补偿。
*/
vruntime -= thresh;
}
/* ensure we never gain time by being placed backwards. */
// 确保se->vruntime不会小于vruntime,让该进程适用place_entity的修正,
// 当然,如果se->vruntime本身就大于vruntime说明该进程之前已经占用了过量的CPU时间,不需要修正,无需操作
se->vruntime = max_vruntime(se->vruntime, vruntime);
}
之后通过__enqueue_entity将该修正 vruntime 后的节点加入红黑树中
选择下一个进程
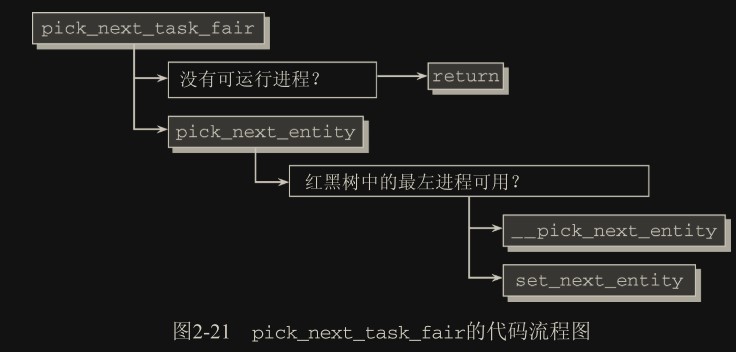
红黑树只包含就绪且未在实际运行中的进程,进程运行前需要从红黑树中去除。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
// kernel/sched/fair.c
static struct task_struct *pick_next_task_fair(struct rq *rq)
{
struct task_struct *p;
struct cfs_rq *cfs_rq = &rq->cfs;
struct sched_entity *se;
// 当前队列上没有可运行进程
if (!cfs_rq->nr_running)
return NULL;
do {
// 寻找红黑树最左节点
se = pick_next_entity(cfs_rq);
// 配置该节点
set_next_entity(cfs_rq, se);
cfs_rq = group_cfs_rq(se);
} while (cfs_rq);
p = task_of(se);
if (hrtick_enabled(rq))
hrtick_start_fair(rq, p);
return p;
}
static void
set_next_entity(struct cfs_rq *cfs_rq, struct sched_entity *se)
{
/* 'current' is not kept within the tree. */
if (se->on_rq) {
/*
* Any task has to be enqueued before it get to execute on
* a CPU. So account for the time it spent waiting on the
* runqueue.
*/
update_stats_wait_end(cfs_rq, se);
/*
* 进程在运行过程中(作为curr)不放在红黑树中,
* 这样更新该进程的vruntime就无需每次都更新红黑树
*/
__dequeue_entity(cfs_rq, se);
}
update_stats_curr_start(cfs_rq, se);
cfs_rq->curr = se;
#ifdef CONFIG_SCHEDSTATS
/*
* Track our maximum slice length, if the CPU's load is at
* least twice that of our own weight (i.e. dont track it
* when there are only lesser-weight tasks around):
*/
if (rq_of(cfs_rq)->load.weight >= 2*se->load.weight) {
se->statistics.slice_max = max(se->statistics.slice_max,
se->sum_exec_runtime - se->prev_sum_exec_runtime);
}
#endif
se->prev_sum_exec_runtime = se->sum_exec_runtime;
}
进程暂停
schedule()通过put_prev_task钩子函数让进程暂停,此时该进程得以重回红黑树,并在接下来调度下一个新的进程:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
// kernel/sched/fair.c
static void put_prev_task_fair(struct rq *rq, struct task_struct *prev)
{
struct sched_entity *se = &prev->se;
struct cfs_rq *cfs_rq;
for_each_sched_entity(se) {
cfs_rq = cfs_rq_of(se);
put_prev_entity(cfs_rq, se);
}
}
static void put_prev_entity(struct cfs_rq *cfs_rq, struct sched_entity *prev)
{
/*
* If still on the runqueue then deactivate_task()
* was not called and update_curr() has to be done:
*/
if (prev->on_rq)
// 运行结束前最后再更新一次统计量(vruntime)
update_curr(cfs_rq);
/* throttle cfs_rqs exceeding runtime */
check_cfs_rq_runtime(cfs_rq);
check_spread(cfs_rq, prev);
if (prev->on_rq) {
update_stats_wait_start(cfs_rq, prev);
/* Put 'current' back into the tree. */
// 进程暂停前将其放回红黑树中
__enqueue_entity(cfs_rq, prev);
/* in !on_rq case, update occurred at dequeue */
update_entity_load_avg(prev, 1);
}
cfs_rq->curr = NULL;
}
CFS 周期性调度函数
该函数是周期性调度器使用的钩子函数.task_tick = task_tick_fair中的一部分
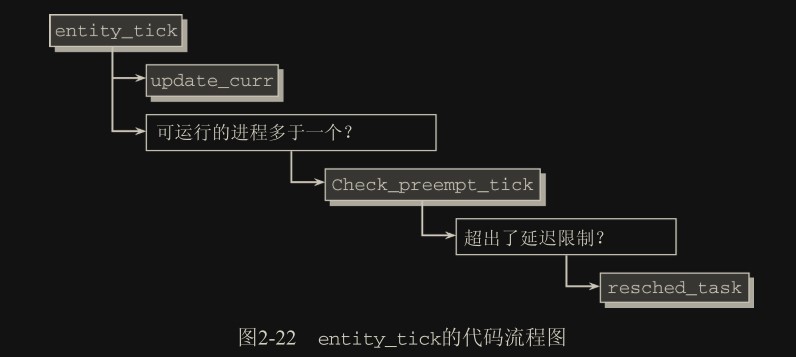
nr_running=1 时表示可运行进程就 1 个,有两种情况:
- 正在运行的进程 1 个,就绪队列为空
- 正在运行的进程 0 个,就绪队列中有 1 个进程
以上两种情况都无需做任何操作,因为本函数的目的是进行进程的切换,只有一个无法实现切换。
如果进程数目大于等于两个,则由 check_preempt_tick 作出决策:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
// kernel/sched_fair.c
static void
check_preempt_tick(struct cfs_rq *cfs_rq, struct sched_entity *curr)
{
unsigned long ideal_runtime, delta_exec;
// 当前进程允许的物理执行时间
ideal_runtime = sched_slice(cfs_rq, curr);
// 当前进程的本次物理执行时间
delta_exec = curr->sum_exec_runtime - curr->prev_sum_exec_runtime;
// 如果超出了允许的时间
if (delta_exec > ideal_runtime)
// 进行一次重调度。
// 这会在task_struct中设置TIF_NEED_RESCHED标志,主调度器会在下一个适当时机发起重调度。
resched_task(rq_of(cfs_rq)->curr);
}
这会在 task_struct 中设置 TIF_NEED_RESCHED 标志,主调度器会在下一个适当时机发起重调度。
唤醒抢占
当在 try_to_wake_up 和 wake_up_new_task 中唤醒进程时,内核使用 check_preempt_curr 看看是否新进程可以抢占当前运行的进程。
内核会根据当前正在运行的进程所属的调度器类定义的钩子函数 check_preempt_curr,完全公平调度器类 fair_sched_class 中的 check_preempt_curr 指向 check_preempt_wakeup 函数:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
// kernel/sched_fair.c
// p为刚唤醒的进程
static void check_preempt_wakeup(struct rq *rq, struct task_struct *p)
{
struct task_struct *curr = rq->curr;
struct cfs_rq *cfs_rq = task_cfs_rq(curr);
// 当前进程的sched_entity
struct sched_entity *se = &curr->se, *pse = &p->se;
unsigned long gran;
// 刚唤醒的进程是否是实时进程,(除了此处与实时进程有关联外,其他地方都没有)
if (unlikely(rt_prio(p->prio)))
{
// 让当前的普通进程(非实时进程都使用完全公平调度器类)停止运行
update_rq_clock(rq);
update_curr(cfs_rq);
resched_task(curr);
// 直接 return 无需后续步骤
return;
}
...
// 如果是SCHED_BATCH进程,根据定义它们不抢占其他进程
if (unlikely(p->policy == SCHED_BATCH))
return;
...
// 当运行进程被新进程(非上面已判断的进程类型)抢占时,
// 内核确保被抢占者至少已经运行了某一最小时间限额sysctl_sched_wakeup_granularity(注意是虚拟运行时间)。
// sysctl_sched_wakeup_granularity一般为4ms,防止过于频繁的抢占产生大量上下文切换
gran = sysctl_sched_wakeup_granularity;
if (unlikely(se->load.weight != NICE_0_LOAD))
// 根据物理运行时间计算虚拟运行时间
gran = calc_delta_fair(gran, &se->load);
...
if (pse->vruntime + gran < se->vruntime)
// TIF_NEED_RESCHED置位
resched_task(curr);
}
处理新进程
创建新进程fork()时调用的挂钩函数:task_new_fair(挂钩于 task_new)。该函数的行为可使用参数 sysctl_sched_child_runs_first 控制(默认为 1,也就是默认启用)。顾名思义,该参数用于判断新建子进程是否应该在父进程之前运行。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
// kernel/sched_fair.c
static void task_new_fair(struct rq *rq, struct task_struct *p)
{
struct cfs_rq *cfs_rq = task_cfs_rq(p);
struct sched_entity *se = &p->se, *curr = cfs_rq->curr;
int this_cpu = smp_processor_id();
update_curr(cfs_rq);
// 队列操作,见上文
place_entity(cfs_rq, se, 1);
...
// 如果父进程(curr)的vruntime小于子进程的vruntime,意味着父进程将先于子进程执行
if (sysctl_sched_child_runs_first && curr->vruntime < se->vruntime)
{
// 如果不允许该情况,则需要交换两者的值
swap(curr->vruntime, se->vruntime);
}
// 子进程加入就绪队列(完全公平调度器类的队列)
enqueue_task_fair(rq, p, 0);
// 重新调度,让子进程得以执行
resched_task(rq->curr);
}
实时调度器类
按照 POSIX 标准的强制要求,除了“普通”进程之外,Linux 还支持两种实时调度器类。
性质
实时进程与普通进程有一个根本的不同之处:如果系统中有一个实时进程且可运行,那么调度器总是会选中它运行,除非有另一个优先级更高的实时进程。
两种实时类:
- 循环进程(SCHED_RR):有时间片,其值在进程运行时会减少,就像是普通进程。在所有的时间段都到期后,则该值重置为初始值,而进程则置于队列的末尾。这确保了在有几个优先级相同的 SCHED_RR 进程的情况下,它们总是依次执行。
- 先进先出进程(SCHED_FIFO):没有时间片,在被调度器选择执行后,可以运行任意长时间。 很明显,如果实时进程编写得比较差,系统可能变得无法使用。只要写一个无限循环,循环体内不进入睡眠,其他进程就别想运行了。在编写实时应用程序时,应该多加小心。
实时调度器类定义:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
// kernel/sched-rt.c
const struct sched_class rt_sched_class = {
.next = &fair_sched_class,
.enqueue_task = enqueue_task_rt,
.dequeue_task = dequeue_task_rt,
.yield_task = yield_task_rt,
.check_preempt_curr = check_preempt_curr_rt,
.pick_next_task = pick_next_task_rt,
.put_prev_task = put_prev_task_rt,
#ifdef CONFIG_SMP
.select_task_rq = select_task_rq_rt,
.set_cpus_allowed = set_cpus_allowed_rt,
.rq_online = rq_online_rt,
.rq_offline = rq_offline_rt,
.pre_schedule = pre_schedule_rt,
.post_schedule = post_schedule_rt,
.task_woken = task_woken_rt,
.switched_from = switched_from_rt,
#endif
.set_curr_task = set_curr_task_rt,
.task_tick = task_tick_rt,
.get_rr_interval = get_rr_interval_rt,
.prio_changed = prio_changed_rt,
.switched_to = switched_to_rt,
};
实时调度器类的实现比完全公平调度器简单。大约只需要 250 行代码,而 CFS 则需要 1100 行!
就绪队列数据结构:
1
2
3
4
5
6
7
8
9
10
// kernel/sched.c
struct rt_prio_array
{
DECLARE_BITMAP(bitmap, MAX_RT_PRIO + 1); /* 包含1比特用于间隔符 */
struct list_head queue[MAX_RT_PRIO];
};
struct rt_rq
{
struct rt_prio_array active;
};
具有相同优先级的所有实时进程都保存在一个链表中,表头为 active.queue[prio],
active.bitmap 位图中的每个比特位对应于一个链表,凡包含了进程的链表,对应的比特位则置位。如果链表中没有进程,则对应的比特位不置位。(用于快速判断对应链表是否为空)
亮点:链表与位图的组合,很适合优先级相关应用,此处用于快速判断有效的最高优先级链表
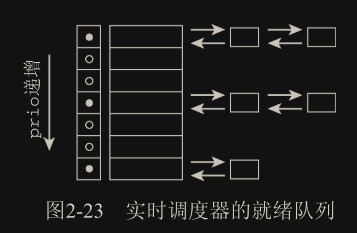
调度器类操作
插入新进程
通过优先级作为 index 可获取对应链表,新进程总是排列在每个链表的末尾。
选择下一个执行的进程

sched_find_first_bit 是一个标准函数,可以找到 active.bitmap 中第一个置位的比特位,这意味着高的实时优先级(对应于较低的内核优先级值),取出所选链表的第一个进程,并将 se.exec_start 设置为就绪队列的当前实际时钟值
实时周期性调度函数
和CFS 周期性调度函数相同,在每个时钟中断中由周期性调度器选择对应的调度器类中的周期调用函数(curr->sched_class->task_tick)执行
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
// kernel/sched.c
static void task_tick_rt(struct rq *rq, struct task_struct *p)
{
update_curr_rt(rq);
/*
* 循环进程需要一种特殊形式的时间片管理。
* 先进先出进程没有时间片。
*/
// 如果是FIFO
if (p->policy != SCHED_RR)
// 不做操作
return;
...
// 如果未超出时间片,减少时间片
if (--p->time_slice)
// 其他什么也不做,不做切换
return;
// 如果时间片不足
// 重置时间片
p->time_slice = DEF_TIMESLICE;
/*
* 如果不是队列上的唯一成员,则重新排队到末尾。
*/
if (p->run_list.prev != p->run_list.next)
{
requeue_task_rt(rq, p);
// 通过用set_tsk_need_resched设置TIF_NEED_RESCHED标志,照常请求重调度
// TODO:可以研究下resched_task()
set_tsk_need_resched(p);
}
}
与调度相关的系统调用
Linux 提供了一个系统调用族,用于管理与调度程序相关的参数。这些系统调用可以用来操作和处理进程优先级、调度策略及处理器绑定,同时还提供了显式地将处理器交给其他进程的机制
| 系统调用 | 描述 |
|---|---|
| nice() | 设置进程的 nice 值 |
| sched_setscheduler() | 设置进程的调度策略(policy) |
| sched_getscheduler() | 获取进程的调度策略 |
| sched_setparam() | 设置进程的实时优先级(rt_priority) |
| sched_getparam() | 获取进程的实时优先级 |
| sched_get_priority_max() | 获取实时优先级的最大值 |
| sched_get_priority_min() | 获取实时优先级的最小值 |
| sched_r_get_interval() | 获取进程的时间片值 |
| sched_setaffinity() | 设置进程的处理器的亲和力 |
| sched_getaffinity() | 获取进程的处理器的亲和力 |
| sched_yield() | 暂时让出处理器 |
CPU 亲和力:Linux 调度程序提供强制的处理器绑定(processor affinity)机制,称为进程的 CPU 亲和力,保存在进程 task_struct 的 cpus_allowed 这个位掩码标志中。该掩码标志的每一位对应一个系统可用的处理器。默认情况下,所有的位都被设置,进程可以在系统中所有可用的处理器上执行。
调度器增强
SMP 调度
为了高效利用 CPU,内核需要支持以下功能:
- CPU 负载均衡,不要出现 1 核有难,7 核围观。
- CPU 亲和性设置,例如在 4 个 CPU 系统中,可以将计算密集型应用程序绑定到前 3 个 CPU,而剩余的(交互式)进程则在第 4 个 CPU 上运行。
- 进程能在 CPU 间移动,但要考虑高速缓存切换和内存移动带来的代价。
数据结构:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
// kernel/sched/sched.h
struct rq {
...
#ifdef CONFIG_SMP
struct root_domain *rd;
struct sched_domain *sd;
unsigned long cpu_power;
unsigned char idle_balance;
/* For active balancing */
int post_schedule;
int active_balance;
int push_cpu;
struct cpu_stop_work active_balance_work;
/* cpu of this runqueue: */
int cpu;
int online;
struct list_head cfs_tasks;
u64 rt_avg;
u64 age_stamp;
u64 idle_stamp;
u64 avg_idle;
#endif
...
};
和 SMP 调度相关的变量部分在就绪队列结构 rq 中
负载均衡流程
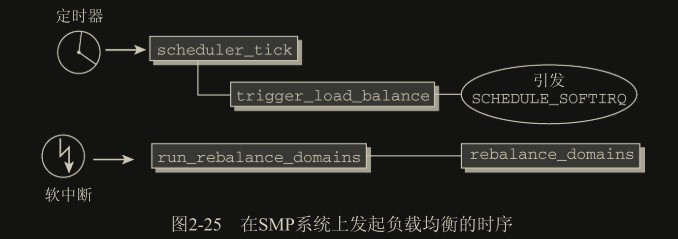
在周期性调度器中,会触发trigger_load_balance(),并使用软中断SCHED_SOFTIRQ来延后执行负载均衡:
1
2
3
4
5
6
7
8
9
10
11
12
// kernel/sched/fair.c
void trigger_load_balance(struct rq *rq, int cpu)
{
/* Don't need to rebalance while attached to NULL domain */
if (time_after_eq(jiffies, rq->next_balance) &&
likely(!on_null_domain(cpu)))
raise_softirq(SCHED_SOFTIRQ);
#ifdef CONFIG_NO_HZ_COMMON
if (nohz_kick_needed(rq, cpu) && likely(!on_null_domain(cpu)))
nohz_balancer_kick(cpu);
#endif
}
软中断SCHED_SOFTIRQ绑定的中断处理程序为run_rebalance_domains():
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
// kernel/sched/fair.c
static void run_rebalance_domains(struct softirq_action *h)
{
int this_cpu = smp_processor_id();
struct rq *this_rq = cpu_rq(this_cpu);
enum cpu_idle_type idle = this_rq->idle_balance ?
CPU_IDLE : CPU_NOT_IDLE;
rebalance_domains(this_cpu, idle);
/*
* If this cpu has a pending nohz_balance_kick, then do the
* balancing on behalf of the other idle cpus whose ticks are
* stopped.
*/
nohz_idle_balance(this_cpu, idle);
}
CPU 较多的情况下可以选择将物理上相邻的 CPU 的就绪队列组织为调度域(scheduling domain),从而划分为多个调度域,在同一调度域间搬迁进程消耗较少。不过一般非大型的系统上用不上该特性,所有 CPU 都在一个调度域内。
对于rebalance_domains()的具体调度算法,这里不再展开。
内核抢占
在 2.5 版本之前,内核在内核空间中的操作不会被“暂停”,比如进程使用系统调用陷入内核空间后会执行完整个系统调用操作,即使耗时很长。即使中断打断了该系统调用,中断返回后该系统调用也继续运行,不触发调度。
linux kernel 2.4(不支持内核抢占):
橙色和紫色是两个不同的进程,紫色触发了 read()系统调用,进入内核空间,此时发生中断,中断处理完毕后返回内核空间继续执行,因为处于内核空间,在 2.4 中无法触发调度。
Linux 2.6 内核引入了完全抢占式内核(Fully Preemptible Kernel)的支持,它实现了内核抢占的特性,即使是在执行系统调用,也可被抢占调度。
linux kernel 2.6(支持内核抢占):
在 2.6 中,即使是在内核空间,只要preempt_count为 0 表明可以抢占,就可以直接触发调度切换到其他的高优先级进程。
内核抢占的实现
在 task_struct 的 thread_info 结构中,有一个抢占计数器 preempt_count:
1
2
3
4
5
6
// <asm-arch/thread_info.h>
struct thread_info {
...
int preempt_count; /* 0 => 可抢占,>0 => 不可抢占, <0 => BUG */
...
}
preempt_count 确定了内核当前是否处于一个可以被抢占的位置。如果 preempt_count 为零,则内核可以被抢占,否则不行。比如处于临界区时内核是不希望自己被抢占的,可以通过preempt_disable暂时停用内核抢占。
preempt_count 是一个 int 而不是 bool 类型的值,表示对内核抢占的开关可以嵌套,多次增加 preempt_count 关闭内核抢占后,必须递减同样次数的 preempt_count,才能再次启用内核抢占。
preempt_count 操作相关的函数:
- preempt_disable:通过调用
inc_preempt_count增加计数来停用抢占。此外,会指示编译器避免某些内存优化,以免导致某些与抢占机制相关的问题。 - preempt_check_resched:会检测是否有必要进行调度,如有必要则进行。
- preempt_enable:启用内核抢占,然后立即用 preempt_check_resched 检测是否有必要重调度。
- preempt_enable_no_resched:启用内核抢占,但不进行重调度。实际操作是调用
dec_preempt_count()为 preempt_count 加 1。
抢占的实际操作就是调用主调度器__schedule()函数触发一次调度。
在开启抢占式调度(CONFIG_PREEMPT)的情况下,preempt_schedule_context()会在合适的时机执行,此时会检测当前进程是否需要被调度(TIF_NEED_RESCHED 标志),然后执行preempt_schedule():
1
2
3
4
5
6
// include/linux/preempt.h
#define preempt_check_resched() \
do { \
if (unlikely(test_thread_flag(TIF_NEED_RESCHED))) \
preempt_schedule(); \
} while (0)
在 preempt_schedule() 中,判断当前是否允许内核抢占(preempt_count 是否为 0)或是否停用了中断(irqs_disabled()),如果允许,则调用主调度器函数__schedule()触发调度:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
asmlinkage void __sched notrace preempt_schedule(void)
{
struct thread_info *ti = current_thread_info();
/*
* If there is a non-zero preempt_count or interrupts are disabled,
* we do not want to preempt the current task. Just return..
*/
if (likely(ti->preempt_count || irqs_disabled()))
return;
do {
/*
* 触发调度前首先将preempt_count加上极大值PREEMPT_ACTIVE
* 保证关闭内核抢占,防止嵌套。同时该标志用于schedule()中
* 对是否是由抢占触发的情况做判断。
*/
add_preempt_count_notrace(PREEMPT_ACTIVE);
__schedule();
// 调度结束回来时要把临时加的PREEMPT_ACTIVE减掉
sub_preempt_count_notrace(PREEMPT_ACTIVE);
/*
* Check again in case we missed a preemption opportunity
* between schedule and now.
*/
barrier();
// 每次循环判断一次TIF_NEED_RESCHED标记,如果依然需要调度,则再次执行不返回
} while (need_resched());
}
内核抢占的触发时机
内核抢占被重新激活时,也就是
preempt_enable()被调用时,会调用preempt_check_resched()进行调度(如果条件满足)1 2 3 4 5 6
#define preempt_enable() \ do { \ preempt_enable_no_resched(); \ barrier(); \ preempt_check_resched(); \ } while (0)在处理了一个硬件中断请求之后。如果处理器在处理中断请求后返回核心态(返回用户态不属于内核抢占讨论的范畴),特定于体系结构的汇编例程会检查抢占计数器值是否为 0(是否允许抢占),以及是否设置了重调度标志,然后调用
__schedule()